(十)stacking 简介
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
(一)机器学习中的集成学习入门
(二)bagging 方法
(三)使用Python进行交易的随机森林算法
(四)Python中随机森林的实现与解释
(五)如何用 Python 从头开始实现 Bagging 算法
(六)如何利用Python从头开始实现随机森林算法
(七)AdaBoost 简介
(八)Python 中的 AdaBoost 分类器实例
(九)AdaBoost 中参数对于决策边界复杂度分析
(十)stacking 简介
集成学习通过组合多种模型来改善机器学习的结果,与单一的模型相比,这种方法允许产生更好的预测性能。这就是为什么在许多著名的机器学习竞赛中,集成学习方法总是被优先考虑。集成学习属于元算法,即结合数个“好而不同”的机器学习技术,形成一个预测模型,以此来降方差(bagging),减偏差(boosting),提升预测准确性(stacking)。今天,我们来学习的就是其中一个技术 stacking 方法。
如果你的模型没有达到 50% 的正确率,并且你经常发现自己将机器学习模型调整到凌晨,但是你又只能提高一点点的性能。那么,这篇文章非常适合你。
什么是模型堆叠?
模型堆叠是一种数据科学基础方法,它依赖于多个模型的结果,即将多个弱学习器的结果进行组织,往往胜过单一的强模型。过去几年中大多数主要 kaggle 比赛的获胜者在最终获奖模型中都使用了模型堆叠。
堆叠模型类比于现实世界的例子,就比如商业团队,科学实验,或者体育团队。如果团队中的所有成员都非常擅长完成同样的任务,那么团队就会摧毁任何需要这个任务的挑战。
在现实中我们如何实践?
下面你可以看到一个最近的主要 kaggle 比赛的最佳获奖模型的例子:
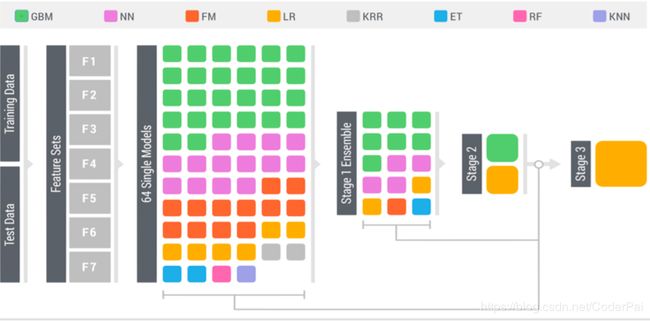
注意:拥有足够数量的数据以执行强大的模型堆栈非常重要。为了避免过度拟合,你需要在每个堆叠(训练阶段)进行交叉验证,并将一些数据作为测试阶段的数据,在训练集和测试集上面保证模型的性能之间没有太大的差异。
- 初始阶段:你运行各种不同的独立模型,并花一些时间分析其各自的性能指标,并考虑某些模型可能比其他模型做的更好的地方。
- 阶段一集成:你选择这些模型的小团队,确保其预测系数之间的相关性较低,以确保你的 stacked model 允许较弱链接之间的大量交叉学习。你可以获取预测的平均值并构建一个新表,该表将在第 2 阶段输入一个新的较小的模型团队。
- 阶段二集成:你运行新的模型集合,它将使用阶段 1 中的平均预测度量作为要素,以便了解有关原始变量之间关系的新信息。
- 阶段三集成:你重复相同的过程,将阶段二中的模型的平均预测提供给最终的“元学习器”模型,该模型应该经过精心挑选,以适应你尝试解决的问题类型。在上面的示例中,比赛者使用线性回归作为最终模型,因为这可能是在初始阶段作为独立模型表现最佳的模型之一。
我们都应该试试吗?
绝对!!对于我的第一次模型堆叠实验,我决定扩展我最新的数据科学项目,这是一个自然语言处理模型,旨在从歌词中预测歌曲的类型。对于该项目,我们预处理了来自八种不同类型的 16000 首歌词列表:嘻哈,乡村,流行,摇滚,金属,电子,爵士和R&B。我们确保在我们的数据集中包含每种类型的 2000 首歌曲,以避免类不平衡的问题。第一步是运行各种基本模型,其预测方法之间的相关性较低,以便能够相应的构建我们的模型堆叠块,请看下面的结果:

接下来,我们决定采用前3个模型并通过广泛的 GridSearch 进行一些超参数优化,以便了解我们的顶级独立模型可以实现的最高精度。结果如下:
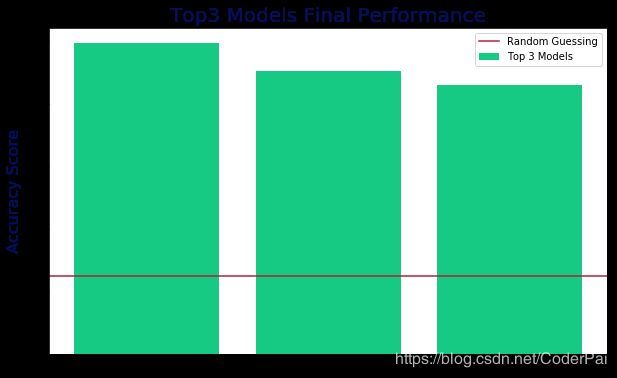
正如你从下面的图表中看到的那样,我们的最佳表现达到了 50%,咋一看似乎不是很高,但考虑到我们的模型视图预测一首歌属于哪种类型。而我们这个准确性已经是随机猜测的四倍了。这意味着大约一半的时间,我们的模型准确的预测了一首歌的类型,仅基于该歌曲的歌词,并且在超过3000首歌曲的测试集上达到了 50% 的测试准确度,这个结果已经相当好了。
首先,我选择结合并平均我的三个最弱学习器的预测:随机森林,adaboost和KNN分类器,并构建一个新的数据框架,我可以提供给我们最强大的学习器。代码如下:
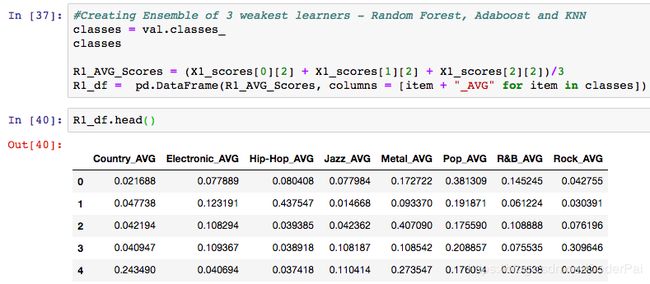
上表中的每一列是八个类型中的每一个的平均预测系数,并且每一行是具有对应的真实类型的歌词,存储在作为类标签列表的单独的 y 变量中。
接下里,我将数据分为训练集和测试集,并且运行模型堆栈的第二阶段,我的强学习器:GradientBoost 和朴素贝叶斯,使用来自弱学习器的组合预测来生成一组新的预测。然后,我将第二阶段的预测结果合并到一个最终的数据框架中,我希望将其提供给我的最终元学习器:NN。

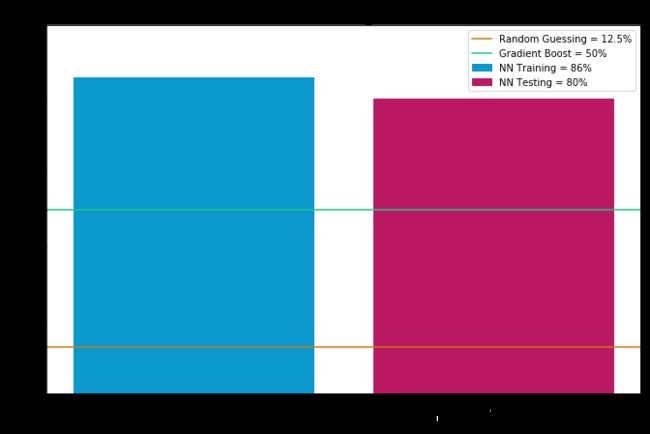
我选择使用神经网络进行模型堆叠的最后阶段,因为 NN 往往在多分类问题上表现很好,并且 NN 非常善于找到隐藏特征并找出依赖变量和自变量之间的复杂关系,我使用 softmax 作为输出层激活函数,因为我们师徒预测八个类别,最终结果如下:
最后的想法
当我在我最初的 NLP 项目中看到这个模型堆叠实验的结果时,我是非常惊讶的,80% 的正确率是在测试数据集上面产生的,该测试数据由 NN 模型以前从未见过的 3600 首歌词组成。交叉验证的训练准确率达到 86% 也是非常令人印象深刻的,让我特别高兴的是训练集和测试集上面没有显著差异,这是非常好的。
我多次检查我的代码和数学,以确保我的交叉验证和训练/测试在每个阶段都有效,因为性能提升 30% 似乎有点不太可能。但我找不到任何我的代码中的错误。因此,我对使用模型堆叠的第一次尝试感到非常高兴。