[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs
一.结构
Encoder-Decoder LSTM是为了解决NLP问题开发的,在统计机器翻译领域展示出强大的性能。
![[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs_第1张图片](http://img.e-com-net.com/image/info8/0fcac34bf4984462aa429aa5aebe38af.jpg)
这种架构常用于:
- Machine Translation
- Learning to Execute
- Conversational Modeling
- Movement Classification
示例:
model = Sequential()
model.add(LSTM(..., input_shape=(...)))
model.add(RepeatVector(...))
model.add(LSTM(..., return_sequences=True))
model.add(TimeDistributed(Dense(...)))
注意:
1.encoder的输出要求是固定大小的向量,代表了输入序列的内部状态,encoder LSTM的memory cells数目决定了向量的长度。
2.TimeDistributed封装使同样的输出层能被输出序列的每一个元素复用。
3.Encoder LSTM输出是2维,Decoder LSTM输入要求是3维(samples,steps,features),因此不能直接将其连接,需要使用RepeatVector层,将2D输入简单的复制多次转变为3维。
二.加法预测问题
1.问题描述:给定输出的两个字符,计算加法输出:
Input: [ '1' ,'0', '+' ,' 6' ]
Output: [ '1' ,' 6' ]
该问题是一个Seq2Seq问题:
![[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs_第2张图片](http://img.e-com-net.com/image/info8/9695a1ebac284a09b818a914e1f6d7e4.jpg)
为简化问题,将该问题分为以下几步:
- Generate Sum Pairs
- Integer to Padded Strings
- Integer Encoded Sequence
- One hot Encoded Sequences
- Sequence Generation Pipeline
- Decode Sequence
(1)Generate Sum Pairs
from random import seed
from random import randint
# generate lists of random integers and their sum
def random_sum_pairs(n_examples, n_numbers, largest):
X, y = list(), list()
for i in range(n_examples):
in_pattern = [randint(1,largest) for _ in range (n_numbers)]
out_pattern = sum (in_pattern)
X.append(in_pattern)
y.append(out_pattern)
return X, y
#seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print (X, y)
输出:[[5, 10]] [15]
(2)Integer to Padded Strings
from math import ceil
from math import log10
# convert data to strings
def to_string(X, y, n_numbers, largest):
#输入数字表达式转换为字符串的最大长度计算,考虑数字之间的加号
#如n_numbers=3,largest=10,最大字符串长度为8[‘1’,‘0’,‘+’,‘1’,‘0’,‘+’,‘1’,‘0’],如果不满需要补足8位
max_length = n_numbers * ceil(log10(largest+1)) + n_numbers - 1
Xstr = list()
for pattern in X:
strp ='+' .join([ str (n) for n in pattern])
#填充空格符,以保证输入和输出长度相等,这里采用左侧填充,数据字符串在右侧
strp ='' .join([' ' for _ in range(max_length- len (strp))]) + strp
Xstr.append(strp)
#输出数字表达式转换为字符串的最大长度计算,输出的结果中没有符号
max_length = ceil(log10(n_numbers * (largest+1)))
ystr = list()
for pattern in y:
strp = str(pattern)
#填充空格符,以保证输入和输出长度相等,这里采用左侧填充,数据字符串在右侧
strp ='' .join([' ' for _ in range(max_length- len (strp))]) + strp
ystr.append(strp)
return Xstr, ystr
seed(1)
n_samples = 1
n_numbers = 3
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
#print(len(X[0]))
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
print(X, y)
#print(len(X[0]),len(y[0]))
输出:
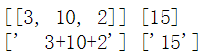
(3)Integer encode strings
def integer_encode(X, y, alphabet):
char_to_int = dict ((c, i) for i, c in enumerate (alphabet))
Xenc = list()
for pattern in X:
integer_encoded = [char_to_int[char] for char in pattern]
Xenc.append(integer_encoded)
yenc = list()
for pattern in y:
integer_encoded = [char_to_int[char] for char in pattern]
yenc.append(integer_encoded)
return Xenc, yenc
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print(X, y)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
print (X, y)
# integer encode
alphabet = ['0','1','2','3','4','5','6','7','8','9','+',' ']
X, y = integer_encode(X, y, alphabet)
print (X, y)

(4)one hot encode
def one_hot_encode(X, y, max_int):
Xenc = list()
for seq in X:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
Xenc.append(pattern)
yenc = list()
for seq in y:
pattern = list()
for index in seq:
vector = [0 for _ in range(max_int)]
vector[index] = 1
pattern.append(vector)
yenc.append(pattern)
return Xenc, yenc
seed(1)
n_samples = 1
n_numbers = 2
largest = 10
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
print (X, y)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
# integer encode
alphabet = ['0','1','2','3','4','5','6','7','8','9','+',' ']
X, y = integer_encode(X, y, alphabet)
print(X, y)
# one hot encode
X, y = one_hot_encode(X, y, len (alphabet))
print (X, y)

将以上过程封装为数据产生函数:
from numpy import array
# generate an encoded dataset
def generate_data(n_samples, n_numbers, largest, alphabet):
# generate pairs
X, y = random_sum_pairs(n_samples, n_numbers, largest)
# convert to strings
X, y = to_string(X, y, n_numbers, largest)
# integer encode
X, y = integer_encode(X, y, alphabet)
# one hot encode
X, y = one_hot_encode(X, y, len (alphabet))
# return as NumPy arrays
X, y = array(X), array(y)
return X, y
# invert encoding
def invert(seq, alphabet):
int_to_char = dict ((i, c) for i, c in enumerate (alphabet))
strings = list()
for pattern in seq:
string = int_to_char[argmax(pattern)]
strings.append(string)
return ''.join(strings)
(5)定义模型
from numpy import argmax
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import TimeDistributed
from keras.layers import RepeatVector
# define LSTM
model = Sequential()
model.add(LSTM(75, input_shape=(n_in_seq_length, n_chars)))
model.add(RepeatVector(n_out_seq_length))
model.add(LSTM(50, return_sequences=True))
model.add(TimeDistributed(Dense(n_chars, activation='softmax')))
model.compile(loss='categorical_crossentropy' , optimizer='adam', metrics=['accuracy'])
print (model.summary())
![[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs_第3张图片](http://img.e-com-net.com/image/info8/093caf1f451049cdb4435dc1c239f75e.jpg)
(6)训练模型
# fit LSTM
X, y = generate_data(75000, n_terms, largest, alphabet)
model.fit(X, y, epochs=1, batch_size=32)
![[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs_第4张图片](http://img.e-com-net.com/image/info8/1baaaf40b2204f19bf570ad02d04de34.png)
(7)评估模型
# evaluate LSTM
X, y = generate_data(100, n_terms, largest, alphabet)
loss, acc = model.evaluate(X, y, verbose=0)
print ('Loss : %f, Accuracy: %f' % (loss, acc*100))
![]()
(8)使用模型进行新数据预测
# predict
for _ in range(10):
# generate an input- output pair
X, y = generate_data(1, n_terms, largest, alphabet)
# make prediction
yhat = model.predict(X, verbose=0)
# decode input, expected and predicted
in_seq = invert(X[0], alphabet)
out_seq = invert(y[0], alphabet)
predicted = invert(yhat[0], alphabet)
print( '网络输出为:% s = % s ( 正确答案为: % s )' % (in_seq, predicted, out_seq))
![[LSTM学习笔记7]How to Develop Encoder-Decoder LSTMs_第5张图片](http://img.e-com-net.com/image/info8/e1f444cdeb7444528a61f4872ff1a2b0.jpg)