性能测试爬坑之路 15 Analysis 结果分析工具一
关住 公 纵 号 “ 阿蒙课程分享 ” 获得学习资料及趣味分享
性能测试做的事情
1.对系统施加压力
2.分析系统的瓶颈(没有最好)
3. 生成测试报告(就是有理有据的说为什么这个系统好,为什么这个系统有问题,问题到底出在什么地方)
Analysis 能够帮助我们更准确更清晰的获取到这些性能数据,辅助我们生成性能测试的报告
Analysis 只是提供了数据的展现,但这写数据关系怎么样却不能展现,这就是需要我们学习的更重要的东西,我们通过这些数据怎么可以看出一些规律,他后台性能的一些状况,这些是需要我们特别关注的非工具能够提供的点
这篇文章主要笼统的看一下 Analysis 这个模块具体操作是怎么样的
要让 Analysis 工作首先我们要有脚本,所以我们把整个过程串一遍,
下面我们就用如下的脚本做一个性能测试的实施
我们可以对这个首页面进行关联,找出用户登录成功后的标记,并尽可能的模拟用户真实的场景,
然后我们在 controller 里面进行运行,获得一些数据,在 Analysis 看看这些性能数据怎么使用
这个脚本没有集合点,我们暂时不关注集合点这个用力场景,
我们设置场景,每 15 秒加 5 个,至于 remp up remp down 的策略到底是什么样的,后面文章再说,
这节课我们只关注 Analysis 和结果分析上面,运行 5 分钟,然后让他慢慢停止,因为只要收集到数据就可以
基本的场景设计就先这样
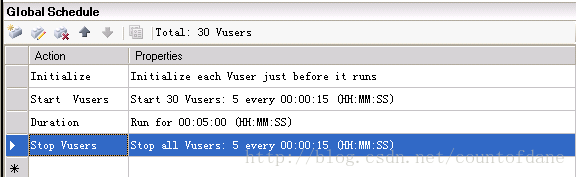
我们检查一下 runtime setting 里面有没有问题
运行一次,没有问题
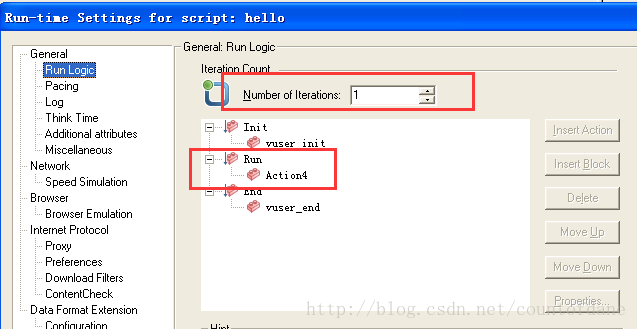
输出标准日志,没有问题
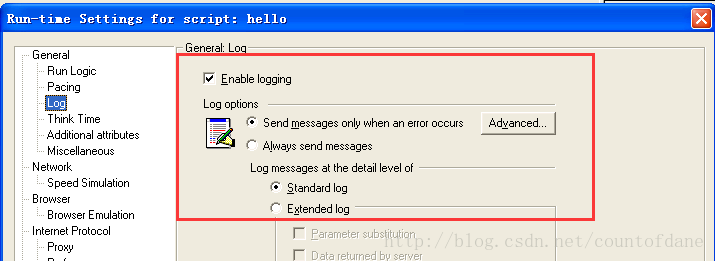
思考时间,随机数
带宽设置:最大 没有问题
浏览器模拟保持默认的选项
然后我们就可以看到脚本的一个状态
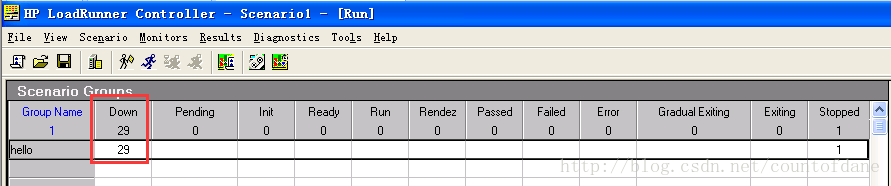
down 表示还没有启动
pending 正在准备
init 表示初始化,已经启动
ready 就绪
run 正在发请求
但凡发请求我们就可以看到一些基础数据了
rendez 表示集合
后面几个字段是虚拟用户运行结果的状态,成功的失败还是脚本报错,如果所有用户顺利的话,直接到 stopped 停止
这是我们关于虚拟用户的一个状态,我们根据这些状态,可以在 contronller 里面对脚本进行调试,调试过程中我们要特别注意状态是否跟我们设计的场景是符合的,有没有出现我们的场景设计跟我们这里的状态不匹配,因为这样就可以出现问题,包括运行的时候这里报的错误我们也要留意
我们忽然发下这里出现了错误,这个怎么整?
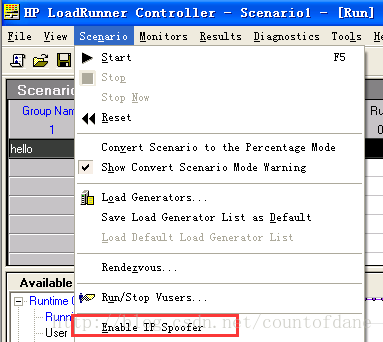
打开这个错误消息我们看看到底出了什么问题,我们双击这个错误消息我们看看这个错误消息说什么,没有见过的问题,不要害怕,这些问题很可能别人也遇到过了,百度一下就可以了,搜索结果最后确认问题为我们用了 IP 欺骗,我们申请的 很多IP 是跟有线网卡绑定的但是我们的有线没有建立连接,我们现在用的是无线链接,以后注意
我们这里用不到 IP 欺骗,所以我们这里关闭掉 IP 欺骗功能就可以了
注意:访问主机名没有问题,但是访问 localhost 它其实没有走物理网卡,它走了虚拟的网卡,所以我们录制脚本的时候一定要注意我们这里一定不要用 localhost 这是不符合真是场景的,真是的情况是即使是在本机,你也应该用你的机器名或者IP 地址,这个机器名跟网络上的域名没有本质的区别,都是同一个东西,如果你访问的是另一台用它的 域名 用它的 ip 但是你不会用它的localhost ,它不会走物理网卡,它走的是 127.0.0.1 这个特殊的虚拟网卡,根本就不存在这么一个网卡,还有一种情况是,我们有 loadgenerate 负载生成器,他会发送请求给服务器,如果是我们在本机录了一个localhost ,当我们把脚本分给不同的负载生成器时候,他们在做什么,他们就相当于是在给自己的电脑上发请求,可能吗?肯定有问题,因为他们要访问的是同一个服务器,所以说这里也是要注意的地方,无论你处在什么情况你都不能用localhost,如果用到其他的负载生成器,一定要保证负载机一定可以 ping 通服务器
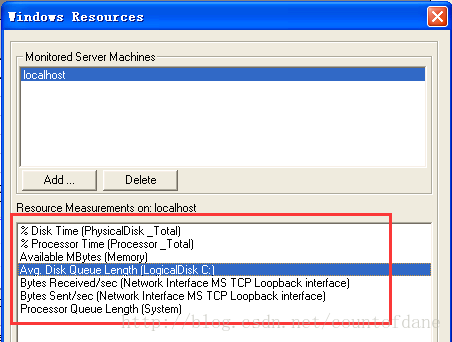
这次运行之前我们顺带着监控几个window 的性能指标,邮件 add measurements
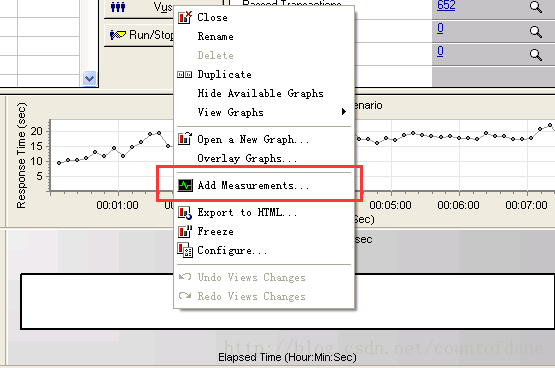
添加主机 localhost
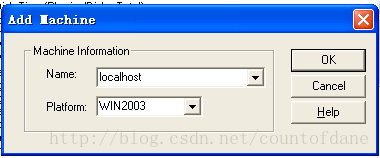
默认给我们添加了很多监控指标,但是不见得都是有用的,
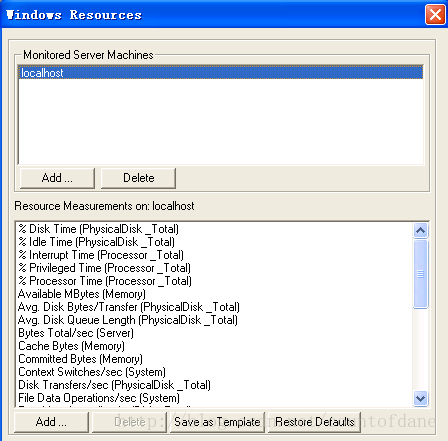
disk time 硬盘读写的时间
idle time 硬盘空闲的时间(有硬盘的读写时间,空闲时间可以不需要了)
interrupt time 处理器的中断时间我们不用去关注
privileged time 处理器的私有的时间(我们不去关注,我们只关注处理器 cpu 的一个占有率 Processor time 还有一个处理器的一个队列长度 processor queue length )
Available MBytes 内存的大小
其他的都可以删掉了
添加一个网卡流量的指标,选择 network interface
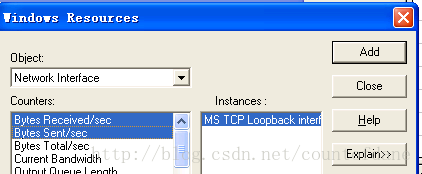
选择接受和发出去的流量,注意这里的产品经历可能脱离群众了,这里很变态的需要点击下ADD 然后点击 close
这样我们就绑定了网卡的流量,但是注意,这里的网卡的流量是跟具体的某块网卡绑定的,所以现在
总结我们只需要监控:
disk time 硬盘读写的时间
Processor time 处理器 cpu 的一个占有率
processor queue length 处理器的一个队列长度
Available MBytes 内存的大小
网卡发送的流量
网卡接收的流量
disk queue length 平均硬盘队列
这些指标是刚开始我们比较关注的,因为还是要跟 analysis 连起来一起走一遍,所以我们就先监控这些指标,关于脚本这边我们其实已经改过了,我们应该重新加载一下这个脚本,运行这个场景
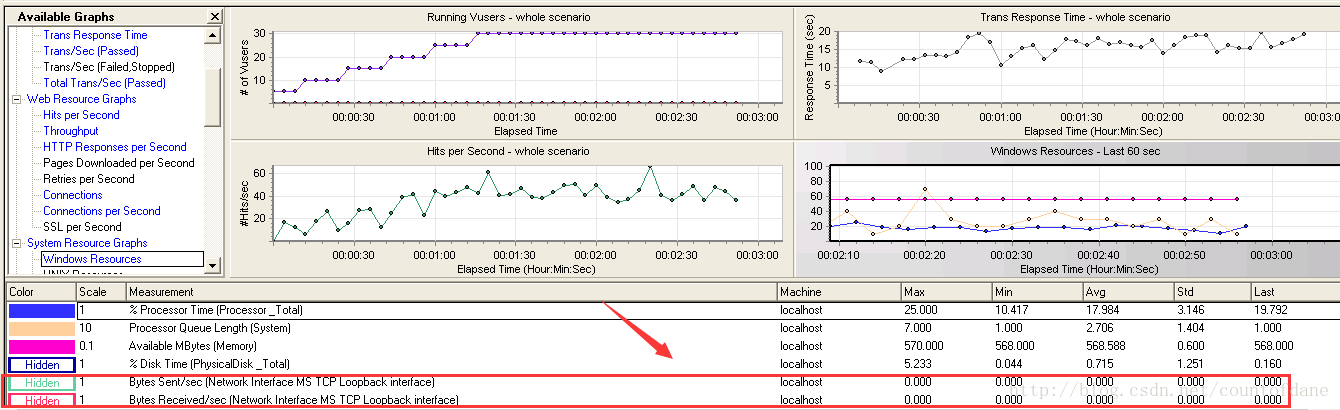
我们可以看到这里的物理网卡的接收数据,发送数据全部是零,因为他根本就没有走这块物理网卡,所以是这样一个问题,我们一定要有这种意识,“什么原因?”这里为什么全是零,这些零监控起来有什么意义,没有意义,因为我们本身监控网卡就监控错了,当然也是我们的脚本开发的有问题,所以我们很难说我们把脚本和场景设计完全的独立分开,我们的脚本里面本身也有很多点去关注,关注到场景,关注到性能测试的执行的过程,这相当于是一个脚本的基础,脚本写好了之后我们在 controller 里面运行也需要注意跟脚本的匹配,他们之间是相互影响的
我们之前说过,这边蓝色显示的是常用的前端的性能指标,而 windows resource 监控到的是我们的服务器的性能指标,它是属于后端的,所以对于我们的指标体系监控和分析来说,咱么既要监控前端又要监控后端,而且前端和后端指标是相互动态影响的,这个是比较费解的,这是我们 analysis 这门课程更重要给大家去讲的,analysis 的基本的应用反而倒是简单,但是后面的东西就比较饶了,需要我们逻辑上是清楚的而且是静下心来,动手确认过,实验过的,才能够真正的去理解他们,
这是脚本开发好确认没有问题,在 controller 做好调试我们确认也没有为你之后,该监控的指标我们把他监控起来,这个时候我们正确的运行,
通常建议大家一次完整的性能测试一般需要半个小时(至少)否则达不到测试目的,让他在相对稳定的状态下去收集一些性能数据,
运行的结果是保存在 result setting 里面设置的目录下
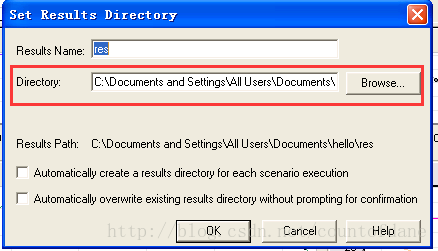
默认使用 Microsoft Access 数据库保存的,
保存了之后我们就可以点击 analyze results 对监控到的指标数据进行分析
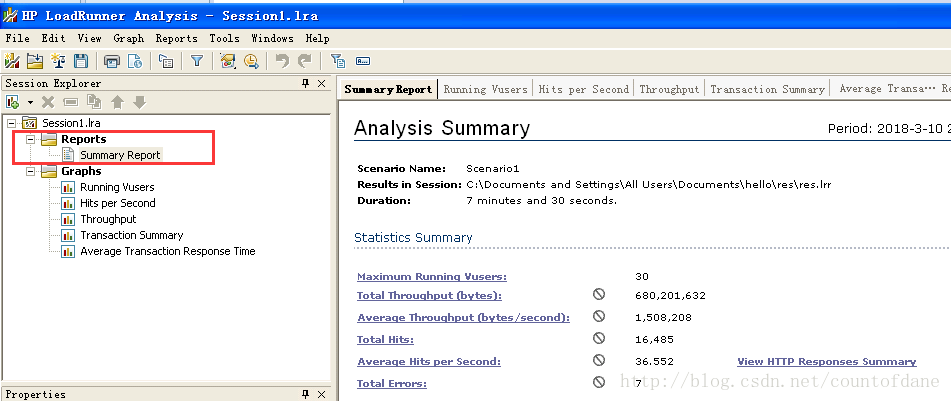
这边是我们获取到的摘要性的数据
下面依次是 虚拟用户的一个数量,运行情况
每秒点击事务的情况
吞吐量的情况
事务的一个摘要
我们定义了homepage login 和 post 三个事务 ,他们全都是成功的
事务的响应时间也都有
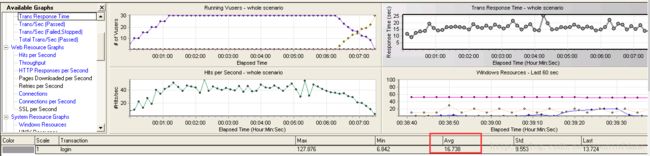
注意这里的响应时间跟我们的 controller 里面监控到的响应时间有点差别,其实这是我专门领出来,大家可能不会注意,大家可以看看在 controller 里面我们 homepage 的平均响应时间 16.73
在 anlysis 里面平均响应时间是 9.41
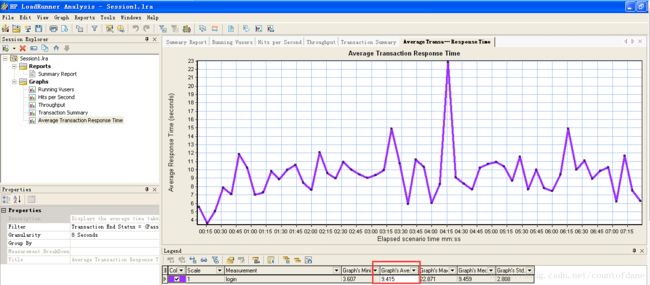
什么原因?这两个数据不一样,差别还很大,真实的响应时间是 9.415 controller 里面的数据是 16.73 秒
打开脚本我们看下
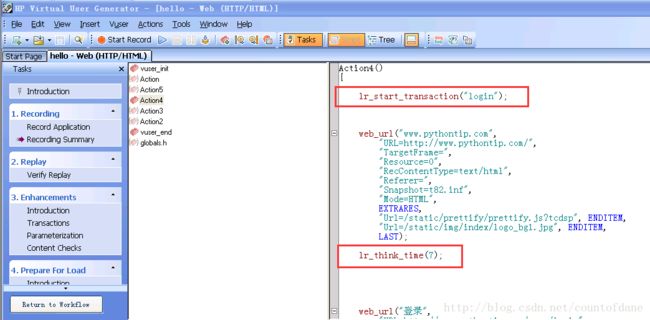
我们是把思考时间放在了事务里面,那么在 controller 里面统计到的是有包含思考时间的,而 analysis 默认是给我们去掉思考时间,所以我们看到的是一个真实的,
我们可以右击图形 选择 set filter
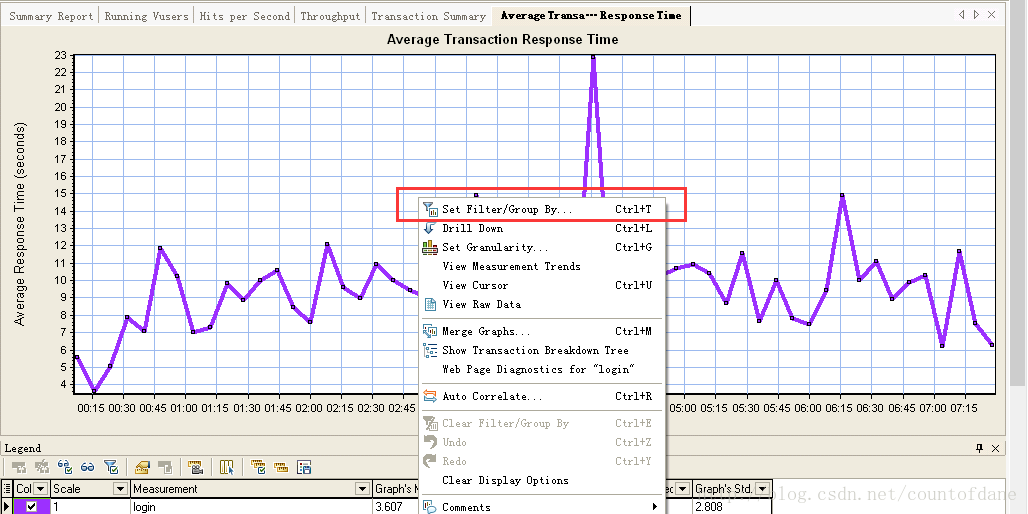
我们选择包含思考时间
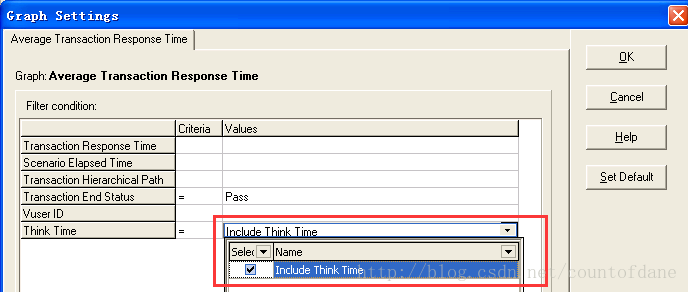
这样我们看到的就是一个真实的数据了
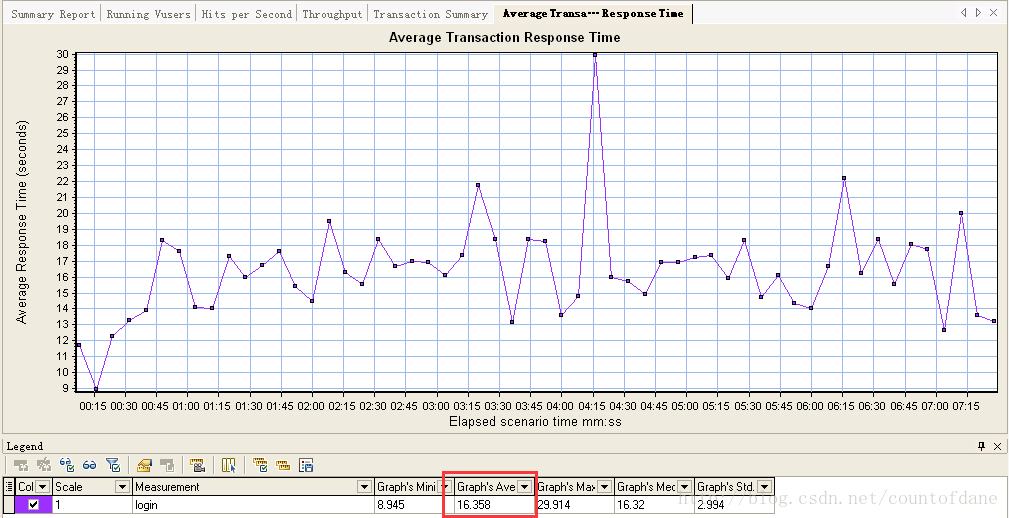
稍微有些差别是跟我们数据的采样间隔有关系的,这个问题就不大了,这是很正常一个事情,
所以我们一定要清楚一点这里面包含的数据是不是准确的
我们是应该把思考时间去掉的,因为思考时间不应该所做服务器的响应时间里面
好的 大的流程就这样了