MySQL索引优化策略-论坛经典实例整理
二.索引优化策略
索引类型
1.B-tree索引
注:名叫btree索引,大的方面看,都用的平衡树,但具体的实现上,各引擎稍有不同。比如严格的说NDB引擎使用的是T-tree
Myisam,innodb中默认用B-tree索引
B-tree系统抽象一下,可以理解为“排好序的快速查找结构”
B-tree常见误区:
1. 在where条件常用的列上都加上索引
例:where cat_id=3and price>100 cat_id和price上都加上索引,只能用上cat_id和price索引其中一个; 因为是独立的索引,同时只能用上一个
2.在多列上建立索引后,索引发挥作用,需要满足左前缀规则
myisam主索引和次索引都指向物理行(磁盘位置),称为非聚簇索引
InnoDB主索引文件上,直接存放该行数据,称为聚簇索引,次索引指向对主键的引用
注意:innodb来说:
1. 主键索引既存储索引值,又在叶子中存储行的数据
2. 如果没有主键(primary key),则会unique key做主键
3. 如果没有unique,则系统生成一个内部的rowid做主键
4. 像innodb中,主键的索引结构,既存储了主键值,又存储了行数据,这种结构称为“聚簇索引”
单独两个列的独立索引and查询,只能一个发挥作用,更多使用的是多列索引
多列索引的考虑因素—列的查询频率,列的区分度,列的查询顺序。注意一定要结合实际业务场景
索引与排序:
1. 对于覆盖索引,直接在索引上查询时,就是有序的 using index
在innodb引擎中,沿着索引字段排序,也是自然有序的;对于myisam引擎,如果按某索引字段排序,如id 但取出的字段中,有未索引字段,如goods_name,myisam的做法不是索引->回行,索引->回行,而是先取出所有行,再进行排序
2.先取出数据,形成临时表做filesort(文件排序,但文件可能在磁盘上,也可能在内存中)
索引提高排序(照着有序的索引找出来的数据自然是有序的)
索引用于分组(分组需要先按分组字段排序),group by的列要有索引,可以避免临时表及文件排序
order by的列要和group by的列一致,否则也会引起临时表
(原因是因为group by和orderby都需要排序,所以如果两者的列不一致,那必须经过至少一次排序)
索引覆盖:
索引覆盖是指如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据
这种查询速度非常快,称为“索引覆盖”
聚簇索引的页分裂:
聚簇索引中,N行形成一个页,当不规则插入时,不断造成页分裂,插入速度比较慢
冗余索引:
冗余索引是指2个索引所覆盖的列有重叠,称为冗余索引
例:文章标签表id artid tag
实际使用中有两种查询:artid—查询文章的—tag tag—查询文章的--artid
例题:
1.有商品表,有主键goods_id,栏目列cat_id,价格price,在价格列上已经加了索引,单价格查询还是很慢。
可能原因,怎么解决?
实际场景中,一个电商网站商品的分类很多,直接在所有商品中按价格查询商品是极少的,一般客户都来到分类下,再查;
可能在商品栏目列上已经加了一个索引,导致price上加的索引没发挥作用;
改正:去掉单独的price列的索引,加(cat_id, price)复合索引。
2.假设某个表有一个联合索引(c1,c2,c3,c4) 以下 只能使用该联合索引的c1,c2,c3部分
A. where c1 = ‘a’ and c2 = ‘b’ and c4>’c’ and c3 = ‘d’
B. where c1 = ‘a’ and c2 = ‘b’ and c4=’c’ order by c3
C. where c1 = ‘a’ and c4 = ‘b’ group by c3, c2
D. where c1 = ‘a’ and c5 = ‘b’ order by c2, c3
E. where c1 = ‘a’ and c2 = ‘b’ and c5=’c’ order by c2, c3
create table t6(
c1 char(1) not null default '',
c2 char(1) not null default '',
c3 char(1) not null default '',
c4 char(1) not null default '',
c5 char(1) not null default '',
key idx_t6(c1,c2,c3,c4)
)engine myisam charset=utf8;
insert into t6 values ('a','b','c','d','e'),('A','b','c','d','e'),('a','B','c','d','e');
详见:https://www.cnblogs.com/loveyouyou616/p/6369744.html
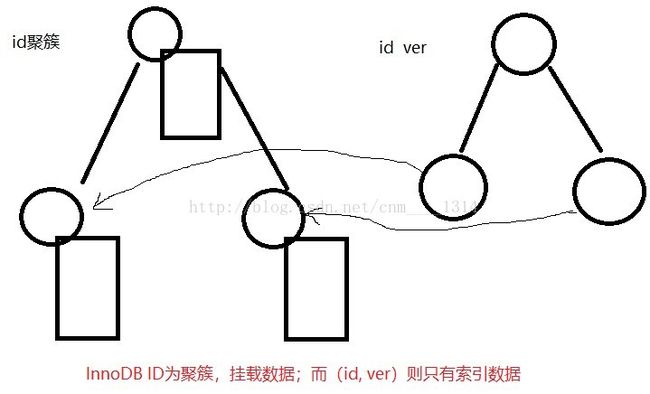
3. 问题描述如下:
create table A(
id varchar(64) primary key,
ver int,
…
)
在id, ver上有联合索引
10000条数据
为什么select id from A order by id特别慢?
而select id from A order by id, ver非常快
我们表有几个很长的字段 text(3000)
疑问:id, (id, ver)都有索引,select id都应该产生“索引覆盖“的效果,为什么前者慢,后者快
思路:innodb聚簇与myisam非聚簇索引的不同,索引覆盖这两个角度来考虑
分析:对于myisam索引都是指向磁盘上的位置(索引不存储其他列的数据,统统指到磁盘去)
推断:
1. 表如果是myisam引擎,2个语句速度不会有明显差异
2. Innodb表因为聚簇索引,id主键索引要在磁盘上跨N多块,导致速度慢
3. 即使innodb引擎,如果没有那几个varbinary长列,2个语句的速度也不会有明显差异
2.hash索引
在memory里默认是hash索引,hash的理论查询时间复杂度为O(1)
Hash查找如此高效,为什么不都用hash索引?
1. hash函数计算后的结果是随机的;如果是在磁盘上放置数据。
比如:主键id为例,随着id增长,id对应的行,在磁盘上随机放置
2.无法对范围查询进行优化
3.无法利用前缀索引;比如:field列的值为“helloworld”,并加索引,hash(“helloworld”)和hash(“hello”),两者的关系仍为随机
4.排序也无法优化
5.必须回行;也就是说,通过索引拿到数据位置,必须回到表中取数据
注:hash算法返回一个地址,数据和hash值是一对一算出来。位置重复:拉链算法
理想的索引
1. 查询频繁 2.区分度高 3.长度小 4.尽量能覆盖常用查询字段
索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多)
索引碎片与维护
在长期的数据更新过程中,索引文件和数据文件,都将产生空洞,形成碎片
我们可以通过一个nop操作(不产生对数据实质影响的操作), 来修改表
比如: 表的引擎为innodb , 可以alter table xxx engine innodb (修改表的引擎类型为其默认类型会重新调整数据,但不会影响数据)
optimize table 表名 ,也可以修复
注意: 修复表的数据及索引碎片,就会把所有的数据文件重新整理一遍,使之对齐.
这个过程,如果表的行数比较大,也是非常耗费资源的操作.
所以,不能频繁的修复.
如果表的Update操作很频率,可以按周/月,来修复.
如果不频繁,可以更长的周期来做修复.
详见:https://www.cnblogs.com/qlqwjy/p/8594859.html