Gartner连续五年唱衰Hadoop,厂商不以为然!
前不久,笔者调研了国内一线互联网公司的大数据架构(《Hadoop生态系统应用状况大调查:互联网篇!》),Hadoop在其中占据了极其重要的位置,很多人都不看好的MapReduce更是出现在各大互联网公司的大数据架构中。
本文调查了国内部分提供大数据服务的厂商,看看Gartner连续五年唱衰 Hadoop的情况下,他们的大数据平台是如何搭建的?是否基于Hadoop生态系统?Hadoop生态中各组件的存在感有多高?这些架构具备哪些共同特点?(本文内容来源于公开资料整理)
星环科技
星环科技Transwarp Data Hub(简称TDH)是国内落地案例最多的一站式Hadoop发行版,也是Gartner认可的Hadoop国际主流发行版本。说白了,就是Hadoop商业版的发行商之一。TDH解决了Hadoop的性能问题,解决了企业需要MPP或混合架构的问题。对于现在还不太成熟的Spark生态而言,唯一的优势可能就是速度够快,但稳定性不足,企业很难尝试。TDH解决了Hadoop的速度问题,让Spark失去了抗衡条件。
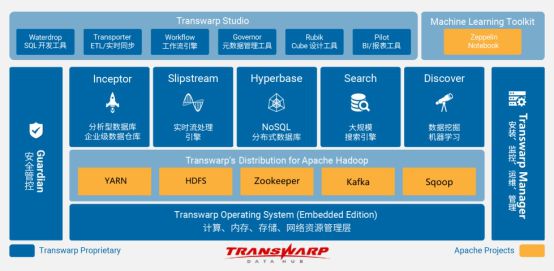
除了Hadoop生态组件,机器学习基本成为大数据平台的标配。Transwarp Discover就是一个分布式的机器学习平台,包含了不少分布式算法库。
目前这个大数据平台已经在广东移动、广东电信、江苏银行、恒丰银行、中泰证券等电信运营商、金融证券、医疗卫生、邮政快递等几大行业应用。
荣之联
荣之联的DataZoo整体分为三层,最底层的基础层基于Hadoop搭建,上层自研了五大引擎,整体加入了自然语言处理的能力。

底层应用的Hadoop生态系统组件基本与星环科技一致,上层的实时流处理引擎也有异曲同工之妙。在对荣之联大数据专家的走访中,笔者了解到不少企业用户对实时流处理具有很高的需求,这在很多互联网公司的大数据架构图中也有体现,这也成为很多大数据厂商共同的发力点。
目前DataZoo已应用于公安、证券、电商、新媒体、车联网及生物医疗等多个行业。
新华三
新华三的H3C DataEngine平台产品同样基于Hadoop生态,集成了MapReduce、Spark、Storm、Tez等多种计算引擎,利用YARN资源管理组件统一管理调度。
此外,该大数据平台产品在数据分析挖掘方面同样提供了机器学习的能力。支持R语言、集成机器学习算法库Mahout和Spark MLlib,包括一些常用的聚类分析、分类算法等机器学习算法;流式计算引擎同样是标配。
目前看起来似乎仅仅应用在政务、公安和高校三个领域。
百分点
百分点是国内大数据和人工智能技术与应用服务商,百分点的大数据操作系统(BD-OS)架构模块化清晰,机器学习、分布式数据库KHan和数据服务都是可独立使用的模块:
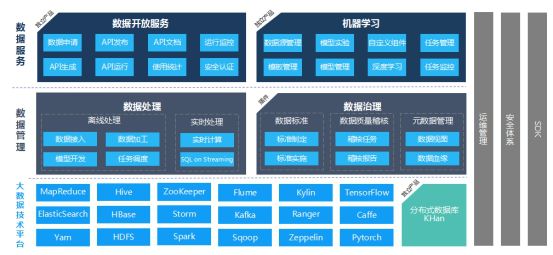
底层的大数据技术平台基本可以分为Hadoop生态组件和机器学习组件,中间层同样加入了实时处理能力,上层也提供机器学习的能力。百分点最大的特点在于它的模块之间非常灵活,企业用户可以各取所需。其他厂商或多或少都具备这项能力,只是没有在架构图中一目了然的体现出来。
目前主要应用于银行、政府部门、酒店、百货、Wi-Fi运营商、媒体、制造业等行业。
联想
2011年8月,联想正式启动大数据建设。联想的企业级大数据分析平台主要包括6大产品线:大数据分析应用套件、大数据能力开放平台、大数据计算平台、数据采集转换套件、数据资产管理平台以及系统运维监控中心。
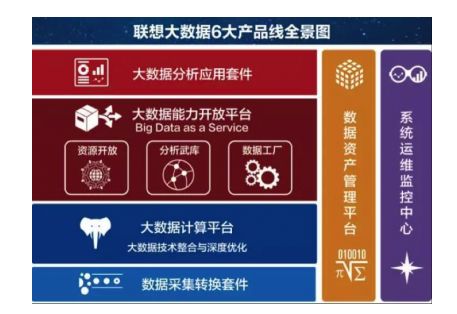
整体同样基于开源生态搭建,其中的计算平台 Descartes基于Hadoop生态系统。在早期的平台资料中,我们只能看到这六大产品线的介绍。现在LEAP同样内置深度优化的机器学习框架及算法库,具备批量、实时计算技术。
由于并没有寻到联想大数据平台更详细的架构图,所以此处对整体架构不做过多分析。
探码科技
探码科技属于初创企业中的黑马,其Datale大数据应用平台是一款基于Hadoop的开源计算框架,集成了社区几十个成熟的Hadoop子项目。

探码科技的大数据架构层次比较清晰,同时添加了机器学习引擎和自然语言处理引擎。但是,整体架构似乎与前几家厂商的有些不同。据悉,探码科技的优势市场在国外,比如美国的律师平台、医生平台和酒店等等,现在也在努力开拓中国市场。
浪潮
浪潮是一家老牌的云计算和大数据厂商,其云海Insight大数据解决方案同样提供主流的Hadoop、Spark、MPP等架构套件。

标配的流式计算和机器学习同样出现在浪潮的大数据平台架构图中,目前主要应用领域仍然是金融、电信、政务、医疗等行业。
用友
用友大数据处理平台UDH基于Hadoop开源产品体系,从其官网公布的架构图不难看出,Hadoop占据了用友大数据平台的重要位置:

用友最擅长的是金融财务方向,其大数据平台虽然功能不多,但针对报表展现、数据分析方面进行了不少优化,明显是有领域倾向性。
总结
从上述几个大数据服务厂商的架构图不难看出:Hadoop、实时流处理以及机器学习能力几乎成为标配,每一个大数据架构都基于庞大的Hadoop生态组件,只看底层的话,各大厂商的区别还真不大,只有上层才会有一些区分。
其次,企业用户与互联网公司对实时流处理都具备极高的需求,这在各自的架构图中都有所体现。很多大数据厂商也不过只是Hadoop生态的使用者,相比于调整Hadoop,他们或许更希望在应用层做文章。
最后,机器学习成为了大数据厂商乐于提供的一大功能,很多厂商甚至可以单独提供机器学习或自然语言处理的模块。
无论是大数据厂商还是互联网企业,Hadoop都是稳稳的基础层,好像没有人纠结其他选择,也没有人对此有过异议,也没有厂商将关注点放在Hadoop的替代品研究上,难道Hadoop垄断时代就此形成?
你对Hadoop有什么看法?你所在公司目前的大数据平台是否同样基于Hadoop?Hadoop垄断时代到来,你同意这个看法吗?
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31077337/viewspace-2154092/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31077337/viewspace-2154092/