李宏毅《机器学习》2019
文章目录
- 1. Anomaly Detection 异常检测
- 异常检测不能看做二分类的原因
- 2. Attack & Defense 攻击和防御
- 物理世界中的攻击需要考虑更多
- 防的两种策略:
- 被动防御
- 主动防御
- 3. Explainable ML 可解释学习
- 遇到错误怎么办?
- 可解释学习 ≠ 完全可解释
- explainable v.s. powerful
- local explanation:
- 攻击解释性?!
- global explanation:
- 用可解释模型去解释不可解释模型
- 4. 终身学习
- Catastrophic Forgetting 灾难性遗忘
- life long learning和transfer learning的区别
- future work
- 5. 元学习
- MAML和pre-training
- MAML、Reptile、Pre-train
视频链接
1. Anomaly Detection 异常检测
novelty, exception, outlier
异常检测不能看做二分类的原因
- 异常类不止1类
- 异常类样本难收集
2. Attack & Defense 攻击和防御
Motivation:
- labs->real world
- robust
- malicious attack
L-infinity 适合图像攻击
d ( x 0 , x ′ ) = ∣ ∣ x 0 − x ′ ∣ ∣ ∞ = max { Δ x 1 , Δ x 2 , Δ x 3 , ⋯ } d(x^0, x') = ||x^0-x'||_{\infty} = \max{\{\Delta x_1, \Delta x_2, \Delta x_3, \cdots\}} d(x0,x′)=∣∣x0−x′∣∣∞=max{Δx1,Δx2,Δx3,⋯}
L2范数不适合图像攻击的小例子,每个像素修改一点和一个像素修改很多,L2范数变化完全一样,但是视觉效果相差很大。
物理世界中的攻击需要考虑更多
针对人脸识别系统的“眼镜”攻击:物理世界的限制
- 有效性(多角度有效)
- 鲁棒性(不是像素,是色块,可被相机捕获)
- 可行性(可打印颜色);
针对交通标志的攻击:【自动驾驶】贴一些小补丁,让系统认为是另一种标志。
Defense 防御
防御很难。
weight regularization, dropout, model ensemble对对抗攻击不能够完全防住。
防的两种策略:
- 被动防御: 异常检测的特例。
- 主动防御: 训练时加入防御。
被动防御
- filter
- scale
这些策略,不会对正常图片有很大的影响;对攻击图像有效果。
主动防御
思想:找出漏洞,补起来。
在训练过程中,把攻击数据作为数据,进行数据增强加到训练数据中,不停迭代,对之前发现的漏洞进行补劳。
但是,防御仍然很难。假如你的防御是针对攻击A,那可能对攻击B防御效果不好。
3. Explainable ML 可解释学习
可解释学习就是,不仅要让模型知道图片是一只猫,还要让模型知道为什么图片是一只猫。
常见应用:录用员工、罪犯假释、拒绝贷款、医疗诊断
遇到错误怎么办?
unexplainable ML:暴力调参
explainable ML:根据解释改变模型
可解释学习 ≠ 完全可解释
深度学习是黑盒子不可解释,但是人脑也是黑盒子。所以,可解释学习的目标是让人觉得舒服(爽)。
explainable v.s. powerful
| 模型指标 | 可解释 | 不可解释 |
|---|---|---|
| 能力强大 | 决策树 | 深度模型 |
| 能力有限 | 线性模型 | - |
local explanation:
object X ⇒ \Rightarrow ⇒ Components: { x 1 , . . . , x n , . . . x_1, ..., x_n, ... x1,...,xn,...}
判断局部重要性的简单思想:去掉修改某一个部分。
方法1:
例如用灰色图片来覆盖狗,车,人的某一个部分,然后看预测的准度。
注意: 灰色方块的大小很重要,颜色也很重要。不同的指标得到的结果不同。
方法2:
计算扰动对结果的影响,即计算梯度。
∣ ∂ y k ∂ x n ∣ |\frac{\partial y_k}{\partial x_n}| ∣∂xn∂yk∣,得到
显著性图。
方法缺点:梯度饱和;解决方法:integrated gradient
攻击解释性?!

加入一些noise,让分类结果不变,但是saliency map变化很大。
global explanation:
Question: what do you think a cat look like?
Activation Maximization激活最大化
找到使得类别输出激活最大的图像输入。

可能令人很失望!!!

加入“长得像数字”正则项。
用可解释模型去解释不可解释模型
- 显然,线性模型是可解释的。问题:线性模型并不能够模拟神经网络。
退而求其次,我们只模拟黑盒子的一部分。举例的方式是LIME。先确定一个要分析的数据点,然后在附近采样一些点,然后用可解释的模型(如线性模型)来拟合这些数据。
- 用决策树来解释神经网络。问题:我们不希望树太大。
很神奇!!!训练一个知道自己要被decision tree解释的network,然后控制他的深度。Tree regularization,用一个网络,输入是网络的参数,输出是解释该网络的树的复杂度。
4. 终身学习
Life Long Learning (LLL)
continuous learning, never ending learning, incremental learning
要做到终身学习,需要有以下几个要求:
- knowledge retention 知识保持:不固执
- knowledge transfer 知识迁移
- model expansion 模型扩展:有效率扩展
Catastrophic Forgetting 灾难性遗忘
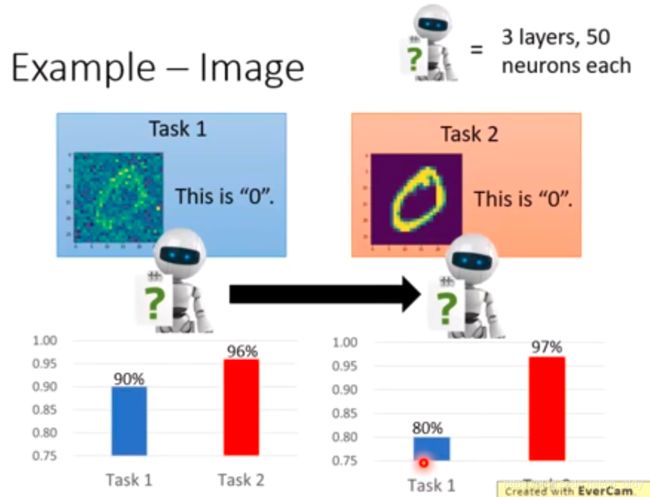
模型会忘记知识,比如在task1上训练的模型,继续在task2上微调之后,对第一类的分类精度会降低很多。这在ZSL到GZSL的扩展当中,也会出现。
奇怪的地方:先学任务1再学任务2会忘记知识,但是同时学任务1和任务2效果还不错。
LLL的上界是多任务学习!!!
elastic weight cosolidation (EWC)
basic idea: 和旧知识相关的权重不修改,只修改不重要的权重。每个权重有一个守护 b i b_i bi。 b i b_i bi可以是权重的二次微分。
参考方法:SI,MAS(不需要标注)
life long learning和transfer learning的区别
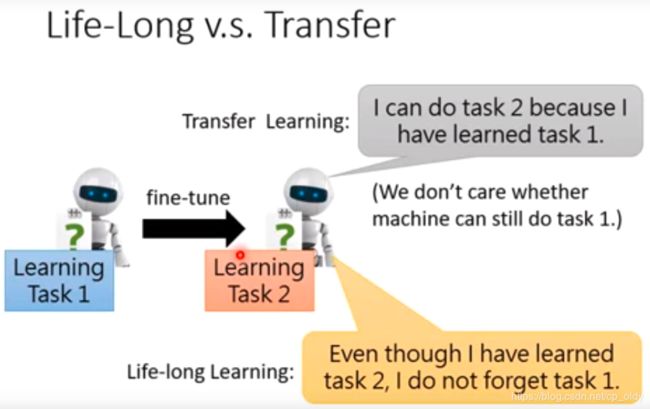
也就是说,其实gzsl属于lll的范畴。
future work
以上只讨论了任务学习的个数,并没有讨论任务学习的顺序。一个新的方向就是curriculum learning,针对难易不同的任务,学习顺序不同。
5. 元学习
元学习和机器学习的区别:
机器学习:根据数据找一个函数f的能力
f(x)=‘cat’
元学习:根据数据找一个找一个函数f的函数F的能力
F(X)=f*
三步走
- 收集训练任务和测试任务(验证集)
- 评估F的方式
Defining the goodness of a function F
L ( F ) = ∑ n = 1 N l n L(F) = \sum_{n=1}^{N} l^n L(F)=n=1∑Nln
把N个任务的loss相加。 - 选择合适的F*
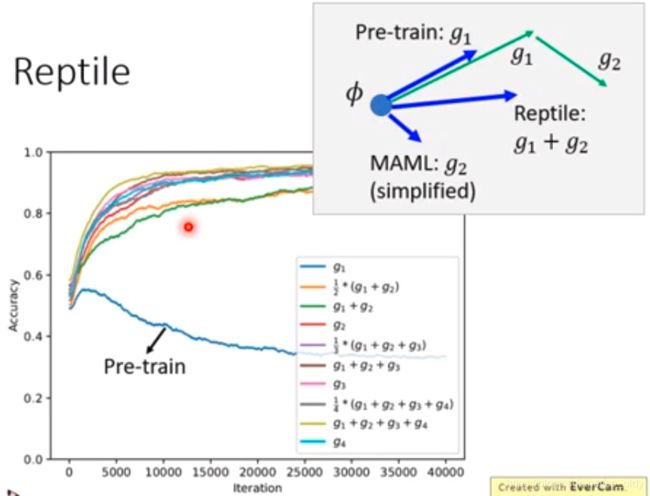
MAML和pre-training
MAML是要找到一个初始化的参数 ϕ \phi ϕ,经过训练后能够找到最好的 θ n \theta^n θn对每个任务效果好。关注的好的初始点,重点在训练之后
pre-training是要找到一个初始化参数 ϕ \phi ϕ对所有任务效果好。关注的是现在的效果,不继续训练
MAML、Reptile、Pre-train