【Python】有道翻译的爬虫实现(后篇)
前面说到,有道翻译和百度翻译不同
(百度翻译是模拟iPhone手机,可能百度翻译用Pc端也会有类似的问题,有道翻译的User—Agent是Pc端)
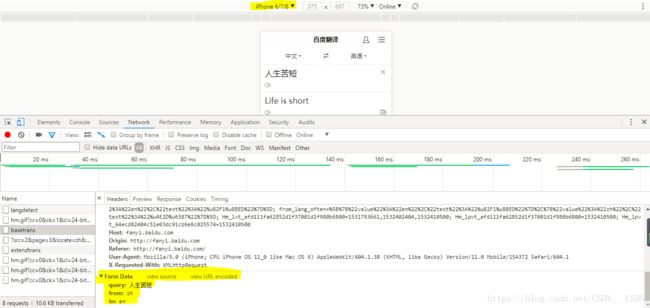

每一次的salt和sign都不一样,这是什么原因产生的呢?
一、每一次翻译的时候浏览器会从服务器获取这两个值,导致这两个值不一样
二、按照一定的规则在本地生成
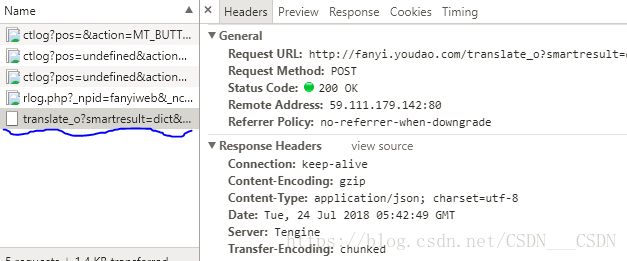
画波浪线的是请求翻译的,其他的都是没有任何数据返回的,所以应该是第二种情况。
接下来我们就查看网页源代码,最底端。

在新建标签页中打开,然后http://tool.chinaz.com/Tools/jsformat.aspx把代码复制进去后,点击格式化:

新建一个txt文件,找到里面有关salt的内容,我一共找了三个
t.translate = function(e, t) {
T = u("#language").val();
var n = b.val(),
r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10)),
o = u.md5(S + n + r + D),
a = n.length;
if (L(), w.text(a), a > 5e3) {
var l = n;
n = l.substr(0, 5e3),
o = u.md5(S + n + r + D);
var c = l.substr(5e3);
c = (c = c.trim()).substr(0, 3),
u("#inputTargetError").text("鏈夐亾缈昏瘧瀛楁暟闄愬埗涓�5000瀛楋紝鈥�" + c + "鈥濆強鍏跺悗闈㈡病鏈夎缈昏瘧!").show(),
w.addClass("fonts__overed")
} else w.removeClass("fonts__overed"),
u("#inputTargetError").hide();
f.isWeb(n) ? i() : s({
i: n,
from: _,
to: C,
smartresult: "dict",
client: S,
salt: r,
sign: o,
doctype: "json",
version: "2.1",
keyfrom: "fanyi.web",
action: e || "FY_BY_DEFAULT",
typoResult: !1
},
t)
},
------------------------------------------------------------------------------------------------------------------
function(e, t) {
var n = e("./jquery-1.7");
e("./md5");
e("./utils");
var r = null;
t.asyRequest = function(e) {
var t = e.i,
i = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10)),
o = n.md5("fanyideskweb" + t + i + "ebSeFb%=XZ%T[KZ)c(sy!");
r && r.abort(),
r = n.ajax({
type: "POST",
contentType: "application/x-www-form-urlencoded; charset=UTF-8",
url: "/bbk/translate_m.do",
data: {
i: e.i,
client: "fanyideskweb",
salt: i,
sign: o,
tgt: e.tgt,
from: e.from,
to: e.to,
doctype: "json",
version: "3.0",
cache: !0
},
dataType: "json",
success: function(t) {
t && 0 == t.errorCode ? e.success && e.success(t) : e.error && e.error(t)
},
error: function(e) {}
})
}
}),
---------------------------------------------------------------------------------------------------------------------
function(e, t) {
var n = e("./jquery-1.7");
e("./utils");
e("./md5");
var r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10));
t.recordUpdate = function(e) {
var t = e.i,
i = n.md5("fanyideskweb" + t + r + "ebSeFb%=XZ%T[KZ)c(sy!");
n.ajax({
type: "POST",
contentType: "application/x-www-form-urlencoded; charset=UTF-8",
url: "/bettertranslation",
data: {
i: e.i,
client: "fanyideskweb",
salt: r,
sign: i,
tgt: e.tgt,
modifiedTgt: e.modifiedTgt,
from: e.from,
to: e.to
},
success: function(e) {},
error: function(e) {}
})
},然后你就可以发现
salt就是当时时间的时间戳再加上一个0-10的随机字符串
"fanyideskweb" + cotent(要翻译的内容) + salt + "ebSeFb%=XZ%T[KZ)c(sy!"(每个人的应该有微小的差别)
sign就是上述这四个相加的MD5值
然后就是在headers的地方带上User-Agent,Referer,Cookie,就可以了(我一开始没带上Cookie一直报错)
下面是代码:
import requests
import json
import urllib.request
import gzip
import urllib.parse
import json
import time
import random
import hashlib
url ="http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
content = input("请输入要翻译的内容:")
S = "fanyideskweb"
n = content
r = str(int(time.time()*1000) + random.randint(1,10))
D = "ebSeFb%=XZ%T[KZ)c(sy!"
sign = hashlib.md5(( S + n + r + D ).encode('utf-8')).hexdigest()
data = {"i": content,
"from": "AUTO",
"to": "AUTO",
"smartresult":"dict" ,
"client":"fanyideskweb" ,
"salt": r,
"sign":sign ,
"doctype":"json" ,
"version":"2.1" ,
"keyfrom":"fanyi.web" ,
"action":"FY_BY_CLICKBUTTION" ,
"typoResult": "false"}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Referer": "http://fanyi.youdao.com/","Cookie": "[email protected]; JSESSIONID=aaaP2Qy4ztAfyfZRXzktw; OUTFOX_SEARCH_USER_ID_NCOO=570232601.9713346; fanyi-ad-id=47865; fanyi-ad-closed=1; ___rl__test__cookies=1532406668184"}
response = requests.post(url,headers = headers,data = data)
html_str = response.content.decode()
dict_str = json.loads(html_str)
print(dict_str['translateResult'][0][0]['tgt'])
可以发现它的“from”和“to”都是AUTO,所以可以自动识别是中文到英文还是英文到中文
参考页面:https://blog.csdn.net/nunchakushuang/article/details/75294947
https://blog.csdn.net/shadkit/article/details/79174948