Jpa save 与 flush debug源码过程
版本:Spring Boot 1.5.8.RELEASE
JpaRepository
强烈建议 repo 接口继承 JpaRepository 因为其中拥有 flush 相关的一系列的方法,当执行save()不一定会去提交到数据库,与数据库进行约束的匹配。
在通常情况下 JpaRepository 在注入的时候会是 SimpleJpaRepository 的实例
save()
@Transactional
public <S extends T> S save(S entity) {
// 判断一个对象是新的还是查询出来的
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
// 核心方法
return em.merge(entity);
}
}
isNew()
判断一个对象是否为一个新实体,感觉目前有点困惑
当执行 isNew() 方法实际上的执行的是 JpaMetamodelEntityInformation的方法
@Override
public boolean isNew(T entity) {
// 如果 versionAttribute 为 null 或者对应的类型是java原生类型
if (versionAttribute == null || versionAttribute.getJavaType().isPrimitive()) {
return super.isNew(entity);
}
BeanWrapper wrapper = new DirectFieldAccessFallbackBeanWrapper(entity);
Object versionValue = wrapper.getPropertyValue(versionAttribute.getName());
// 返回版本号信息是否为null
return versionValue == null;
}
super.isNew()
上文中的 super.isNew() -> AbstractEntityInformation
public boolean isNew(T entity) {
// 获取entity的主键属性
ID id = getId(entity);
Class<ID> idType = getIdType();
// 如果是原生类型 integer Long ...
if (!idType.isPrimitive()) {
// 返回是否为空
return id == null;
}
// 如果实现 Number 接口 BigDecimal,BigInteger ...
if (id instanceof Number) {
// 就看值是不是为 0
return ((Number) id).longValue() == 0L;
}
// 都不是就抛出异常
throw new IllegalArgumentException(String.format("Unsupported primitive id type %s!", idType));
}
return em.merge(entity)
合并数据,根据注释阅读是进行将上下文数据进行持久态的转变的转变,将上下文中数据更新
AbstractEntityManagerImpl 具体执行的方法
@Override
@SuppressWarnings("unchecked")
public <A> A merge(A entity) {
checkOpen();
try {
// 拆开来阅读源码
// 1. internalGetSession() 返回一个数据库的session并且应该是没有添加校验的
// Return a Session without any validation checks.
// 2. session.merge( entity )
/**
* Copy the state of the given object onto the persistent object with the same
* identifier. If there is no persistent instance currently associated with
* the session, it will be loaded. Return the persistent instance. If the
* given instance is unsaved, save a copy of and return it as a newly persistent
* instance. The given instance does not become associated with the session.
* This operation cascades to associated instances if the association is mapped
* with {@code cascade="merge"}
* The semantics of this method are defined by JSR-220.
*
* /
/**
*将给定对象的状态复制到具有相同对象的持久对象上
*标识符。 如果当前没有与之关联的持久性实例
*会话,它将被加载。 返回持久化实例。 如果
*给定实例未保存,保存副本并将其作为新持久化返回
*实例。 给定的实例不会与会话关联。
*如果映射关联,此操作会级联到关联的实例
*与{@code cascade =“merge”}
*
*此方法的语义由JSR-220定义。
*在下段代码将阅读一下 session.merge(entity)
*/
return ( A ) internalGetSession().merge( entity );
}
catch ( ObjectDeletedException sse ) {
throw convert( new IllegalArgumentException( sse ) );
}
catch ( MappingException e ) {
throw convert( new IllegalArgumentException( e.getMessage(), e ) );
}
catch ( RuntimeException e ) {
//including HibernateException
throw convert( e );
}
}
session.merge(entity)
具体的merge方法
SessionImpl merge(entity)
// 入口
@Override
public Object merge(Object object) throws HibernateException {
return merge( null, object );
}
// 2ed
@Override
public Object merge(String entityName, Object object) throws HibernateException {
return fireMerge( new MergeEvent( entityName, object, this ) );
}
// 3th
private Object fireMerge(MergeEvent event) {
//如果session关闭报错
errorIfClosed();
//检查事务的同步的状态
checkTransactionSynchStatus();
//操作前检查没有未解决的操作
checkNoUnresolvedActionsBeforeOperation();
//合并数据的监听器 事件监听模式
for ( MergeEventListener listener : listeners( EventType.MERGE ) ) {
listener.onMerge( event );
}
//操作后检查没有未解决的操作
checkNoUnresolvedActionsAfterOperation();
//直接返回数据事件的数据
return event.getResult();
}
onMerge( event )
来看看MergeEventListener都做了什么鬼事情 DefaultMergeEventListener
大体上来说就真正在上下文中进行数据值更新持久太转换的逻辑
- 逻辑判断交叉引用
- 级联关系
- 上下文数据赋值
public void onMerge(MergeEvent event) throws HibernateException {
final EntityCopyObserver entityCopyObserver = createEntityCopyObserver( event.getSession().getFactory() );
final MergeContext mergeContext = new MergeContext( event.getSession(), entityCopyObserver );
try {
onMerge( event, mergeContext );
entityCopyObserver.topLevelMergeComplete( event.getSession() );
}
finally {
entityCopyObserver.clear();
mergeContext.clear();
}
}
public void onMerge(MergeEvent event, Map copiedAlready) throws HibernateException {
// 持久化的上下文
final MergeContext copyCache = (MergeContext) copiedAlready;
// 事件源
final EventSource source = event.getSession();
// 事件目标 此时就是 待执行 save(持久化) 方法的对象
final Object original = event.getOriginal();
if ( original != null ) {
final Object entity;
if ( original instanceof HibernateProxy ) {
LazyInitializer li = ( (HibernateProxy) original ).getHibernateLazyInitializer();
if ( li.isUninitialized() ) {
LOG.trace( "Ignoring uninitialized proxy" );
event.setResult( source.load( li.getEntityName(), li.getIdentifier() ) );
return; //EARLY EXIT!
}
else {
entity = li.getImplementation();
}
}
else {
entity = original;
}
//copyCache.containsKey( entity )
//如果此MergeContext包含指定合并实体的交叉引用,则返回true 到管理实体的结果。
//copyCache.isOperatedOn( entity )
//如果侦听器正在对指定的合并实体执行合并操作,则返回true。
if ( copyCache.containsKey( entity ) &&
( copyCache.isOperatedOn( entity ) ) ) {
LOG.trace( "Already in merge process" );
event.setResult( entity );
}
else {
if ( copyCache.containsKey( entity ) ) {
LOG.trace( "Already in copyCache; setting in merge process" );
copyCache.setOperatedOn( entity, true );
}
event.setEntity( entity );
EntityState entityState = null;
// Check the persistence context for an entry relating to this
//检查持久性上下文以获取与此相关的条目
// entity to be merged... 要合并的实体......
// 获取上下文中的实体
EntityEntry entry = source.getPersistenceContext().getEntry( entity );
if ( entry == null ) {
EntityPersister persister = source.getEntityPersister( event.getEntityName(), entity );
Serializable id = persister.getIdentifier( entity, source );
if ( id != null ) {
final EntityKey key = source.generateEntityKey( id, persister );
final Object managedEntity = source.getPersistenceContext().getEntity( key );
entry = source.getPersistenceContext().getEntry( managedEntity );
if ( entry != null ) {
// we have specialized case of a detached entity from the
// perspective of the merge operation. Specifically, we
// have an incoming entity instance which has a corresponding
// entry in the current persistence context, but registered
// under a different entity instance
entityState = EntityState.DETACHED;
}
}
}
// public static enum EntityState {
// PERSISTENT, TRANSIENT, DETACHED, DELETED
// } 持久,短暂(临时),游离态,删除
if ( entityState == null ) {
entityState = getEntityState( entity, event.getEntityName(), entry, source );
}
switch ( entityState ) {
case DETACHED:
entityIsDetached( event, copyCache );
break;
case TRANSIENT:
entityIsTransient( event, copyCache );
break;
case PERSISTENT:
// 开始执行 持久化的代码
entityIsPersistent( event, copyCache );
break;
default: //DELETED
throw new ObjectDeletedException(
"deleted instance passed to merge",
null,
getLoggableName( event.getEntityName(), entity )
);
}
}
}
}
protected void entityIsPersistent(MergeEvent event, Map copyCache) {
LOG.trace( "Ignoring persistent instance" );
//TODO: check that entry.getIdentifier().equals(requestedId)
final Object entity = event.getEntity(); // 待持久化的实体
final EventSource source = event.getSession(); //会话session
// 还不晓得是什么鬼
final EntityPersister persister = source.getEntityPersister( event.getEntityName(), entity );
// 把缓存中的数据与待缓存的数据进行合并 考虑交叉引用
//(真的好复杂,就这样效率感觉效率会很低啊,这应该就是传说中的一级缓存了)
( (MergeContext) copyCache ).put( entity, entity, true ); //before cascade!
//执行作为此复制事件的一部分所需的任何级联。 (级联? 暂不考虑了)
cascadeOnMerge( source, persister, entity, copyCache );
//把值重新赋值一下? 源码上没有注释 (实在是看不懂了)
copyValues( persister, entity, entity, source, copyCache );
//往事件中设置结果值
//(搞了半天 save 方法就是在操作对象的上下文数据 一级缓存内部的合并 交叉引用)
event.setResult( entity );
}
结论
目前源码一路debug下来发现
hibernate的save方法基本就是在操作hibernate的session和entity的上下文,没有涉及数据的交互。在debug过程也发现真的的数据提交(执行sql语句)将sql发送给数据服务器是在事务提交或者主动flush才会执行的。
其中不得不服hibernate开发团队开发的心思缜密,在更新一级缓存时做了很多的工作
- 当前对象是否new出来的->执行
update或者insert - 考虑到了对象的交叉引用(因为debug的原因没有去比较深入的阅读源码)
- 考虑到了数据的级联更新(项目中没有使用暂时没有去了解)
- 事件监听
- 上下文数据赋值(hibernate 中是 merge 合并 状态更改 游离态,持久态…)
flush()
AbstractEntityManagerImpl依旧使用的是这个类中方法
@Override
public void flush() {
//检查是否打开 session 暂不深入
checkOpen();
//事务相关检查 暂不深入
checkTransactionNeeded();
try {
// 分成两个部分 internalGetSession() 和 session.flush()
// 其中 internalGetSession() 返回一个session对象 具体在上一部分中已经介绍过了
// session.flush() 核心 下文将继续了解
internalGetSession().flush();
}
catch ( RuntimeException e ) {
throw convert( e );
}
}
session.flush()
session的刷新算是一个入口吧,做一些判断
- session开启判断
- 事务状态判断
- 级联深度判断,hibernate认为存在级联时直接刷新有可能会有风险,目前对这个级联深度没有进一步的了解
- 创建一个flush事件,具有处理逻辑都在监听器里面实现了
貌似全是这样的看的有点难受,还是没能理解hibernate的设计哲学,强行逻辑搞成事件监听器模式,而且debug过程中往往发现监听器只有一个,是不是理论上我可以往hibernate的上下文添加监听器来处理搞事情,后续有机会会继续往这方面发展考虑
SessionImpl
@Override
public void flush() throws HibernateException {
// 顾名思义 session 关闭报错
errorIfClosed();
// 检查事务同步状态
checkTransactionSynchStatus();
// persistenceContext.getCascadeLevel()
// How deep are we cascaded? 获取级联的级别?
if ( persistenceContext.getCascadeLevel() > 0 ) {
// 缓存级别大于0
// 级联冲洗是危险的 -> Flush during cascade is dangerous
throw new HibernateException( "Flush during cascade is dangerous" );
}
// 创建一个刷新的事件
FlushEvent flushEvent = new FlushEvent( this );
for ( FlushEventListener listener : listeners( EventType.FLUSH ) ) {
// 事件监听 触发事件 核心(根据debug只有一个监听器)
listener.onFlush( flushEvent );
}
delayedAfterCompletion();
}
listener.onFlush( flushEvent )
监听器中的核心方法的处理逻辑,算是一个核心处理的入口吧
主要的关注点如下
- source.getEventListenerManager().flushStart()
- 通过前置条件为上下文刷新作出准备,然而源码阅读后发现并没有什么卵用
- flushEverythingToExecutions( event );
- 真正的上下文层面的刷新数据,数据库交互做准备,
- 寻找上下中待处理的数据,entity,集合等
- 做了同步处理,处理并发问题,其中一个设置flushing可能是一个锁设置
- 将待处理数据进行转换,生成SQL语句,参数等
- 真正的上下文层面的刷新数据,数据库交互做准备,
- performExecutions( source );
- 真正我们希望的事情,以一个特殊的SQL执行顺序以保证级联更新数据的正确性
- 更加上下文信息将待持久化的数据封装成preparedStatement
- 执行preparedStatement.executeUpdate() 最基本的jdbc
- 真正我们希望的事情,以一个特殊的SQL执行顺序以保证级联更新数据的正确性
DefaultFlushEventListener
public void onFlush(FlushEvent event) throws HibernateException {
// session
final EventSource source = event.getSession();
// 持久化上下文
final PersistenceContext persistenceContext = source.getPersistenceContext();
// 获取受管实体数量 || 获取集合条目 -> 待持久化的数据是否大于0
if ( persistenceContext.getNumberOfManagedEntities() > 0 ||
persistenceContext.getCollectionEntries().size() > 0 ) {
try {
// 事件源尝试开始刷新
// source.getEventListenerManager() -> SessionEventListenerManagerImpl
// SessionEventListenerManager.flushStart()
source.getEventListenerManager().flushStart();
// 应该是比较核心的方法了 但是
//事与愿违 在执行完这个方法之后 并未进行数据库约束匹配
flushEverythingToExecutions( event );
// 这是 performExecutions( source ) 的 源注释
//Execute all SQL (and second-level cache updates) in a special order
//so that foreign-key constraints cannot
// 以特殊的顺序执行所有sql的语句(和耳机缓存的更新)以便于处理级联和外键关联
// 目测应该就是这个方法了
performExecutions( source );
postFlush( source );
}
finally {
source.getEventListenerManager().flushEnd(
event.getNumberOfEntitiesProcessed(),
event.getNumberOfCollectionsProcessed()
);
}
postPostFlush( source );
if ( source.getFactory().getStatistics().isStatisticsEnabled() ) {
source.getFactory().getStatisticsImplementor().flush();
}
}
}
SessionEventListenerManager.flushStart()
感觉没有什么营养
SessionEventListenerManager -> (只有一个实现类) SessionEventListenerManagerImpl
private List<SessionEventListener> listenerList;
@Override
public void flushStart() {
// 默认情况下 listenerList = null
if ( listenerList == null ) {
return;
}
for ( SessionEventListener listener : listenerList ) {
listener.flushStart();
}
}
flushEverythingToExecutions( event )
真正的上下文层面的刷新数据,数据库交互做准备
AbstractFlushingEventListener
/**
* Coordinates the processing necessary to get things ready for executions
* as db calls by preping the session caches and moving the appropriate
* entities and collections to their respective execution queues.
*
* @param event The flush event.
* @throws HibernateException Error flushing caches to execution queues.
*
*协调处理准备就绪所需的处理
*作为db调用,通过预先设置会话缓存并移动相应的缓存
*实体和集合到各自的执行队列。
*/
protected void flushEverythingToExecutions(FlushEvent event) throws HibernateException {
LOG.trace( "Flushing session" );
EventSource session = event.getSession();
final PersistenceContext persistenceContext = session.getPersistenceContext();
// 获取刷新之前的拦截器,执行预刷新逻辑方法
session.getInterceptor().preFlush( new LazyIterator( persistenceContext.getEntitiesByKey() ) );
// 实体预刷新上下文
prepareEntityFlushes( session, persistenceContext );
// we could move this inside if we wanted to
// tolerate collection initializations during
// collection dirty checking:
// 集合预刷新上下文
prepareCollectionFlushes( persistenceContext );
// now, any collections that are initialized
// inside this block do not get updated - they
// are ignored until the next flush
// 持久化上下午处于刷新过程中 (可能与同步多线程有关)
persistenceContext.setFlushing( true );
try {
// 刷新实体
int entityCount = flushEntities( event, persistenceContext );
int collectionCount = flushCollections( session, persistenceContext );
event.setNumberOfEntitiesProcessed( entityCount );
event.setNumberOfCollectionsProcessed( collectionCount );
}
finally {
persistenceContext.setFlushing(false);
}
//some statistics
logFlushResults( event );
}
flushEntities( event, persistenceContext )
查看对于单个实体是如何进行flush的
-
检测任何脏实体
-
安排需要更新的实体
-
搜索任何可到达的集合 -> (个人猜测)级联更新
-
以后hibernate封装的线程安全的方式获取待flush的对象
-
进行对象hibernate上下状态判断及处理(持久态,游离态…)
- 一些核心逻辑以监听器的方式执行(不说了,难受 )
AbstractFlushingEventListener
/**
* 1. detect any dirty entities 检测任何脏实体
* 2. schedule any entity updates 安排任何实体更新
* 3. search out any reachable collections 搜索任何可到达的集合
*/
private int flushEntities(final FlushEvent event, final PersistenceContext persistenceContext) throws HibernateException {
LOG.trace( "Flushing entities and processing referenced collections" );
final EventSource source = event.getSession();
// 又来了获取所有的刷新时执行的监听器 -> (debug时只有一个 JpaFlushEntityEventListener)
final Iterable<FlushEntityEventListener> flushListeners = source.getFactory().getServiceRegistry()
.getService( EventListenerRegistry.class )
.getEventListenerGroup( EventType.FLUSH_ENTITY )
.listeners();
// Among other things, updateReachables() will recursively load all
// collections that are moving roles. This might cause entities to
// be loaded.
// So this needs to be safe from concurrent modification problems.
//除其他外,updateReachables()将递归加载所有
//正在移动角色的集合。 这可能会导致实体
//被加载
//因此,这需要避免并发修改问题。
//以一种线程安全可重入的方式获取 Map 的底层存取数组
final Map.Entry<Object,EntityEntry>[] entityEntries = persistenceContext.reentrantSafeEntityEntries();
final int count = entityEntries.length;
for ( Map.Entry<Object,EntityEntry> me : entityEntries ) {
// Update the status of the object and if necessary, schedule an update
EntityEntry entry = me.getValue();
/**
public enum Status {
MANAGED, 管理
READ_ONLY, 只读
DELETED, 删除
GONE, 游离态?
LOADING, 加载中
SAVING 持久户过程中?
}
*/
// debug 时处于 MANAGED
Status status = entry.getStatus();
if ( status != Status.LOADING && status != Status.GONE ) {
final FlushEntityEvent entityEvent = new FlushEntityEvent( source, me.getKey(), entry );
for ( FlushEntityEventListener listener : flushListeners ) {
// 目前debug也只有一个实现类 DefaultFlushEntityEventListener的方法
listener.onFlushEntity( entityEvent );
}
}
}
// 对更新进行排序?
source.getActionQueue().sortActions();
return count;
}
listener.onFlushEntity( entityEvent )
处理单个实体flush的核心逻辑
通过调度将单个实体的状态刷新到数据库必要时更新操作 这个是方法的文档说明
- 校验检查脏数据
- 获取到SQL执行的参数和参数类型
- 校验是否必要的更新 (具体不懂,不求甚解了)
- 搜索可达性集合(貌似与级联有关)已经删除的上下文数据不进行处理
DefaultFlushEntityEventListener
/**
* Flushes a single entity's state to the database, by scheduling
* an update action, if necessary
* 通过调度将单个实体的状态刷新到数据库必要时更新操作
*/
public void onFlushEntity(FlushEntityEvent event) throws HibernateException {
final Object entity = event.getEntity();
final EntityEntry entry = event.getEntityEntry();
final EventSource session = event.getSession();
final EntityPersister persister = entry.getPersister();
final Status status = entry.getStatus();
final Type[] types = persister.getPropertyTypes();
//表示实体可能是脏的并且脏检查
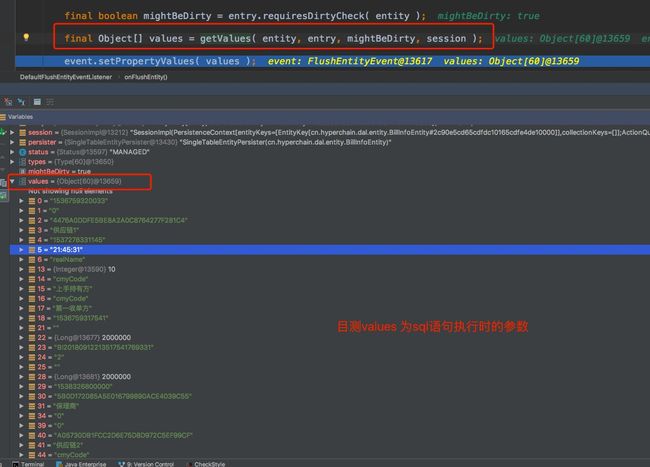
final boolean mightBeDirty = entry.requiresDirtyCheck( entity );
//通过debug得知values应该是sql语句执行的参数 下面有截图
final Object[] values = getValues( entity, entry, mightBeDirty, session );
event.setPropertyValues( values );
//TODO: avoid this for non-new instances where mightBeDirty==false
// 第一次false
boolean substitute = wrapCollections( session, persister, types, values );
//是必要的更新? 看不下去源码了 目前debug时是必要的
if ( isUpdateNecessary( event, mightBeDirty ) ) {
// 此时true
substitute = scheduleUpdate( event ) || substitute;
}
// 目前status = MANAGED
if ( status != Status.DELETED ) {
// now update the object .. has to be outside the main if block above (because of collections)
if ( substitute ) {
persister.setPropertyValues( entity, values );
}
// Search for collections by reachability, updating their role.
// We don't want to touch collections reachable from a deleted object
//按可达性搜索集合,更新其角色。
//我们不想触摸从已删除对象可到达的集合
if ( persister.hasCollections() ) {
new FlushVisitor( session, entity ).processEntityPropertyValues( values, types );
}
}
}
上文中 values 截图为证
至此 flushEntities 才刚结束 就暂时不看 flushCollections了太复杂了
小结
DefaultFlushEventListener onFlush
try {
source.getEventListenerManager().flushStart();
flushEverythingToExecutions( event );
// 在这个方法执行之前,只是刷新了刷新了上下文数据,为执行SQL语句做了准备
// 上下文级联对象管理,将数据实体进行包装得到SQL执行的参数等
// 根据注释 performExecutions( source )这里应该是执行sql的调用
performExecutions( source );
postFlush( source );
}
performExecutions( source )
真正开始要发送SQL语句执行存储
- 上下文同步处理
- 将此次session要处理的数据排序放进队列,上文介绍的保护级联数据更新的安全
- 执行session中待处理的队列
session.getActionQueue().executeActions();
DefaultFlushEventListener
protected void performExecutions(EventSource session) {
LOG.trace( "Executing flush" );
// IMPL NOTE : here we alter the flushing flag of the persistence context to allow
// during-flush callbacks more leniency in regards to initializing proxies and
// lazy collections during their processing.
// For more information, see HHH-2763
try {
session.getJdbcCoordinator().flushBeginning();
// 设置持久化上下文正在刷新(同步处理?)
session.getPersistenceContext().setFlushing( true );
// we need to lock the collection caches before executing entity inserts/updates in order to
// account for bi-directional associations
// 准备内部操作队列以执行。
session.getActionQueue().prepareActions();
// 执行所有当前排队的操作。
session.getActionQueue().executeActions();
}
finally {
// session持久化上下文结束刷新
session.getPersistenceContext().setFlushing( false );
session.getJdbcCoordinator().flushEnding();
}
}
session.getActionQueue().executeActions()
执行SQL真正的逻辑还是在监听器中执行
ActionQueue
/**
* Perform all currently queued actions.
* 执行所有当前排队的操作。
* @throws HibernateException error executing queued actions.
*/
public void executeActions() throws HibernateException {
// 是否有未解析的实体插入操作依赖于与可暂时实体的非可空关联
// 所以有级联数据和多线程时是不是手动flush会导致上下文执行异常?
if ( hasUnresolvedEntityInsertActions() ) {
throw new IllegalStateException( "About to execute actions, but there are unresolved entity insert actions." );
}
for ( ListProvider listProvider : EXECUTABLE_LISTS_MAP.values() ) {
ExecutableList<?> l = listProvider.get( this );
if ( l != null && !l.isEmpty() ) {
// 开始执行sql 出现违反数据约束时抛出异常了
executeActions( l );
}
}
}
executeActions( l )
监听器要执行的核心方法
- 个人猜测这里也是使用到了一个命令模式
private <E extends Executable & Comparable<?> & Serializable> void executeActions(ExecutableList<E> list) throws HibernateException {
// todo : consider ways to improve the double iteration of Executables here:
// 1) we explicitly iterate list here to perform Executable#execute()
// 2) ExecutableList#getQuerySpaces also iterates the Executables to collect query spaces.
try {
for ( E e : list ) {
try {
e.execute();
}
finally {
if( e.getBeforeTransactionCompletionProcess() != null ) {
if( beforeTransactionProcesses == null ) {
beforeTransactionProcesses = new BeforeTransactionCompletionProcessQueue( session );
}
beforeTransactionProcesses.register(e.getBeforeTransactionCompletionProcess());
}
if( e.getAfterTransactionCompletionProcess() != null ) {
if( afterTransactionProcesses == null ) {
afterTransactionProcesses = new AfterTransactionCompletionProcessQueue( session );
}
afterTransactionProcesses.register(e.getAfterTransactionCompletionProcess());
}
}
}
}
finally {
if ( session.getFactory().getSessionFactoryOptions().isQueryCacheEnabled() ) {
// Strictly speaking, only a subset of the list may have been processed if a RuntimeException occurs.
// We still invalidate all spaces. I don't see this as a big deal - after all, RuntimeExceptions are
// unexpected.
Set<Serializable> propertySpaces = list.getQuerySpaces();
invalidateSpaces( propertySpaces.toArray( new Serializable[propertySpaces.size()] ) );
}
}
list.clear();
session.getJdbcCoordinator().executeBatch();
}
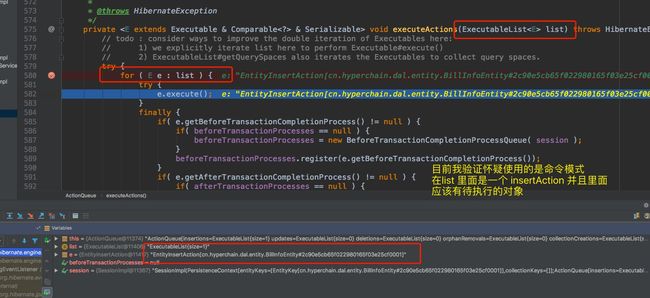
顺便看一下EntityInsertAction的execute()方法
@Override
public void execute() throws HibernateException {
nullifyTransientReferencesIfNotAlready();
final EntityPersister persister = getPersister();
final SessionImplementor session = getSession();
final Object instance = getInstance();
final Serializable id = getId();
final boolean veto = preInsert();
// Don't need to lock the cache here, since if someone
// else inserted the same pk first, the insert would fail
//这里不需要锁定缓存,因为如果有人
//否则先插入相同的pk,插入会失败
//-> 是不是在hibernate的事件不进行相关的约束判断,把约束校验规则交给数据去做
if ( !veto ) {
// 应该开始真正的执行了sql数据库方言转换等操作吧
persister.insert( id, getState(), instance, session );
PersistenceContext persistenceContext = session.getPersistenceContext();
final EntityEntry entry = persistenceContext.getEntry( instance );
if ( entry == null ) {
throw new AssertionFailure( "possible non-threadsafe access to session" );
}
entry.postInsert( getState() );
...
}
感觉经过不断的 debug 找到了重点 AbstractEntityPersister的insert 方法
/**
* Perform an SQL INSERT. 执行一条SQL语句 SQL 语句作为参数传入
*
* This for is used for all non-root tables as well as the root table
* in cases where the identifier value is known before the insert occurs.
*/
protected void insert(
final Serializable id,
final Object[] fields,
final boolean[] notNull,
final int j,
final String sql,
final Object object,
final SessionImplementor session) throws HibernateException {
if ( isInverseTable( j ) ) {
return;
}
//note: it is conceptually possible that a UserType could map null to
// a non-null value, so the following is arguable:
if ( isNullableTable( j ) && isAllNull( fields, j ) ) {
return;
}
if ( LOG.isTraceEnabled() ) {
LOG.tracev( "Inserting entity: {0}", MessageHelper.infoString( this, id, getFactory() ) );
if ( j == 0 && isVersioned() ) {
LOG.tracev( "Version: {0}", Versioning.getVersion( fields, this ) );
}
}
// TODO : shouldn't inserts be Expectations.NONE?
final Expectation expectation = Expectations.appropriateExpectation( insertResultCheckStyles[j] );
// we can't batch joined inserts, *especially* not if it is an identity insert;
// nor can we batch statements where the expectation is based on an output param
final boolean useBatch = j == 0 && expectation.canBeBatched();
if ( useBatch && inserBatchKey == null ) {
inserBatchKey = new BasicBatchKey(
getEntityName() + "#INSERT",
expectation
);
}
final boolean callable = isInsertCallable( j );
try {
// Render the SQL query
// 由此可知这个是预编译的 而且还是批处理的想想应该也是
final PreparedStatement insert;
if ( useBatch ) {
insert = session
.getJdbcCoordinator()
.getBatch( inserBatchKey )
.getBatchStatement( sql, callable );
}
else {
insert = session
.getJdbcCoordinator()
.getStatementPreparer()
.prepareStatement( sql, callable );
}
try {
int index = 1;
index += expectation.prepare( insert );
// Write the values of fields onto the prepared statement - we MUST use the state at the time the
// insert was issued (cos of foreign key constraints). Not necessarily the object's current state
dehydrate( id, fields, null, notNull, propertyColumnInsertable, j, insert, session, index, false );
if ( useBatch ) {
//貌似在这里进行批处理开始匹配数据库的约束,在这里报错了session.getJdbcCoordinator().getBatch( inserBatchKey ).addToBatch();
}
else {
expectation.verifyOutcome(
session.getJdbcCoordinator()
.getResultSetReturn()
.executeUpdate( insert ), insert, -1
);
}
}
catch (SQLException e) {
if ( useBatch ) {
session.getJdbcCoordinator().abortBatch();
}
throw e;
}
finally {
if ( !useBatch ) {
session.getJdbcCoordinator().getResourceRegistry().release( insert );
session.getJdbcCoordinator().afterStatementExecution();
}
}
}
catch (SQLException e) {
throw getFactory().getSQLExceptionHelper().convert(
e,
"could not insert: " + MessageHelper.infoString( this ),
sql
);
}
}
报错的截图如下
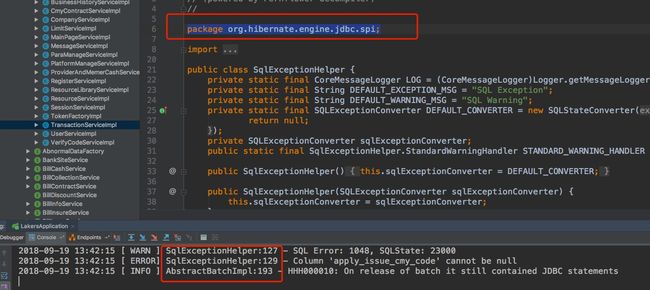
根据报错的日志可以看出都是hibernate的报错,会不会是hibernate在内存中进行的判断,然后接下来感觉就打脸了
ResultSetReturnImpl
//最终一次save最终的目的地就是executeUpdate方法 用一个预编译的PreparedStatement去执行
@Override
public int executeUpdate(PreparedStatement statement) {
try {
jdbcExecuteStatementStart();
return statement.executeUpdate();
}
catch (SQLException e) {
//然后就开始报错了
throw sqlExceptionHelper.convert( e, "could not execute statement" );
}
finally {
jdbcExecuteStatementEnd();
}
}
小结
flush 的方法主要就是将hibernate上下文刷新,将上下文刷新应该有这么几个步骤
- 准备阶段 进行一些上下文刷新的准备 一些判断执行
- 上下文数据刷新阶段 更新数据状态,级联数据查询,生成SQL参数
- 上下文持久化刷新阶段,开始真的的执行SQL交互
真正的数据约束交互是在最后一步执行的
saveAndFlush
这就感觉不需要多说了直接上代码
先save再flush
@Transactional
public <S extends T> S saveAndFlush(S entity) {
S result = save(entity);
flush();
return result;
}