spark2.x 独立集群环境搭建 | 适用于spark集群环境搭建
在开始环境搭建的教程之前,先说明下 此篇博文为作者自学过程中实际操作总结,正确性以验证,并作为一位学习者记录自己的操作过程。
准备一个以上的unix系统环境 | 克隆WM虚拟机及修改系统参数的全过程
克隆WM虚拟机
克隆之前local模式下调试的spark虚拟机,采用克隆完整文件的模式



修改unix系统参数
通过上一步的克隆,得到多个unix系统环境,现在拿其中一个进行修改举例,其余部分大致相同,除了IP和主机名以外。
第一步 修改mac地址
在虚拟机还未启动之前,先修改该系统的mac地址,如下操作所示。
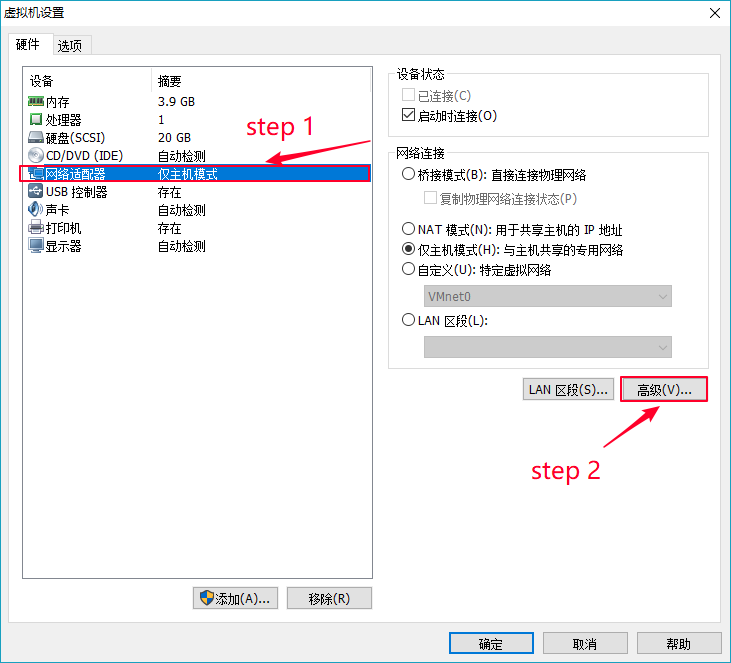

生成新的mac地址,并用记事本记录
修改完成后启动虚拟机
打开终端窗口并切换到root用户,键入命令
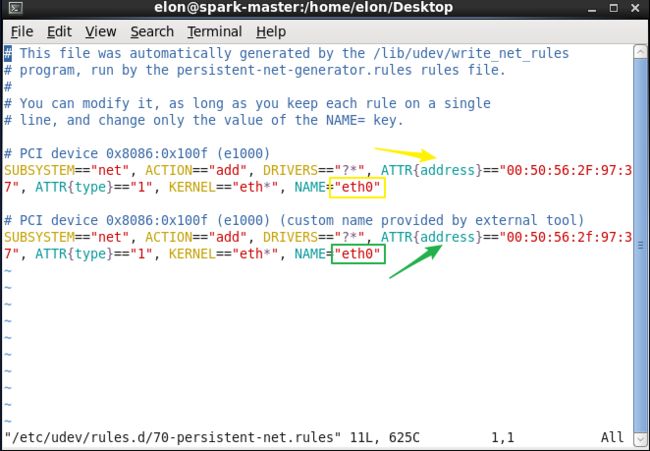
vim /etc/udev/rules.d/70-persistent-net.rules
通过图形化界面可以看到网络使用的是系统自动创建的自动分配IP地址的虚拟网卡Auto eth1或者除开eth0以外的其他虚拟网卡配置信息栏,这时候删除其他的配置信息栏,只留下eth0,并将eth0中ATTR{address}修改为刚才用记事本记录的mac地址,修改成功后保存该文本,如下所示。
第二步 修改ip地址
同样在root用户下,通过键入以下命令,修改IP地址、网关地址及mac地址。
vim /etc/sysconfig/network-scripts/ifcfg-eth0

第三步 修改hostname
通过以下两个命令,在两处修改hostname
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=spark-master
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.180 spark-master
192.168.1.181 spark-slave
以上步骤修改完成,重启系统。
至此,克隆WM虚拟机及修改系统参数的全过程
集群介绍及配置集群环境
通过上一克隆步骤,所有主机上都拥有相同的spark文件了,下面我们来介绍如何使用集群启动脚本。在我的配置过程中,由于磁盘存储空间的原因,只设置了两个unix系统,配置列表如下:
主机名 IP地址
spark-master 192.168.1.180
spark-slave 192.168.1.181
这里需要注意:集群中所有主机的hosts文件中,ip地址与主机名的映射关系都需要添加进去,因为这里涉及到跨主机通信,在主节点上启动工作节点时,会涉及使用其他主机的hostname的情况。
在两个unix系统的/etc/hosts文件中,分别加入集群中各主机的ip地址与主机名映射
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.180 spark-master
192.168.1.181 spark-slave
第一步 配置master到slave的免密登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
ssh-copy-id localhost
第二步 编辑主节点的 $SPARK_HOME/conf/slaves 文件并填上所有工作节点的主机名
echo "spark-slave" >> $SPARK_HOME/conf/slaves
第三步 修改$HADOOP_HOME/bin/hadoop下的core-site.xml和yarn-site.xml文件配置,由原来的local模式转为集群模式
## core-site.xml
fs.defaultFS
hdfs://spark-master:9000/
hadoop.tmp.dir
/home/elon/app/hadoop-2.7.5/tmp
hadoop.http.staticuser.user
elon.hadoop-yarn
## yarn-site.xml
yarn.resourcemanager.hostname
spark-slave
yarn.nodemanager.aux-services
mapreduce_shuffle
具体的Hadoop集群配置,可以参考我的另一篇博文【hadoop2.x完全分布式环境搭建 | 适用于hadoop完全分布式集群环境搭建】
注意:$SPARK_HOME/conf/spark_env.sh文件中之前设置的参数现在都注释掉,复原为原始样式,因为之前设置的参数是和spark local模式下运行相关的,作者本人之前就因为这个地方未注意导致Master和work进程启动起来后,瞬间挂掉了…
启动standalone模式集群 sbin/start-all.sh
可以在http://spark-master:8080中看到集群管理器的网页用户界面,上面显示着所有的工作节点

要停止集群,在主节点上运行 sbin/stop-all.sh
至此,spark2.x 独立集群环境搭建的所有工作完成,报告完毕!
转载请注明出处:http://blog.csdn.net/coder__cs/article/details/79177956
本文出自【elon33的博客】