Kafka多数据中心部署灾备三要素
AI前线导读: 想象一下,灾难性破坏——比如灾难性硬件故障、软件故障、停电、拒绝服务攻击或其他一些事件——导致一个装有Apache Kafka集群的数据中心完全失效。不过,另一个数据中心的Kafka继续在运行中,它已经拥有原始数据中心的数据副本,这些数据是从具有相同名称的主题上复制过来的。客户端应用程序从故障集群切换到正在运行的集群,并根据在原始数据中心中停止的位置自动恢复在新数据中心的数据消费。企业最大限度地减少了灾难导致的停机时间和数据丢失,并继续运行它们的任务关键型应用程序。
更多干货内容请关注微信公众号“AI前线”(ID:ai-front)
说到底,灾难恢复计划的目的就是要让业务能够持续运行,因为数据中心停机和数据丢失可能导致企业收入遭到损失,甚至完全停止运营。为了最大限度地减少灾难导致的停机时间和数据丢失,企业应该要制定业务连续性计划和灾难恢复策略。
总的来说,你应该要采取三项措施来进行灾难规划:
设计多数据中心解决方案;
制定故障转移和故障恢复手册;
测试!测试!测试!
1.设计多数据中心解决方案
单个数据中心的Kafka通过集群内数据复制提供消息持久性。在进行数据复制时,为生产者设置acks = all选项可以带来最强壮的可用保证,因为它可以确保集群中的其他代理在首领代理向生产者做出确认之前接收到数据。
单数据中心设计可以提供针对代理故障的保护。如果客户端应用程序正在通过某个代理连接到集群,并且这个代理发生了故障,则还会有另一个引导代理可以保证客户端连接到集群。但是,如果整个数据中心出现故障,那么单个Kafka集群就也很容易发生失效。
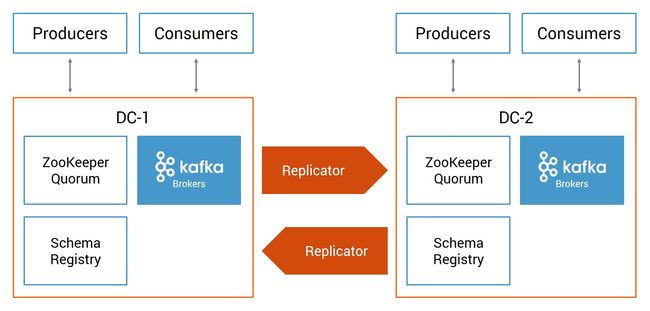
在设计多数据中心时,不是只在单个数据中心中部署Kafka集群,而是在两个或更多数据中心部署,它们在地理位置上是分散的。它们可以在自有数据中心或在Confluent Cloud中。Confluent Replicator可在站点之间同步数据,当一个数据中心发生部分或全面故障时,应用程序可以转移到其他数据中心。
为了帮助你设计多数据中心解决方案,我们发布了白皮书“Disaster Recovery for Multi-Datacenter Apache Kafka Deployments”的更新版本。白皮书的最新版本介绍了多数据中心部署的设计和配置,包括多数据中心的设计、集中式schema管理和客户端应用程序的开发。
它还详细介绍了Confluent Replicator 5.0的新功能,包括:
防止主题的循环复制:在双活(active-active)架构中双向运行Replicator,它可以防止无限循环复制。否则的话,如果你不使用特殊主题命名模式,可能会导致无限循环复制,也就是将数据从cluster-1复制到cluster-2,然后再将cluster-2中的相同数据复制回cluster-1,然后再次从cluster-1复制到cluster-2。
时间戳保留:原始集群在生成消息时记录的时间戳被传到了目标集群,这让流式应用程序能够基于原始时间戳进行操作。
消费者偏移量转换:已提交的偏移量被复制到目标集群,并对其进行转换,让偏移值对新集群来说是有意义的。这样消费者在切换到目标集群后可以自动恢复消费消息。
你的架构会因为你的业务需求的不同而有所不同,但你可以应用白皮书中提到的构建块来增强灾难恢复计划。
2.制定故障转移和故障恢复手册
当灾难发生时,你需要根据行动手册准备好采取特定的行动。如何将客户端应用程序转移到新数据中心?如何启用Confluent Schema Registry注册新schema?你需要做些什么才能让消费者开始在新集群中恢复数据消费?最重要的是,在原始数据中心恢复后,你如何切换回去?
白皮书中介绍了基本的多数据中心原则,解释了在一个数据中心发生故障时应该怎么办,以及在原始数据中心恢复之后如何切换回去。你应该在你的实际部署当中应用这些原则。
如何进行手动或自动故障转移取决于恢复时间目标(RTO),它是指完成故障转移的时间点。理想情况下,灾难发生后应该尽快将停机时间降至最低。RTO越是激进,你就越是需要自动化的工作流程,这取决服务发现机制和应用程序的故障转移逻辑。
恢复点目标(RPO)是指应用程序可以使用已知数据恢复到的灾难发生前的最近一个时间点。通常情况下,尽可能接近灾难发生前的时间,以尽量减少数据丢失。特别是如果你利用Replicator 5.0提供的功能,它将极大简化故障转移和故障恢复的工作流程,并改善这些恢复时间。
3.测试!测试!测试!
使用白皮书中提到的构建块来配置生产环境,然后模拟灾难。遵循整个工作流程:关闭集群,对应用程序进行故障转移,确保它们能够成功处理数据,然后进行故障恢复。
工作流程的每一个步骤都非常重要,主要是因为它可以确保多数据中心设计的稳健性,并可以满足你的特定业务需求。每个部署都略有不同,为了满足业务需求,客户端应用程序的开发方式也略有不同,因此你需要确保一切正常。进行灾难模拟的第二个原因是这样可以测试你的故障恢复手册,确保每个步骤都被记录在手册中。
为了帮助你进行测试,Confluent在GitHub存储库中提供了一个Docker配置文件。免责声明:这仅用于测试——不要将此Docker配置文件用在生产环境中!
Docker提供了一个双活多数据中心环境,利用了新的Replicator功能,例如通过起源标头来防止主题循环复制,以及时间戳保留和消费者偏移量转换。
要进行测试,请根据你的部署环境调整配置文件,并运行客户端应用程序。你还可以使用提供的示例客户端应用程序来查看它是如何在新数据中心中根据其在原始数据中心中停止的位置恢复数据消费的。然后,模拟故障转移和故障回复,测试手册并验证它的有效性。

总之,灾难恢复计划通常需要在多数据中心部署Kafka集群,并且数据中心在地理位置上是分散的。采取以下三个步骤为灾备做好准备:
设计多数据中心解决方案;
制定故障转移和故障恢复手册;
测试!测试!测试!
英文原文:
https://www.confluent.io/blog/3-ways-prepare-disaster-recovery-multi-datacenter-apache-kafka-deployments