机器学习之-支持向量机SVM原理
支持向量机
支持向量机(support vector machine,简称SVM)是一种二分类模型,它的基本模型是在特征空间上的间隔最大化的线性分类器,其学习模型的策略是间隔最大化,可转化为一个求解凸二次规划的最优化问题。训练后的线性分类器模型不仅保证了每个实例的预测类别准确性,而且还提高了每个实例的预测类别的置信度,从而增强了分类器模型的泛化能力。
支持向量机支持的由简至繁的模型:
- 线性可分支持向量机:当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机。
- 线性支持向量机:当大部分训练数据线性可分,只有极少数数据不可分时,可通过软间隔最大化,学习一个线性分类器,即线性支持向量机。
- 非线性支持向量机:当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习一个非线性支持向量机。
一、线性可分支持向量机
给定一个特征空间上的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)}其中, x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , . . . , N , x i x_i\in \mathcal {X}=R^n,y_i \in \mathcal {Y}=\left\{+1,-1\right\},i=1,2,...,N,x_i xi∈X=Rn,yi∈Y={+1,−1},i=1,2,...,N,xi为第 i i i个实例, y i y_i yi为 x i x_i xi的类标记,当 y i = + 1 y_i=+1 yi=+1时, x i x_i xi为正例;当 y i = − 1 y_i=-1 yi=−1时, x i x_i xi为负例。假设训练数据集是线性可分的。学习的目标是在特征空间中找到一个分离超平面,能将所有实例划分到正确的类别中。分离的超平面模型是 w x + b = 0 wx+b=0 wx+b=0,模型参数是法向量 w w w和截距 b b b。分离超平面将特征空间划分为两类,一个是正类,另一个是负类。
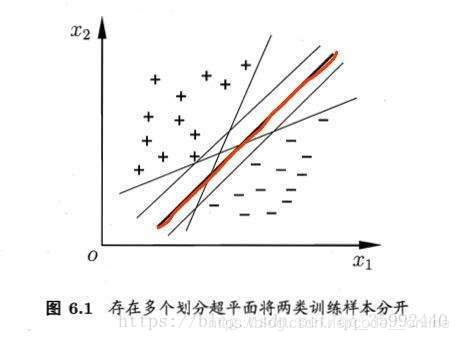
然而,当训练数据集线性可分时,存在无穷个分类超平面可将两类数据正确分开。虽然这些分类器保证了实例的正确分类,但是每个模型的泛化能力是有所差异的。为了保证实例以最大可能性的置信度进行预测分类,线性可分支持向量机利用间隔最大化来求解最优分离超平面。这个最优超平面是唯一的。
那么,问题来了,怎么确定这个最优超平面呢?
一般来说,一个点距离分离超平面越远,则表明这个分类预测准确度越大。在超平面 w x + b = 0 wx+b=0 wx+b=0确定的情况下, ∣ w x + b ∣ |wx+b| ∣wx+b∣表示这个点 x x x距离超平面的远近,而 w x + b wx+b wx+b的符号与类标记 y y y的符号是否一致能表示分类是否正确。所以可用 y ( w x + b ) y(wx+b) y(wx+b)来表示分类的正确性及确定度,这就是函数间隔。实例 x i x_i xi距离超平面的函数间隔可用 y i ( w x i + b ) y_i(wx_i+b) yi(wxi+b)来表示。但是当成比例的改变 w , b w,b w,b,超平面没有发生改变,但函数间隔也成比例的改变。因此,需要做规范化处理,即除以法向量 w w w的模: y i ( w x i + b ) ∣ ∣ w ∣ ∣ \frac{y_i(wx_i+b)}{||w||} ∣∣w∣∣yi(wxi+b),这就是几何间隔。通过几何间隔度量实例到超平面的距离以及分类正确性。
1.1 间隔最大化
支持向量机学习的基本思想是求解能够正确划分数据集并且几何间隔最大的分离超平面。此时,发现有两个临界面 w T x + b = 1 w^Tx+b=1 wTx+b=1和 w T x + b = − 1 w^Tx+b=-1 wTx+b=−1。 w T x + b = 1 w^Tx+b=1 wTx+b=1是类标记为1的临界面。当类别为1的实例,其满足 w T x i + b ≥ 1 w^Tx_i+b\ge 1 wTxi+b≥1,而类别为-1的实例,其满足 w T x i + b ≤ − 1 w^Tx_i+b\leq -1 wTxi+b≤−1,因此,实例是否正确分类可依据 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\ge 1 yi(wTxi+b)≥1这个条件来判定。为了使得分类置信度最大,需要保证两个临界面之间的距离尽可能的远,事实上相当于类别临界点到分离超平面的二倍几何间隔关系,即满足 2 ∣ ∣ w ∣ ∣ \frac{2}{||w||} ∣∣w∣∣2最大化。其等价于 m i n 1 2 ∣ ∣ w ∣ ∣ 2 min \frac{1}{2}||w||^2 min21∣∣w∣∣2,将其转化为一个凸二次规划的最优化问题: min w , b 1 2 ∣ ∣ w ∣ ∣ 2 \min_{w,b} \frac{1}{2}||w||^2 w,bmin21∣∣w∣∣2 s . t . y i ( w x i + b ) ≥ 1 , i = 1 , 2 , . . . , N s.t. \quad y_i(wx_i+b)\ge 1,\quad i=1,2,...,N s.t.yi(wxi+b)≥1,i=1,2,...,N

1.2 支持向量
在线性可分情况下,训练数据集的样本点中距离分离超平面最近的样本点实例称为支持向量,其满足 y i ( w x i + b ) = 1 y_i(wx_i+b)=1 yi(wxi+b)=1和对应的拉格朗日乘子 α i > 0 \alpha_i>0 αi>0,即临界面上的实例点。
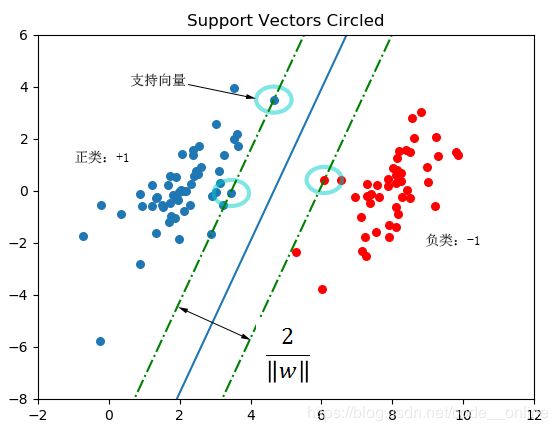
在训练分离超平面模型时,只有支持向量起作用,相对的,其他实例点并不起作用。当改变支持向量时,相应的分离超平面也将发生改变;如果改变除了支持向量的其他实例点,分离超平面不会发生改变。因此,支持向量决定了分离超平面,这种模型被称为支持向量机。支持向量个数一般很少,所以,支持向量机由很少的“重要的”训练样本确定。
1.3 对偶算法
为了求解线性可分支持向量机的最优化问题,将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,这就是线性可分支持向量机的对偶算法。优点是对偶问题通常更容易求解,而且还可以引入核函数,进而推广到非线性分类问题。(具体算法可参阅统计学习方法附录C)
通过拉格朗日函数将一个约束的凸优化问题转化为非约束的优化问题,为此,为每一个实例的不等式约束引入拉格朗日乘子 α i ≥ 0 , i = 1 , 2 , . . . , N \alpha_i\ge 0,i=1,2,...,N αi≥0,i=1,2,...,N,拉格朗日函数如下: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i y i ( w x i + b ) + ∑ i = 1 N α i L(w,b,\alpha)=\frac{1}{2}||w||^2-\sum_{i=1}^N\alpha_iy_i(wx_i+b)+\sum_{i=1}^N\alpha_i L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(wxi+b)+i=1∑Nαi其中, α = ( α 1 , α 2 , . . . , α N ) T \alpha=(\alpha_1,\alpha_2,...,\alpha_N)^T α=(α1,α2,...,αN)T为拉格朗日向量。那么,将原始问题的最优解 w , b w,b w,b转化为拉格朗日函数的极小极大问题,即
min w , b max α L ( w , b , α ) \min_{w,b}\max_{\alpha}L(w,b,\alpha) w,bminαmaxL(w,b,α)根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题: max α min w , b L ( w , b , α ) \max_{\alpha}\min_{w,b}L(w,b,\alpha) αmaxw,bminL(w,b,α)为了得到对偶问题的解,需要先求 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)对 w , b w,b w,b的极小,再求对 α \alpha α的极大。
- min w , b L ( w , b , α ) \min_{w,b}L(w,b,\alpha) minw,bL(w,b,α)
将拉格朗日函数 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)分别对 w , b w,b w,b求偏导数并令其为0。 ∂ L ( w , b , α ) w = w − ∑ i = 1 N α i y i x i = 0 ⟹ w = ∑ i = 1 N α i y i x i \frac{\partial L(w,b,\alpha)}{w}=w-\sum_{i=1}^N\alpha_iy_ix_i=0 \Longrightarrow w=\sum_{i=1}^N\alpha_iy_ix_i w∂L(w,b,α)=w−i=1∑Nαiyixi=0⟹w=i=1∑Nαiyixi ∂ L ( w , b , α ) b = − ∑ i = 1 N α i y i = 0 ⟹ ∑ i = 1 N α i y i = 0 \frac{\partial L(w,b,\alpha)}{b}=-\sum_{i=1}^N\alpha_iy_i=0 \Longrightarrow \sum_{i=1}^N\alpha_iy_i=0 b∂L(w,b,α)=−i=1∑Nαiyi=0⟹i=1∑Nαiyi=0
再将其代入拉格朗日函数中,得到以下函数: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i y i ( w . x i + b ) + ∑ i = 1 N α i = 1 2 ∣ ∣ w ∣ ∣ 2 − w ∑ i = 1 N α i y i x i − b ∑ i = 1 N α i y i + ∑ i = 1 N α i = − 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 N α i = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ + ∑ i = 1 N α i \begin{aligned}L(w,b,\alpha) &=\frac{1}{2}||w||^2-\sum_{i=1}^N\alpha_iy_i(w.x_i+b)+\sum_{i=1}^N\alpha_i \\ &= \frac{1}{2}||w||^2-w\sum_{i=1}^N\alpha_iy_ix_i-b\sum_{i=1}^N\alpha_iy_i+\sum_{i=1}^N\alpha_i \\ &=-\frac{1}{2}||w||^2+\sum_{i=1}^N\alpha_i=-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle+\sum_{i=1}^N\alpha_i \end{aligned} L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w.xi+b)+i=1∑Nαi=21∣∣w∣∣2−wi=1∑Nαiyixi−bi=1∑Nαiyi+i=1∑Nαi=−21∣∣w∣∣2+i=1∑Nαi=−21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩+i=1∑Nαi即 min w , b L ( w , b , α ) = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ + ∑ i = 1 N α i \min_{w,b}L(w,b,\alpha)=-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle+\sum_{i=1}^N\alpha_i w,bminL(w,b,α)=−21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩+i=1∑Nαi - 求 min w , b L ( w , b , α ) \min_{w,b}L(w,b,\alpha) minw,bL(w,b,α)对 α \alpha α的极大,即对偶问题: max α − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ + ∑ i = 1 N α i \max_{\alpha}-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle+\sum_{i=1}^N\alpha_i αmax−21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩+i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . , N s.t. \quad \sum_{i=1}^N\alpha_iy_i=0\\ \alpha_i \ge 0,i=1,2,...,N s.t.i=1∑Nαiyi=0αi≥0,i=1,2,...,N等价于以下最优化问题: min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ − ∑ i = 1 N α i \min_{\alpha}\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle-\sum_{i=1}^N\alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . , N s.t. \quad \sum_{i=1}^N\alpha_iy_i=0\\ \alpha_i \ge 0,i=1,2,...,N s.t.i=1∑Nαiyi=0αi≥0,i=1,2,...,N
对于线性可分训练数据集,对偶优化问题可利用SMO算法(可参考SMO博客)求解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^*=(\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T,进而求解 w ∗ = ∑ i = 1 N α i ∗ y i x i w^*=\sum_{i=1}^N\alpha_i^*y_ix_i w∗=∑i=1Nαi∗yixi, b ∗ b^* b∗可通过选择一个非零的 α i > 0 \alpha_i>0 αi>0,将其对应的 ( x i , y i ) (x_i,y_i) (xi,yi)代入到 y i ( w x i + b ) = 1 y_i(wx_i+b)=1 yi(wxi+b)=1求解 b ∗ = y i − ∑ j = 1 N α j ∗ y j ⟨ x i , x j ⟩ b^*=y_i-\sum_{j=1}^N\alpha_j^*y_j\left \langle x_i,x_j \right \rangle b∗=yi−∑j=1Nαj∗yj⟨xi,xj⟩,最终得到分离超平面及分类决策函数。
分离超平面: ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ = 0 \sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*=0 i=1∑Nαi∗yi⟨x,xi⟩+b∗=0
分类决策函数: f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ ) f(x)=sign(\sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*) f(x)=sign(i=1∑Nαi∗yi⟨x,xi⟩+b∗)
1.4 线性可分支持向量机学习算法
输入:线性可分训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中, x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , . . . , N x_i\in \mathcal {X}=R^n,y_i \in \mathcal {Y}=\left\{+1,-1\right\},i=1,2,...,N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,...,N
输出:分离超平面和分类决策函数
- 构造并求解约束最优化问题 min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ − ∑ i = 1 N α i \min_{\alpha}\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle-\sum_{i=1}^N\alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 s.t. \quad \sum_{i=1}^N\alpha_iy_i=0 s.t.i=1∑Nαiyi=0 α i ≥ 0 , i = 1 , 2 , . . . , N \alpha_i \ge 0,i=1,2,...,N αi≥0,i=1,2,...,N求最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^*=(\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 计算 w ∗ = ∑ i = 1 N α i ∗ y i x i w^*=\sum_{i=1}^N\alpha_i^*y_ix_i w∗=i=1∑Nαi∗yixi选择 α ∗ \alpha^* α∗的一个正分量 α j ∗ > 0 \alpha_j^*>0 αj∗>0,计算 b ∗ = y j − ∑ i = 1 N α i ∗ y i ⟨ x i , x j ⟩ b^*=y_j-\sum_{i=1}^N\alpha_i^*y_i\left \langle x_i,x_j \right \rangle b∗=yj−i=1∑Nαi∗yi⟨xi,xj⟩
- 求分离超平面 ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ = 0 \sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*=0 i=1∑Nαi∗yi⟨x,xi⟩+b∗=0分类决策函数 f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ ) f(x)=sign(\sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*) f(x)=sign(i=1∑Nαi∗yi⟨x,xi⟩+b∗)
在线性可分支持向量机中, w ∗ w^* w∗和 b ∗ b^* b∗只依赖于训练数据对应的 α i ∗ > 0 \alpha_i^*>0 αi∗>0的样本点 ( x i , y i ) (x_i,y_i) (xi,yi),而其他样本点对 w ∗ w^* w∗和 b ∗ b^* b∗没有影响。这些对应的 α i ∗ > 0 \alpha_i^*>0 αi∗>0的样本点 ( x i , y i ) (x_i,y_i) (xi,yi)称为支持向量。
给定线性可分训练数据集,通过硬间隔最大化求解相应的凸二次规划问题学习得到的分离超平面为线性可分支持向量机。
二、线性支持向量机
对于理想情况下,训练数据集是线性可分的,但是在现实问题中的训练数据集存在少量的噪声点或者特异点,这些特殊点导致线性不可分。为了学习分类器模型,将硬间隔最大化的学习策略更改为软间隔最大化,使得分类器模型允许一些噪声点的干扰。为了解决不满足 y i ( w x i + b ) ≥ 1 y_i(wx_i+b)\ge 1 yi(wxi+b)≥1这个约束条件的样本点 ( x i , y i ) (x_i,y_i) (xi,yi),可以对每个样本点 ( x i , y i ) (x_i,y_i) (xi,yi)引入一个松弛变量 ξ i ≥ 0 \xi_i \ge 0 ξi≥0,使函数间隔加上松弛变量大于等于1,即 y i ( w x i + b ) + ξ i ≥ 1 y_i(wx_i+b)+\xi_i\ge 1 yi(wxi+b)+ξi≥1为了防止松弛变量过大,对松弛变量引入了惩罚参数C,目标函数变为: 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i 21∣∣w∣∣2+Ci=1∑Nξi C > 0 C>0 C>0为惩罚参数,C值越大,表明对误分类的 ξ i \xi_i ξi惩罚力度越大;C值越小,则对误分类的 ξ i \xi_i ξi惩罚力度越小。最小化目标函数的含义是使 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2最小化的同时还要保证误分类的个数和对应的松弛变量尽量小,C是调和这两者之间的系数。
软间隔最大化的凸优化问题: min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \min_{w,b,\xi} \quad \frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξi s . t . y i ( w x i + b ) + ξ i ≥ 1 , i = 1 , 2 , . . . , N s.t.\quad y_i(wx_i+b)+\xi_i\ge 1, i=1,2,...,N s.t.yi(wxi+b)+ξi≥1,i=1,2,...,N ξ i ≥ 0 , i = 1 , 2 , . . . , N \xi_i \ge 0, \quad i=1,2,...,N ξi≥0,i=1,2,...,N
原始问题的拉格朗日函数,即
L ( w , b , ξ , α , μ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i − ∑ i = 1 N α i ( y i ( w x i + b ) − 1 + ξ i ) − ∑ i = 1 N μ i ξ i , α i ≥ 0 , μ i ≥ 0 L(w,b,\xi ,\alpha,\mu)=\frac{1}{2}||w||^2+C\sum_{i=1}^N\xi_i-\sum_{i=1}^N\alpha_i(y_i(wx_i+b)-1+\xi_i)-\sum_{i=1}^N\mu_i\xi_i,\quad \alpha_i\ge 0,\mu_i\ge 0 L(w,b,ξ,α,μ)=21∣∣w∣∣2+Ci=1∑Nξi−i=1∑Nαi(yi(wxi+b)−1+ξi)−i=1∑Nμiξi,αi≥0,μi≥0与线性可分支持向量机求解步骤相同,求 L ( w , b , ξ , α , μ ) L(w,b,\xi ,\alpha,\mu) L(w,b,ξ,α,μ)对 w , b , ξ w,b,\xi w,b,ξ的极小 ∂ L ( w , b , ξ , α , μ ) w = w − ∑ i = 1 N α i y i x i = 0 ⟹ w = ∑ i = 1 N α i y i x i ∂ L ( w , b , ξ , α , μ ) b = − ∑ i = 1 N α i y i = 0 ⟹ ∑ i = 1 N α i y i = 0 ∂ L ( w , b , ξ , α , μ ) ξ i = C − α i − μ i = 0 \begin{aligned} & \frac{\partial L(w,b,\xi,\alpha,\mu)}{w}=w-\sum_{i=1}^N\alpha_iy_ix_i=0 \Longrightarrow w=\sum_{i=1}^N\alpha_iy_ix_i \\ & \frac{\partial L(w,b,\xi,\alpha,\mu)}{b}=-\sum_{i=1}^N\alpha_iy_i=0 \Longrightarrow \sum_{i=1}^N\alpha_iy_i=0 \\ &\frac{\partial L(w,b,\xi,\alpha,\mu)}{\xi_i}=C-\alpha_i-\mu_i=0\end{aligned} w∂L(w,b,ξ,α,μ)=w−i=1∑Nαiyixi=0⟹w=i=1∑Nαiyixib∂L(w,b,ξ,α,μ)=−i=1∑Nαiyi=0⟹i=1∑Nαiyi=0ξi∂L(w,b,ξ,α,μ)=C−αi−μi=0将其代入到拉格朗日函数得到如下函数: min w , b , ξ L ( w , b , ξ , α , μ ) = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ + ∑ i = 1 N α i \min_{w,b,\xi}L(w,b,\xi,\alpha,\mu)=-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle+\sum_{i=1}^N\alpha_i w,b,ξminL(w,b,ξ,α,μ)=−21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩+i=1∑Nαi再对 min w , b , ξ L ( w , b , ξ , α , μ ) \min_{w,b,\xi}L(w,b,\xi,\alpha,\mu) minw,b,ξL(w,b,ξ,α,μ)求 α \alpha α的极大,得到对偶问题: max α − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ + ∑ i = 1 N α i \max_{\alpha} \quad -\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle+\sum_{i=1}^N\alpha_i αmax−21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩+i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 s.t. \qquad \sum_{i=1}^N\alpha_iy_i=0 s.t.i=1∑Nαiyi=0 C − α i − μ i = 0 C-\alpha_i-\mu_i=0 C−αi−μi=0 α i ≥ 0 , i = 1 , 2 , . . . , N \alpha_i \ge 0,i=1,2,...,N αi≥0,i=1,2,...,N μ i ≥ 0 , i = 1 , 2 , . . . , N \mu_i \ge 0,i=1,2,...,N μi≥0,i=1,2,...,N
等价于 min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ − ∑ i = 1 N α i \min_{\alpha} \quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle-\sum_{i=1}^N\alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 s.t. \qquad \sum_{i=1}^N\alpha_iy_i=0 s.t.i=1∑Nαiyi=0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N 0 \leq \alpha_i \leq C,i=1,2,...,N 0≤αi≤C,i=1,2,...,N同理,对于满足KKT条件的对偶问题,通过SMO算法求解对偶问题的解,从而得到原始问题的解,最终确定分离超平面及分类决策函数。
2.1 线性支持向量机学习算法
输入:线性可分训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中, x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , . . . , N x_i\in \mathcal {X}=R^n,y_i \in \mathcal {Y}=\left\{+1,-1\right\},i=1,2,...,N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,...,N
输出:分离超平面和分类决策函数
- 选择惩罚参数C>0,构造并求解凸二次规划问题 min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ⟨ x i , x j ⟩ − ∑ i = 1 N α i \min_{\alpha} \quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\left \langle x_i,x_j \right \rangle-\sum_{i=1}^N\alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj⟨xi,xj⟩−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 s.t. \qquad \sum_{i=1}^N\alpha_iy_i=0 s.t.i=1∑Nαiyi=0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N 0 \leq \alpha_i \leq C,i=1,2,...,N 0≤αi≤C,i=1,2,...,N求最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^*=(\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 计算 w ∗ = ∑ i = 1 N α i ∗ y i x i w^*=\sum_{i=1}^N\alpha_i^*y_ix_i w∗=i=1∑Nαi∗yixi选择 α ∗ \alpha^* α∗的一个正分量 0 < α j ∗ < C 0 < \alpha_j^* < C 0<αj∗<C,计算 b ∗ = y j − ∑ i = 1 N α i ∗ y i ⟨ x i , x j ⟩ b^*=y_j-\sum_{i=1}^N\alpha_i^*y_i\left \langle x_i,x_j \right \rangle b∗=yj−i=1∑Nαi∗yi⟨xi,xj⟩
- 求分离超平面 ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ = 0 \sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*=0 i=1∑Nαi∗yi⟨x,xi⟩+b∗=0分类决策函数 f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ⟨ x , x i ⟩ + b ∗ ) f(x)=sign(\sum_{i=1}^N\alpha_i^*y_i\left \langle x,x_i \right \rangle+b^*) f(x)=sign(i=1∑Nαi∗yi⟨x,xi⟩+b∗)
2.2 支持向量
分离超平面由实线表示,间隔边界由虚线表示,正例点由“o”表示,负例点由“x”表示。实例 x i x_i xi到间隔边界的距离为 ξ i ∣ ∣ w ∣ ∣ \frac{\xi_i}{||w||} ∣∣w∣∣ξi
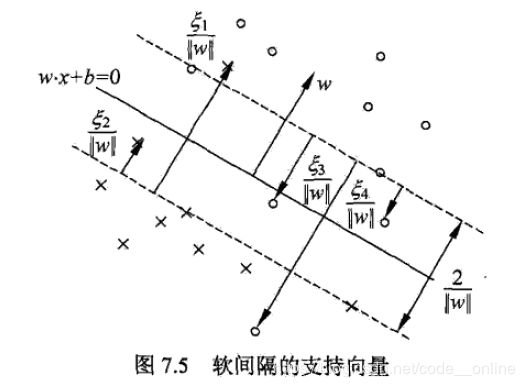
软间隔的支持向量 x i x_i xi可能在间隔边界上,或者在间隔边界与分离超平面之间,或者在分离超平面误分的一侧。若 α i < C \alpha_i<C αi<C,则 ξ i = 0 \xi_i=0 ξi=0,支持向量 x i x_i xi在间隔边界上;若 α i = C , 0 < ξ i < 1 \alpha_i=C,0<\xi_i<1 αi=C,0<ξi<1,则分类正确, x i x_i xi在间隔边界与分离超平面之间;若 α i = C , ξ i = 1 \alpha_i=C,\xi_i=1 αi=C,ξi=1,则 x i x_i xi在分离超平面上;若 α i = C , ξ i > 1 \alpha_i=C,\xi_i>1 αi=C,ξi>1,则 x i x_i xi在分离超平面误分的另一侧;
对于给定的线性不可分的训练数据集,通过软间隔最大化求解的凸二次规划问题,得到的分离超平面是线性支持向量机。
三、非线性支持向量机
3.1 核技巧
非线性分类问题一般无法直接用线性分类器来进行有效分类,只能利用非线性模型才能很好地进行分类。例如,如下图是样本的分布,在该空间内不存在一个线性分类器进行分类,但是存在一个超曲面可将正负例分类。
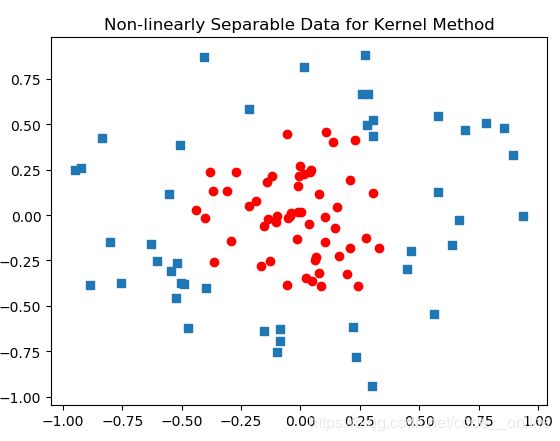
为了使用线性分类问题的解决方法,将该特征空间的实例映射到另一特征空间内,使得实例点线性可分,其采取的方法是进行一个非线性变化,把非线性问题变换为线性问题,再通过解决变换后的线性问题的方法求解原始的非线性问题。
用线性分类方法求解非线性分类问题分为两步:首先使用一个非线性变换将原始空间的数据映射到新的空间,然后,在新空间里用线性分类学习方法从训练数据中学习分类模型。
那么,问题来了,如何找到这种特征空间呢?如何确定原始空间到新特征空间的映射函数呢?
核技巧应用到支持向量机,其基本思想是通过一个非线性变换将输入空间映射到一个特征空间,使得在输入空间中的超曲面模型对应特征空间的超平面模型,这样,分类问题可通过在特征空间求解线性支持向量机。
事实上,根本不需要大费周章的求解新特征空间及相应的映射函数。由于原始空间的超平面模型与新空间的超平面模型是一一对应的关系,原始空间里超曲面模型中的 ⟨ x , z ⟩ \left \langle x,z \right \rangle ⟨x,z⟩对应着新空间里超平面的 ⟨ ϕ ( x ) , ϕ ( z ) ⟩ \left \langle \phi(x),\phi(z)\right \rangle ⟨ϕ(x),ϕ(z)⟩,只需要计算 ⟨ ϕ ( x ) , ϕ ( z ) ⟩ \left \langle \phi(x),\phi(z)\right \rangle ⟨ϕ(x),ϕ(z)⟩即可得到实例的预测类别。但是,计算 ⟨ ϕ ( x ) , ϕ ( z ) ⟩ \left \langle \phi(x),\phi(z)\right \rangle ⟨ϕ(x),ϕ(z)⟩相对比较复杂。因此,引入了核函数 K ( x , z ) K(x,z) K(x,z),其等价于 ⟨ ϕ ( x ) , ϕ ( z ) ⟩ \left \langle \phi(x),\phi(z)\right \rangle ⟨ϕ(x),ϕ(z)⟩,节省了求解新特征空间及对应的映射函数所带来的开销,简化了模型的求解过程。
核函数:设 X \mathcal X X是输入空间, H \mathcal H H是特征空间,如果存在一个从 X \mathcal X X到 H \mathcal H H的映射 ϕ ( x ) : X → H \phi(x):\mathcal X \to \mathcal H ϕ(x):X→H使得所有 x , z ∈ X x,z\in \mathcal X x,z∈X,满足 K ( x , z ) K(x,z) K(x,z)满足条件 K ( x , z ) = ϕ ( x ) . ϕ ( z ) K(x,z)=\phi(x).\phi(z) K(x,z)=ϕ(x).ϕ(z) K ( x , z ) K(x,z) K(x,z)为核函数, ϕ ( x ) \phi(x) ϕ(x)为映射函数, ϕ ( x ) . ϕ ( z ) \phi(x).\phi(z) ϕ(x).ϕ(z)为 ϕ ( x ) \phi(x) ϕ(x)与 ϕ ( z ) \phi(z) ϕ(z)的乘积。
使用核技巧的对偶问题的目标函数变为: 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^N\alpha_i 21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi相应的分类决策函数: f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i ⟨ ϕ ( x i ) , ϕ ( x j ) ⟩ + b ∗ ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x i , x j ) + b ∗ ) f(x)=sign(\sum_{i=1}^N\alpha_i^*y_i\left \langle \phi(x_i),\phi(x_j) \right \rangle+b^*)=sign(\sum_{i=1}^N\alpha_i^*y_iK(x_i,x_j)+b^*) f(x)=sign(i=1∑Nαi∗yi⟨ϕ(xi),ϕ(xj)⟩+b∗)=sign(i=1∑Nαi∗yiK(xi,xj)+b∗)
在核函数 K ( x , z ) K(x,z) K(x,z)给定的条件下,利用解线性分类问题的方法求解非线性分类问题的支持向量机。学习是隐式地在特征空间进行,不需要显示低定义特征空间与映射函数,这样的技巧为核技巧,巧妙地利用线性分类学习方法与核函数解决非线性分类问题。
3.2 常用的核函数
- 线性核函数(linear) K ( x , z ) = ⟨ x , z ⟩ K(x,z)=\left \langle x,z \right \rangle K(x,z)=⟨x,z⟩
- 多项式核函数(poly) K ( x , z ) = ( γ ⟨ x , z ⟩ + r ) d K(x,z)=(\gamma\left \langle x,z \right \rangle+r)^d K(x,z)=(γ⟨x,z⟩+r)d
- 高斯核函数(rbf) K ( x , z ) = e x p ( − γ ∣ ∣ x − z ∣ ∣ 2 ) K(x,z)=exp(-\gamma||x-z||^2) K(x,z)=exp(−γ∣∣x−z∣∣2)
- sigmoid核函数 t a n h ( γ ⟨ x , z ⟩ + r ) tanh(\gamma\left \langle x,z \right \rangle+r) tanh(γ⟨x,z⟩+r)
3.3 非线性支持向量机学习算法
输入:训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中, x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , . . . , N x_i\in \mathcal {X}=R^n,y_i \in \mathcal {Y}=\left\{+1,-1\right\},i=1,2,...,N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,...,N
输出:分类决策函数
- 选择适当的核函数 K ( x , z ) K(x,z) K(x,z)和适当的惩罚参数C>0,构造并求解最优化问题 min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i \min_{\alpha} \quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^N\alpha_i αmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 s.t. \qquad \sum_{i=1}^N\alpha_iy_i=0 s.t.i=1∑Nαiyi=0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N 0 \leq \alpha_i \leq C,i=1,2,...,N 0≤αi≤C,i=1,2,...,N求最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^*=(\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 计算 w ∗ = ∑ i = 1 N α i ∗ y i x i w^*=\sum_{i=1}^N\alpha_i^*y_ix_i w∗=i=1∑Nαi∗yixi选择 α ∗ \alpha^* α∗的一个正分量 0 < α j ∗ < C 0 < \alpha_j^* < C 0<αj∗<C,计算 b ∗ = y j − ∑ i = 1 N α i ∗ y i K ( x i , x j ) b^*=y_j-\sum_{i=1}^N\alpha_i^*y_iK(x_i,x_j) b∗=yj−i=1∑Nαi∗yiK(xi,xj)
- 分类决策函数 f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x)=sign(\sum_{i=1}^N\alpha_i^*y_iK(x,x_i)+b^*) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)
从非线性分类训练集,通过核函数和软间隔最大化,学习得到的分类决策函数为非线性支持向量。
四、SVM参数
| 参数 | 含义 |
|---|---|
| C | float类型,默认值为1.0,错误实例的惩罚参数 |
| kernel | 默认核函数为rbf,可选项为“linear”,“poly”,“rbf”’,“sigmoid”, “precomputed“等等 |
| degree | 默认为3.0,只有poly核函数有这个参数,其他核函数没有 |
| gamma | ‘rbf’, ‘poly’ and 'sigmoid’核函数的核系数。默认为auto,如果默认值,则表示为1/n_features |
| coef0 | 只有’poly’ and 'sigmoid’核函数有这个参数,用 r r r表示,默认为0.0 |
| probability | boolean类型,表示是否启用概率评估 |
| shrinking | Boolean类型,默认为True,表示是否使用缩减启发式 |
| tol | 默认为1e-3,表示标准终止的容忍值 |
| cache_size | 指定核缓存的大小 |
| class_weight | 类别的权重,字典形式传递。设置第几类的参数C为weight*C |
| verbose | 默认为False,是否支持冗余输出 |
| max_iter | 默认为-1,表示最大迭代次数。-1为无限制 |
| decision_function_shape | ‘ovo’:one vs one, ‘ovr’:one vs rest, default=‘ovr’ |
| random_state | 数据洗牌时的种子值,int值 |
五、SVM实战
import numpy as np
import pandas as pd
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
def load_data():
iris = load_iris()
df_iris = pd.DataFrame(iris.data, columns=iris.feature_names)
df_iris['label'] = iris.target
df_iris.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
df_data = np.array(df_iris.iloc[:100, :])
for i in range(len(df_data)):
if df_data[i, -1] == 0:
df_data[i, -1] = -1
del df_iris
return df_data[:, :-1], df_data[:, -1]
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2019)
class SVM(object):
def __init__(self, max_iter=100, kernel='linear', C=1.0):
self.max_iter = max_iter
self.kernel = kernel
self.C = C # 松弛变量
self.b = 0.0 # 偏置b
# 初始化参数
def _init_args(self, data, label):
self.instances, self.features = data.shape # (样本实例数量,特征数量)
self.X = data
self.y = label
self.alpha = np.zeros(self.instances) # 实例对应的拉格朗日乘子
self.E = [self._E(i) for i in range(self.instances)] # 实例对应的误差
# 计算误差
def _E(self, i):
return self.gxi(i) - self.y[i]
# 核函数
def _kernel(self, xi, xj):
if self.kernel == 'linear':
return sum([xi[k] * xj[k] for k in range(self.features)])
if self.kernel == 'poly':
return (sum([xi[k] * xj[k] for k in range(self.features)]) + 1) ** 2
return 0
# 样本的预测值
def gxi(self, i):
r = self.b
for j in range(self.instances):
r += self.alpha[j] * self.y[j] * self._kernel(self.X[i], self.X[j])
return r
# KKT条件
def KKT(self, i):
y_g = self.y[i] * self.gxi(i)
if self.alpha[i] == 0:
return y_g >= 1
elif 0 < self.alpha[i] < self.C:
return y_g == 1
else:
return y_g <= 1
# 选择合适的i,j
def init_alphas(self):
support_vectors_indexs = [i for i in range(self.instances) if 0 < self.alpha[i] < self.C]
non_safity_list = [i for i in range(self.instances) if i not in support_vectors_indexs]
support_vectors_indexs.extend(non_safity_list)
for i in support_vectors_indexs:
if self.KKT(i):
continue
Ei = self.E[i]
if Ei >= 0:
j = min(range(self.instances), key=lambda x: self.E[x])
else:
j = max(range(self.instances), key=lambda x: self.E[x])
return i, j
# 范围约束的拉格朗日乘子
def _compare(self, L, H, _alpha):
if _alpha >= H:
return H
elif _alpha <= L:
return L
else:
return _alpha
# 训练模型
def fit(self, data, label):
self._init_args(data, label)
for iter in range(self.max_iter):
i, j = self.init_alphas()
Ei, Ej = self.E[i], self.E[j]
if self.y[i] == self.y[j]:
L = max(0, self.alpha[j] + self.alpha[i] - self.C)
H = min(self.C, self.alpha[j] + self.alpha[i])
else:
L = max(0, self.alpha[j] - self.alpha[i])
H = min(self.C, self.C + self.alpha[j] - self.alpha[i])
eta = self._kernel(self.X[i], self.X[i]) + self._kernel(self.X[j], self.X[j]) \
- 2 * self._kernel(self.X[i], self.X[j])
if eta <= 0:
continue
alphaj_new_unc = self.alpha[j] + self.y[j] * (Ei - Ej) / eta
alphaj_new = self._compare(L, H, alphaj_new_unc)
alphai_new = self.alpha[i] + self.y[i] * self.y[j] * (self.alpha[j] - alphaj_new)
# 更新偏置b
b1_new = -self.E[i] - self.y[i] * self._kernel(self.X[i], self.X[i]) * (alphai_new - self.alpha[i]) - \
self.y[j] * self._kernel(self.X[j], self.X[i]) * (alphaj_new - self.alpha[j]) + self.b
b2_new = -self.E[j] - self.y[i] * self._kernel(self.X[i], self.X[j]) * (alphai_new - self.alpha[i]) - \
self.y[j] * self._kernel(self.X[j], self.X[j]) * (alphaj_new - self.alpha[j]) + self.b
if alphai_new > 0 and alphai_new < self.C:
b_new = b1_new
elif alphaj_new > 0 and alphaj_new < self.C:
b_new = b2_new
else:
b_new = (b1_new + b2_new) / 2
self.alpha[i] = alphai_new
self.alpha[j] = alphaj_new
self.b = b_new
self.E[i] = self._E(i)
self.E[j] = self._E(j)
print('train done...')
def predict(self, data):
r = self.b
for i in range(self.instances):
r += self.alpha[i] * self.y[i] * self._kernel(self.X[i], data)
return 1 if r > 0 else -1
def score(self, X_test, y_test):
pred_cnt = sum(1 for i in range(len(X_test)) if self.predict(X_test[i]) == y_test[i])
return pred_cnt / len(X_test)
svm = SVM()
svm.fit(X_train, y_train)
print("The score of custom svm model's prediction is :",svm.score(X_test, y_test))
clf = SVC(gamma='auto')
clf.fit(X_train,y_train)
print("The score of built-in SVC model's prediction is:",clf.score(X_test,y_test))
The score of custom svm model's prediction is: 0.95
The score of built-in SVC model's prediction is: 1.0
参考文献
- 李航 《统计学习方法》
- 周志华 《机器学习》
- scikit-learn官方文档