hadoop温度排序
- 计算1949-1955年,每年温度最高的时间
- 思路分析
①Mapper,按照年份升序排序,同时每年的温度降序
②Reduce,按照年份分组, 每年对应一个reduce任务
- Hadoop中如何自定义排序,自定义分区,自定义分组。
- --需求:
- 1.计算在1949-1955年,每年温度最高的时间
- 2.计算在1949-1955年,每年温度最高前十天
- --思路:
- 1.按照年份升序,同时每一年中温度降序排序
- 2.按照年份分组,每一年对应一个reduce任务
- mapper输出,key为封装对象。
- --目的:
- 自定义排序
- 自定义分区
- 自定义分组
- --输入数据
- 1949-10-01 14:21:02 34°C
- 1949-10-02 14:01:02 36°C
- 1950-01-01 11:21:02 32°C
- 1950-19-01 12:21:02 37°C
- 1951-12-01 12:21:02 23°C
- 1950-10-02 12:21:02 41°C
- 1950-10-03 12:21:02 27°C
- 1951-07-01 12:21:02 45°C
- 1951-07-02 12:21:02 46°C
- --时间和温度之间是制表符\t
- --需求:1
- --中间数据
- 1949-10-02 14:01:02 36°C
- 1950-19-01 12:21:02 37°C
- 1951-07-02 12:21:02 46°C
- --目标数据
- 1949 36
- 1950 37
- 1951 46
- --需求:2
- --先分组,后降序
- 1949 36 1949-10-02 14:01:02 36°C
- 1949 34 1949-10-01 14:21:02 34°C
- 1950 41 1950-10-02 12:21:02 41°C
- 1950 37 1950-19-01 12:21:02 37°C
- 1950 32 1950-01-01 11:21:02 32°C
- 1950 27 1950-10-03 12:21:02 27°C
- 1951 46 1951-07-02 12:21:02 46°C
- 1951 45 1951-07-01 12:21:02 45°C
- 1951 23 1951-12-01 12:21:02 23°C
- 1949-10-01 14:21:02 34°C-->(1949,34)-->49,50,51(分组)-->温度排序-->
KeyPair
Mapping:key即是自定义封装类对象
自定义封装类:类要实现WritableComparable接口,重写readFields,write,compareTo三个方法,重写hasCode和toString方法.
自定义封装类:类要实现WritableComparable接口,重写readFields,write,compareTo三个方法,重写hasCode和toString方法.
package com.selflearn.hot;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @author Robin
*
* Writable接口,作为所有可序列化对象必须实现的接口
* 在Hadoop中定义一个结构化对象都要实现Writable接口,使得该结构化对象可以序列化为字节流,字节流也可以反序列化为结构化对象。
* WritableComparable接口是可序列化并且可比较的接口。MapReduce中所有的key值类型都必须实现这个接口
* 既然是可序列化的那就必须得实现readFiels()和write()这两个序列化和反序列化函数
* 既然也是可比较的那就必须得实现compareTo()函数
* 这样MR中的key值就既能可序列化又是可比较的
*
* 自定义map输出的key类型,必须实现WritableComparable
*/
public class KeyPair implements WritableComparable {
/**
* 年份
*/
private int year;
/**
* 温度
*/
private int hot;
/**
* 数据的反序列化
*/
@Override
public void readFields(DataInput in) throws IOException {
this.year = in.readInt();
this.hot = in.readInt();
}
/**
* 数据的序列化
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.year);
out.writeInt(this.hot);
}
/**
* 先按年份升序排序
* 再按温度降序排序
*/
@Override
public int compareTo(KeyPair o) {
int res = Integer.compare(this.year, o.getYear());
if (res != 0) {
return res;
}
return Integer.compare(this.hot, o.getHot());
}
@Override
public int hashCode() {
return new Integer(this.year + this.hot).hashCode();
}
@Override
public String toString() {
return this.year + " " + this.hot;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getHot() {
return hot;
}
public void setHot(int hot) {
this.hot = hot;
}
}
package com.selflearn.hot;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 按年份分区
*/
public class FirstPartition extends Partitioner{
/**
* 按年份分区
* @param num reduce的数量
*/
@Override
public int getPartition(KeyPair key, Text value, int num) {
return key.getYear() * 127 % num;
}
}
排序
package com.selflearn.hot;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* 排序
* 按年份升序排序,同时按年份降序排序
*/
public class SortHot extends WritableComparator {
public SortHot() {
super(KeyPair.class, true);
}
/**
* 按年份升序排序,
* 同时按年份降序排序
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
KeyPair o1 = (KeyPair) a;
KeyPair o2 = (KeyPair) b;
int res = Integer.compare(o1.getYear(), o2.getYear());
if (res != 0) {
return res;
}
// 降序排序
return -Integer.compare(o1.getHot(), o2.getHot());
}
}
分组
package com.selflearn.hot;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* 按年分组
*/
public class GroupHot extends WritableComparator {
public GroupHot() {
super(KeyPair.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
KeyPair o1 = (KeyPair) a;
KeyPair o2 = (KeyPair) b;
return Integer.compare(o1.getYear(), o2.getYear());
}
}
package com.selflearn.hot;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static class HotMapper extends Mapper {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] str = line.split("\t");
if (str.length == 2) {
System.out.println(str.length);
System.out.println(str[0]);
System.out.println(str[1]);
Date date;
try {
date = sdf.parse(str[0]);
Calendar c = Calendar.getInstance();
c.setTime(date);
int year = c.get(1);
String hot = str[1].substring(0, str[1].indexOf("°C"));
KeyPair keypair = new KeyPair();
keypair.setYear(year);
keypair.setHot(Integer.valueOf(hot));
context.write(keypair, value);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
/**shuffle阶段:
* partition》combiner(可省略)》sort》group
*
*/
static class HotReducer extends Reducer {
@Override
protected void reduce(KeyPair key, Iterable iter, Context context)
throws IOException, InterruptedException {
for (Text text : iter) {
context.write(key, text);
}
}
}
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
final String INPUT_PATH = "hdfs://192.168.24.203:9000/user/hot/hot.txt";
final String OUTPUT_PATH = "hdfs://192.168.24.203:9000/user/hot/out";
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if(fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "Hot");
job.setJarByClass(RunJob.class);
job.setMapperClass(HotMapper.class);
job.setReducerClass(HotReducer.class);
job.setMapOutputKeyClass(KeyPair.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(3);//设置reduce任务的个数
job.setPartitionerClass(FirstPartition.class);
job.setSortComparatorClass(SortHot.class);
job.setGroupingComparatorClass(GroupHot.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ?0 : 1);
}
}
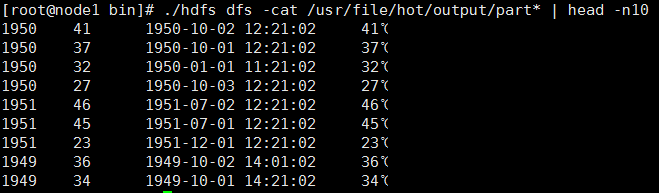
结果: