利用-TensorFlow-实现卷积自编码器
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
介绍和概念
自动编码器(Auto-encoders)是神经网络的一种形式,它的输入数据与输出数据是相同的。他们通过将输入数据压缩到一个潜在表示空间里面,然后再根据这个表示空间将数据进行重构得到最后的输出数据。
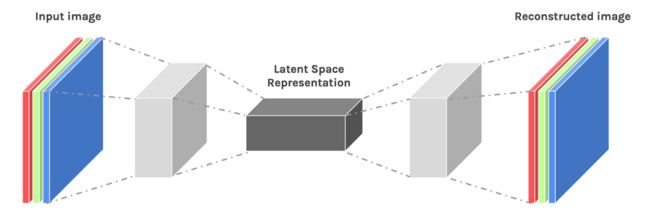
自编码器的一个非常受欢迎的使用场景是图像处理。其中使用到的小技巧是用卷积层来替换全连接层。这个转变方法是将一个非常宽的,非常瘦的(比如 100*100 的像素点,3 通道,RGB)图像转换成一个非常窄的,非常厚的图像。这种方法非常有助于帮助我们从图像中提取出视觉特征,从而得到更准确的潜在表示空间。最后我们的图像重构过程采用上采样和卷积。
这个自编码器就称之为卷积自编码器(Convolutional Autoencoder,CAE)
使用卷积自编码器
卷积自编码器可以用于图像的重构工作。例如,他们可以学习从图片中去除噪声,或者重构图片缺失的部分。
为了实现上述提到的效果,我们一般不使用相同的输入数据和输出数据,取而代之的是,使用含有噪声的图片作为输入数据,然后输出数据是一个干净的图片。卷积自编码器就会通过学习,去去除图片中的噪声,或者去填补图片中的空缺部分。
接下来,让我们来看一下 CAE 是如何来填充图中眼睛上的十字架。我们假设图片的眼睛上面存在一个十字架黑影,我们需要删除这个十字架噪声。首先,我们需要来手动创建这个数据库,当然,这个动作非常方便。
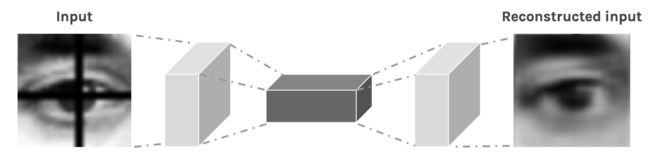
现在我们的卷积自编码器就可以开始训练了,我们可以用它去除我们从未见过的眼睛照片上面的十字线!
利用 TensorFlow 来实现这个卷积自编码器
看我们利用 MNIST 数据集来看看这个网络是如何实现的,完整的代码可以在 Github 上面下载。
网络架构
卷积自编码器的编码部分将是一个典型的卷积过程。每一个卷积层之后都会加上一个池化层,主要是为了减少数据的维度。解码器需要从一个非常窄的数据空间中重构出一个宽的图像。
一般情况下,你会看到我们后面是采用反卷积层来增加我们图像的宽度和高度。它们的工作原理和卷积层的工作原理几乎完全一样,但是作用方向相反。比如,你有一个 3*3 的卷积核,那么在编码器中我们是将该区域的图像编码成一个元素点,但是在解码器中,也就是反卷积中,我们是把一个元素点解码成 3*3 个元素点。TensorFlow API 为我们提供了这个功能,参考 tf.nn.conv2d_transpose
自动编码器只需要在噪声的图像上进行训练,就可以非常成功的进行图片去燥。比如,我们可以在训练图片中添加入高斯噪声来创建包含噪声的图像,然后将这些像素值裁剪在 0 到 1 之间。我们将噪声图像作为输入数据,最原始的感觉图像作为输出数据,也就是我们的目标值。
模型定义
learning_rate = 0.001
inputs_ = tf.placeholder(tf.float32, (None, 28, 28, 1), name='inputs')
targets_ = tf.placeholder(tf.float32, (None, 28, 28, 1), name='targets')
### Encoder
conv1 = tf.layers.conv2d(inputs=inputs_, filters=32, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 28x28x32
maxpool1 = tf.layers.max_pooling2d(conv1, pool_size=(2,2), strides=(2,2), padding='same')
# Now 14x14x32
conv2 = tf.layers.conv2d(inputs=maxpool1, filters=32, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 14x14x32
maxpool2 = tf.layers.max_pooling2d(conv2, pool_size=(2,2), strides=(2,2), padding='same')
# Now 7x7x32
conv3 = tf.layers.conv2d(inputs=maxpool2, filters=16, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 7x7x16
encoded = tf.layers.max_pooling2d(conv3, pool_size=(2,2), strides=(2,2), padding='same')
# Now 4x4x16
### Decoder
upsample1 = tf.image.resize_images(encoded, size=(7,7), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# Now 7x7x16
conv4 = tf.layers.conv2d(inputs=upsample1, filters=16, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 7x7x16
upsample2 = tf.image.resize_images(conv4, size=(14,14), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# Now 14x14x16
conv5 = tf.layers.conv2d(inputs=upsample2, filters=32, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 14x14x32
upsample3 = tf.image.resize_images(conv5, size=(28,28), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# Now 28x28x32
conv6 = tf.layers.conv2d(inputs=upsample3, filters=32, kernel_size=(3,3), padding='same', activation=tf.nn.relu)
# Now 28x28x32
logits = tf.layers.conv2d(inputs=conv6, filters=1, kernel_size=(3,3), padding='same', activation=None)
#Now 28x28x1
# Pass logits through sigmoid to get reconstructed image
decoded = tf.nn.sigmoid(logits)
# Pass logits through sigmoid and calculate the cross-entropy loss
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=targets_, logits=logits)
# Get cost and define the optimizer
cost = tf.reduce_mean(loss)
opt = tf.train.AdamOptimizer(learning_rate).minimize(cost)训练过程:
sess = tf.Session()
epochs = 100
batch_size = 200
# Set's how much noise we're adding to the MNIST images
noise_factor = 0.5
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for ii in range(mnist.train.num_examples//batch_size):
batch = mnist.train.next_batch(batch_size)
# Get images from the batch
imgs = batch[0].reshape((-1, 28, 28, 1))
# Add random noise to the input images
noisy_imgs = imgs + noise_factor * np.random.randn(*imgs.shape)
# Clip the images to be between 0 and 1
noisy_imgs = np.clip(noisy_imgs, 0., 1.)
# Noisy images as inputs, original images as targets
batch_cost, _ = sess.run([cost, opt], feed_dict={inputs_: noisy_imgs,
targets_: imgs})
print("Epoch: {}/{}...".format(e+1, epochs),
"Training loss: {:.4f}".format(batch_cost))来源:
Meduim
hackernoon