DBSCAN 密度聚类 Python实现
DBSCAN是一种利用样本“密度”信息进行聚类的算法,有两个超参数,一个是核心点的邻域半径,一个是核心点邻域内拥有的点的个数(包括自己)。
看了网上不少算法流程,大多说得模棱两可。。有的还是错的。。比如将同一个点分入到了两个不同的类,然后把这个两个类“结合”成一个。
我理解的原理就是:
①由邻域半径和点的个数,找到核心点的集合,以西瓜书为例,假设是[3,5,6,8,9,13,14,18,19,24,25,28,29]。
②从该点随机抽出一个点,比如8,找到8邻域内的所有点:[6,7,8,18,19],与整个样本集合取交集,得到一个簇[6,7,8,18,19]。
③把8从核心点去掉,把该簇从整个样本去掉。找到8邻域内中的核心点,这里是[6,18,19],再分别以6/18/19,重复以上过程。
④直到最后找到的点不是核心点。
是个递归的过程。
如图所示:从8出发,找到了[6,7,18,19],7不是核心点,不管,加入簇并从整体样本剔除。再从6出发,找到了[8,19,18,23],8,19,18,已经从整个样本剔除了,所以与整个样本的交集,就是23号,23号不是核心点,所以对于6的搜索完成了,再把23加入到簇并从整个样本剔除。再从18出发,找到了[6,8,12,19,20],6,8,19,已经从整个样本剔除了,交集只有12、20,12和20,又不是核心点,所以对于18的搜索完成,12和20加入到簇,并从整个样本剔除。最后从19出发,找到[8,18,20,10],与整个样本交集只有10,(虽然19也找到了20,但是20已经在簇里面了,而且没在整个样本,交集取不到),所以把10加入到簇。这样,一个簇就聚类完成。结果就是西瓜书的一个簇:![]()


那么,再详细点,第二个簇的生成:假如从核心点3出发,3找到了[4,5,13,14],从核心点5出发,找到了[3,13,14,7],由于7已经在簇1里面了, 而且全集中已经把7剔除了,所以[3,13,14,7]与全集的交集,就取不到7,所以7就忽略了,不被加入到簇2。再从14出发,找到[3,5,21],21不是核心点,14搜索结束。再从13出发,找到[3,5,9,17],17不是核心点,加入,同时9是核心点,又从9出发,找到的16不是核心点,9结束→13结束。所以簇2:![]()
代码如下:距离矩阵如果数据量太大,显然即浪费时间又浪费空间,这里数据量小,就用简答粗暴的办法了。。。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data=pd.read_csv('data\watermelon.csv',header=None)
data=data.values
class DBSCAN():
def __init__(self,epsilon,MinPts):
self.epsilon=epsilon
self.MinPts=MinPts
###距离矩阵
self.dist=0
###所有簇集合
self.k_clusters=[]
###核心点
self.CorePts=np.array([],dtype=int)
###当前样本
self.Samples=0
###当前簇
self.clusters=0
###用来一直往下找核心点
def findDensity(self,point):
###将该核心点从核心点集合去掉
self.CorePts=np.setdiff1d(self.CorePts,point)
###找到该核心点的密度直达点,与样本取交集,即防止点被重复聚类
densityPts=np.where((self.dist[int(point)]= self.MinPts:
self.CorePts=np.append(self.CorePts,idx)
###只要核心点集合不为空,一直找
while(len(self.CorePts)!=0):
self.clusters=np.array([],dtype=int)
c=self.findDensity(np.random.choice(self.CorePts))
self.k_clusters.append(c)
return self.k_clusters 然后,以西瓜书上的例子为例,结果吻合:
model=CBSCAN(0.11,5)
k_clusters=model.fit(data)
plt.scatter(data[k_clusters[0]][:,0],data[k_clusters[0]][:,1],marker='x',color='gray',label='cluster 1')
plt.scatter(data[k_clusters[1]][:,0],data[k_clusters[1]][:,1],marker='o',color='green',label='cluster 2')
plt.scatter(data[k_clusters[2]][:,0],data[k_clusters[2]][:,1],marker='v',color='blue',label='cluster 3')
plt.scatter(data[k_clusters[3]][:,0],data[k_clusters[3]][:,1],marker='^',color='black',label='cluster 4')
plt.scatter(data[10][0],data[10][1],marker='*',color='red',label='anormaly')
plt.scatter(data[14][0],data[14][1],marker='*',color='red')
plt.legend(frameon=False)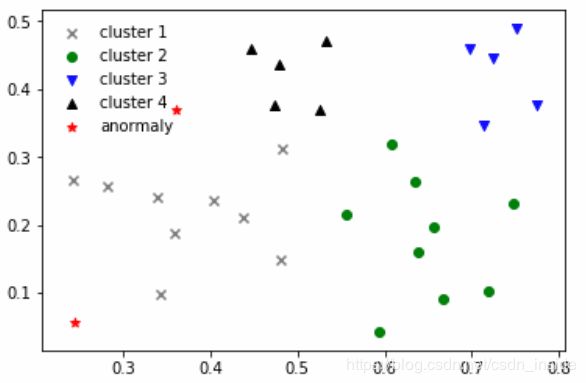

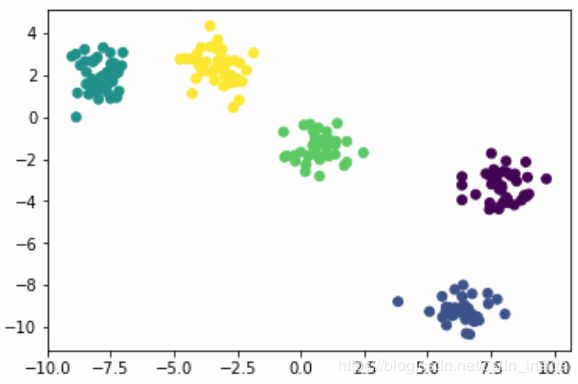
最后,用sklearn随机生成一组数据看看效果:
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=200,centers=5,cluster_std=.7,random_state=6)
plt.scatter(X[:,0],X[:,1],c=y)
model1=DBSCAN(0.75,5)
cluster=model1.fit(X)
###找出未分配到的异常点
sk_clusters=np.array([],dtype=int)
for i in range(5):
sk_clusters=np.append(sk_clusters,cluster[i])
anomoly_point=np.setdiff1d(np.arange(200),sk_clusters)
for i in range(5):
plt.scatter(X[cluster[i]][:,0],X[cluster[i]][:,1])
plt.scatter(X[anomoly_point][:,0],X[anomoly_point][:,1],marker='x',s=100)左图是原图,右图是DSSCAN生成的图,X表示异常的点。
这里一开始也设置eplison=0.11,聚类失败,这个例子中各点距离很明显几乎都大于0.11,改成0.75就行了,所以超参数eplison跟MinPts的调节也很重要。。这里就不多述了。。