Adative-lasso+灰色预测(R)
最近在看特征的选择,看到lasso对特征选择不错,下面直接上干货
数据为广州统计年检2015年数据
目标:
1) 梳理影响地方财政收入的关键特征,分析、识别影响地方财政收入的关键特征的选择模型;
2) 结合目标1的因素分析,对广州市2015年的财政总收入及各个类别收入进行预测。


下面为R语言代码部分
head(data)## x1 x2 x3 x4 x5 x6 x7 x8 x9
## 1 3831732 181.54 448.19 7571.00 6212.70 6370241 525.71 985.31 60.62
## 2 3913824 214.63 549.97 9038.16 7601.73 6467115 618.25 1259.20 73.46
## 3 3928907 239.56 686.44 9905.31 8092.82 6560508 638.94 1468.06 81.16
## 4 4282130 261.58 802.59 10444.60 8767.98 6664862 656.58 1678.12 85.72
## 5 4453911 283.14 904.57 11255.70 9422.33 6741400 758.83 1893.52 88.88
## 6 4548852 308.58 1000.69 12018.52 9751.44 6850024 878.26 2139.18 92.85
## x10 x11 x12 x13 y
## 1 65.66 120.0 1.029 5321 64.87
## 2 95.46 113.5 1.051 6529 99.75
## 3 81.16 108.2 1.064 7008 88.11
## 4 91.70 102.2 1.092 7694 106.07
## 5 114.61 97.7 1.200 8027 137.32
## 6 152.78 98.5 1.198 8549 188.14Data <- data
###数据概括性度量
Min=sapply(Data,min) #最小值
Max=sapply(Data,max) #最大值
Mean=sapply(Data,mean) #均值
SD=sapply(Data,sd) #方差
cbind(Min,Max,Mean,SD)## Min Max Mean SD
## x1 3831732.000 7599295.000 5579519.9500 1.262195e+06
## x2 181.540 2110.780 765.0350 5.956983e+02
## x3 448.190 6882.850 2370.8250 1.919167e+03
## x4 7571.000 42049.140 19644.6850 1.020302e+04
## x5 6212.700 33156.830 15870.9480 8.199771e+03
## x6 6370241.000 8323096.000 7350513.6000 6.213419e+05
## x7 525.710 4454.550 1712.2390 1.184714e+03
## x8 985.310 15420.140 5705.7990 4.478400e+03
## x9 60.620 228.460 129.4935 5.050983e+01
## x10 65.660 852.560 340.2165 2.515779e+02
## x11 97.500 120.000 103.3050 5.513283e+00
## x12 1.029 1.906 1.4222 2.532348e-01
## x13 5321.000 41972.000 17273.8000 1.110919e+04
## y 64.870 2088.140 618.0840 6.092545e+02#pearson相关系数,保留两位小数
round(cor(Data,method = c("pearson")),2)## x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11
## x1 1.00 0.95 0.95 0.97 0.97 0.99 0.95 0.97 0.98 0.98 -0.29
## x2 0.95 1.00 1.00 0.99 0.99 0.92 0.99 0.99 0.98 0.98 -0.13
## x3 0.95 1.00 1.00 0.99 0.99 0.92 1.00 0.99 0.98 0.99 -0.15
## x4 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.19
## x5 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.18
## x6 0.99 0.92 0.92 0.95 0.95 1.00 0.93 0.95 0.97 0.96 -0.34
## x7 0.95 0.99 1.00 0.99 0.99 0.93 1.00 0.99 0.98 0.99 -0.15
## x8 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.15
## x9 0.98 0.98 0.98 0.99 0.99 0.97 0.98 0.99 1.00 0.99 -0.23
## x10 0.98 0.98 0.99 1.00 1.00 0.96 0.99 1.00 0.99 1.00 -0.17
## x11 -0.29 -0.13 -0.15 -0.19 -0.18 -0.34 -0.15 -0.15 -0.23 -0.17 1.00
## x12 0.94 0.89 0.89 0.91 0.90 0.95 0.89 0.90 0.91 0.90 -0.43
## x13 0.96 1.00 1.00 1.00 0.99 0.94 1.00 1.00 0.99 0.99 -0.16
## y 0.94 0.98 0.99 0.99 0.99 0.91 0.99 0.99 0.98 0.99 -0.12
## x12 x13 y
## x1 0.94 0.96 0.94
## x2 0.89 1.00 0.98
## x3 0.89 1.00 0.99
## x4 0.91 1.00 0.99
## x5 0.90 0.99 0.99
## x6 0.95 0.94 0.91
## x7 0.89 1.00 0.99
## x8 0.90 1.00 0.99
## x9 0.91 0.99 0.98
## x10 0.90 0.99 0.99
## x11 -0.43 -0.16 -0.12
## x12 1.00 0.90 0.87
## x13 0.90 1.00 0.99
## y 0.87 0.99 1.00#加载adapt-lasso源代码
lasso.adapt.bic2<-function(x,y){
require(lars)
ok<-complete.cases(x,y)
x<-x[ok,]
y<-y[ok]
m<-ncol(x)
n<-nrow(x)
x<-as.matrix(x)
one <- rep(1, n)
meanx <- drop(one %*% x)/n
xc <- scale(x, meanx, FALSE)
normx <- sqrt(drop(one %*% (xc^2)))
names(normx) <- NULL
xs <- scale(xc, FALSE, normx)
out.ls=lm(y~xs)
beta.ols=out.ls$coeff[2:(m+1)]
w=abs(beta.ols)
xs=scale(xs,center=FALSE,scale=1/w)
object=lars(xs,y,type="lasso",normalize=FALSE)
sig2f=summary(out.ls)$sigma^2
bic2=log(n)*object$df+as.vector(object$RSS)/sig2f
step.bic2=which.min(bic2)
fit=predict.lars(object,xs,s=step.bic2,type="fit",mode="step")$fit
coeff=predict.lars(object,xs,s=step.bic2,type="coef",mode="step")$coefficients
coeff=coeff*w/normx
st=sum(coeff !=0)
mse=sum((y-fit)^2)/(n-st-1)
if(st>0) x.ind<-as.vector(which(coeff !=0)) else x.ind<-0
intercept=as.numeric(mean(y)-meanx%*%coeff)
return(list(fit=fit,st=st,mse=mse,x.ind=x.ind,coeff=coeff,intercept=intercept,object=object,
bic2=bic2,step.bic2=step.bic2))
}
out1<-lasso.adapt.bic2(x=Data[,1:13],y=Data$y)## Loading required package: lars## Loaded lars 1.2#adapt-lasso输出结果名称
names(out1)## [1] "fit" "st" "mse" "x.ind" "coeff" "intercept"
## [7] "object" "bic2" "step.bic2"#变量选择输出结果序号
out1$x.ind## [1] 1 2 3 4 5 7#保留五位小数
round(out1$coeff,5)## x1 x2 x3 x4 x5 x6 x7 x8
## -0.00008 -0.23088 0.13746 -0.04005 0.07601 0.00000 0.30692 0.00000
## x9 x10 x11 x12 x13
## 0.00000 0.00000 0.00000 0.00000 0.00000#加载GM(1,1)源文件
gm11<-function(x0,t){ #x0为输入学列,t为预测个数
x1<-cumsum(x0) #一次累加生成序列1-AG0序列
b<-numeric(length(x0)-1)
n<-length(x0)-1
for(i in 1:n){ #生成x1的紧邻均值生成序列
b[i]<--(x1[i]+x1[i+1])/2
b} #得序列b,即为x1的紧邻均值生成序列
D<-numeric(length(x0)-1)
D[]<-1
B<-cbind(b,D)
BT<-t(B)#做逆矩阵
M<-solve(BT%*%B)
YN<-numeric(length(x0)-1)
YN<-x0[2:length(x0)]
alpha<-M%*%BT%*%YN #模型的最小二乘估计参数列满足alpha尖
alpha2<-matrix(alpha,ncol=1)
a<-alpha2[1]
u<-alpha2[2]
cat("GM(1,1)参数估计值:",'\n',"发展系数-a=",-a," ","灰色作用量u=",u,'\n','\n') #利用最小二乘法求得参数估计值a,u
y<-numeric(length(c(1:t)))
y[1]<-x1[1]
for(w in 1:(t-1)){ #将a,u的估计值代入时间响应序列函数计算x1拟合序列y
y[w+1]<-(x1[1]-u/a)*exp(-a*w)+u/a
}
##cat("x(1)的模拟值:",'\n',y,'\n')
xy<-numeric(length(y))
xy[1]<-y[1]
for(o in 2:t){ #运用后减运算还原得模型输入序列x0预测序列
xy[o]<-y[o]-y[o-1]
}
cat("x(0)的模拟值:",'\n',xy,'\n','\n')
#计算残差e
e<-numeric(length(x0))
for(l in 1:length(x0)){
e[l]<-x0[l]-xy[l] #得残差
}
##cat("残差:",'\n',e,'\n')
#计算相对误差
e2<-numeric(length(x0))
for(s in 1:length(x0)){
e2[s]<-(abs(e[s])/x0[s]) #得相对误差
}
##cat("相对残差:",'\n',e2,'\n','\n')
cat("残差平方和=",sum(e^2),'\n')
cat("平均相对误差=",sum(e2)/(length(e2)-1)*100,"%",'\n')
cat("相对精度=",(1-(sum(e2)/(length(e2)-1)))*100,"%",'\n','\n')
#后验差比值检验
avge<-mean(abs(e));esum<-sum((abs(e)-avge)^2);evar=esum/(length(e)-1);se=sqrt(evar) #计算残差的方差se
avgx0<-mean(x0);x0sum<-sum((x0-avgx0)^2);x0var=x0sum/(length(x0));sx=sqrt(x0var) #计算原序列x0的方差sx
cv<-se/sx #得验差比值
cat("后验差比值检验:",'\n',"C值=",cv,'\n')#对后验差比值进行检验,与一般标准进行比较判断预测结果好坏。
if(cv < 0.35){
cat("C值<0.35, GM(1,1)预测精度等级为:好",'\n','\n')
}else{
if(cv<0.5){
cat("C值属于[0.35,0.5), GM(1,1)模型预测精度等级为:合格",'\n','\n')
}else{
if(cv<0.65){
cat("C值属于[0.5,0.65), GM(1,1)模型预测精度等级为:勉强合格",'\n','\n')
}else{
cat("C值>=0.65, GM(1,1)模型预测精度等级为:不合格",'\n','\n')
}
}
}
#画出输入序列x0的预测序列及x0的比较图像
plot(xy,col='blue',type='b',pch=16,xlab='时间序列',ylab='值')
points(x0,col='red',type='b',pch=4)
legend('topleft',c('预测值','原始值'),pch=c(16,4),lty=l,col=c('blue','red'))
}
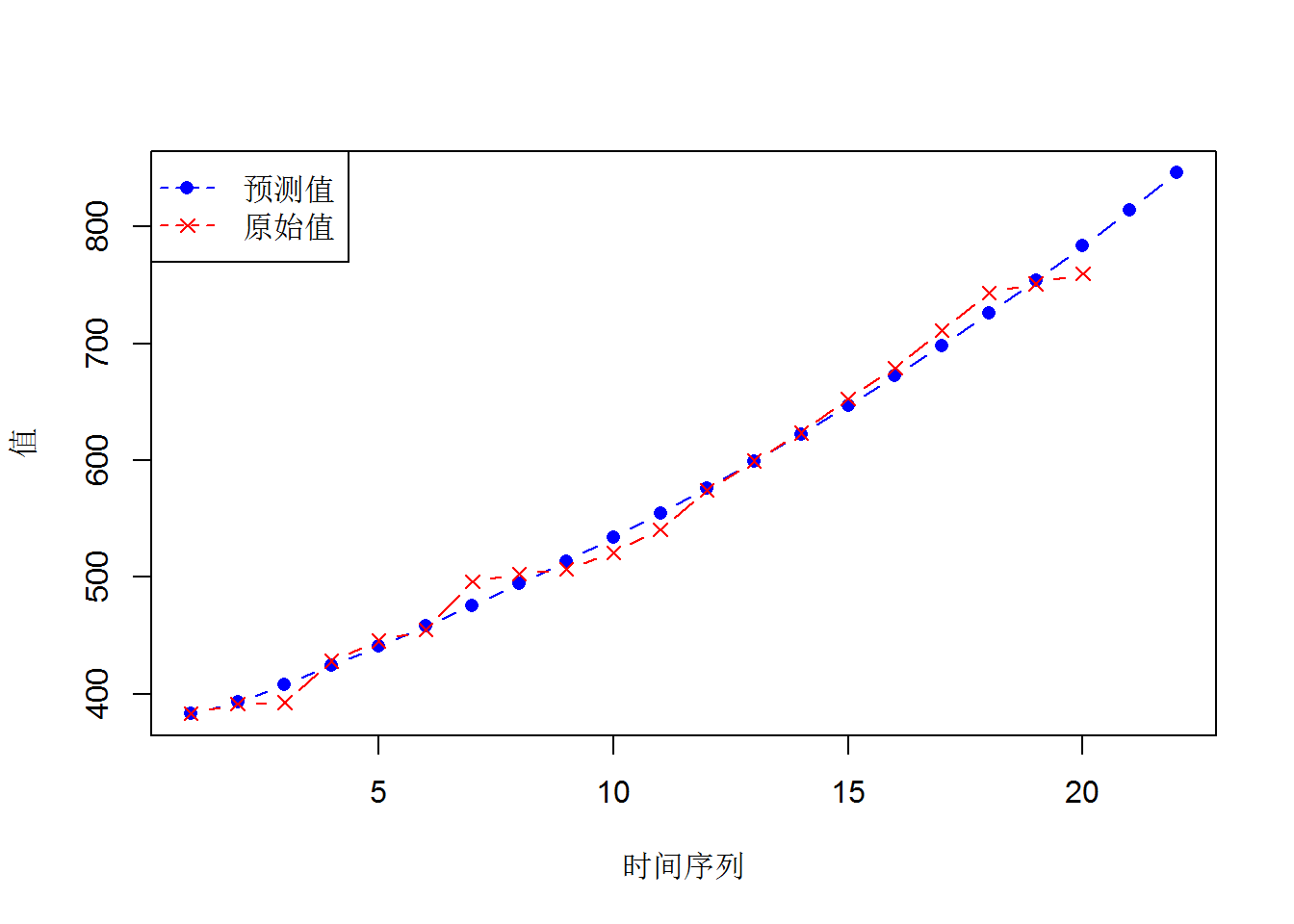
gm11(Data$x1/10000,length(Data$x1/10000)+2) ## GM(1,1)参数估计值:
## 发展系数-a= 0.03835295 灰色作用量u= 370.7037
##
## x(0)的模拟值:
## 383.1732 392.8855 408.2465 424.2081 440.7937 458.0279 475.9358 494.5439 513.8795 533.9711 554.8483 576.5417 599.0833 622.5062 646.8449 672.1352 698.4143 725.7208 754.095 783.5785 814.2148 846.0489
##
## 残差平方和= 2305.495
## 平均相对误差= 1.544396 %
## 相对精度= 98.4556 %
##
## 后验差比值检验:
## C值= 0.05756843
## C值<0.35, GM(1,1)预测精度等级为:好
##
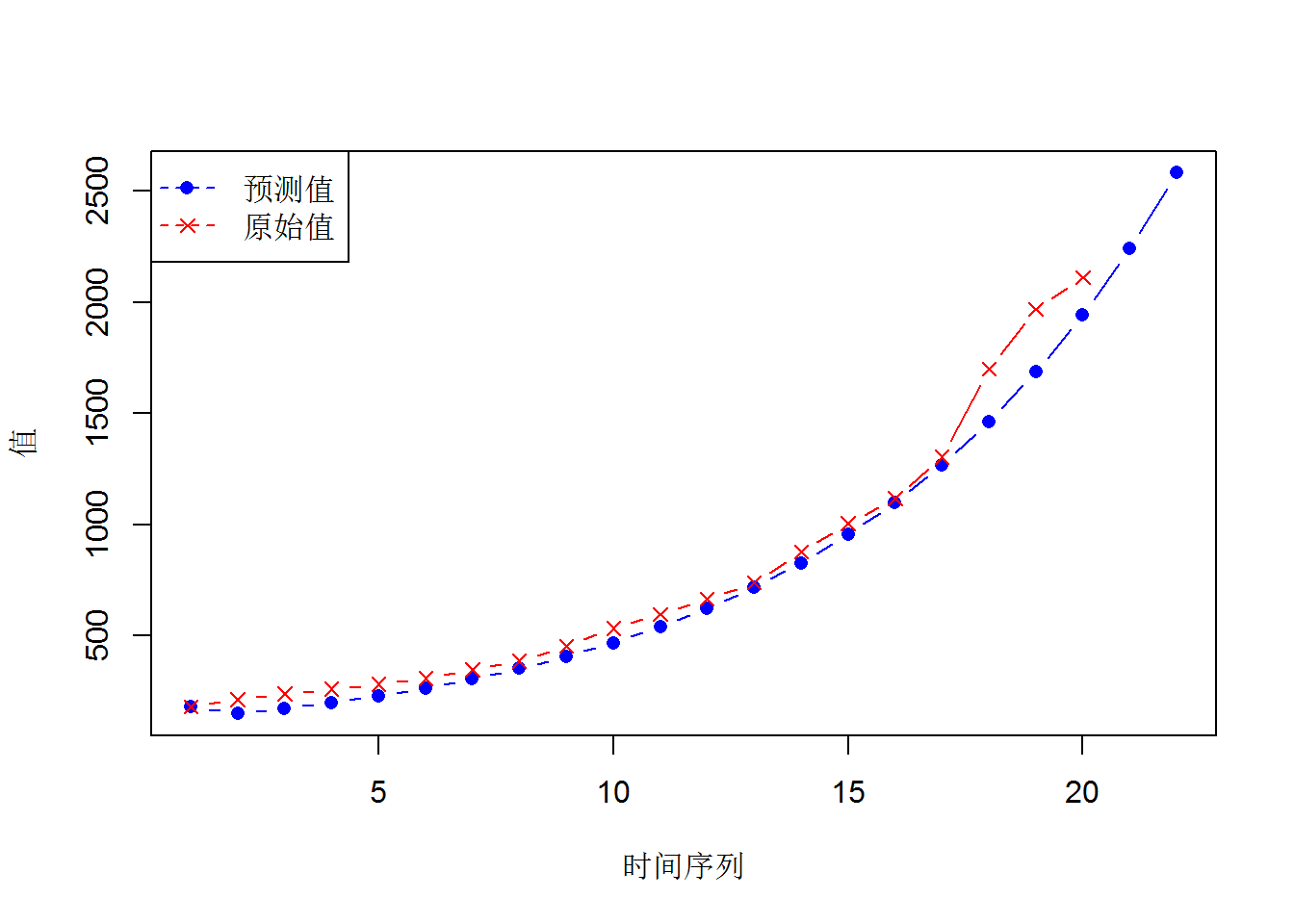
gm11(Data$x2,length(Data$x2)+2)## GM(1,1)参数估计值:
## 发展系数-a= 0.1420708 灰色作用量u= 114.3558
##
## x(0)的模拟值:
## 181.54 150.5915 173.5805 200.079 230.6227 265.8292 306.4102 353.1862 407.1031 469.2507 540.8857 623.4564 718.6322 828.3373 954.7899 1100.546 1268.554 1462.209 1685.428 1942.722 2239.295 2581.142
##
## 残差平方和= 203945.3
## 平均相对误差= 11.91801 %
## 相对精度= 88.08199 %
##
## 后验差比值检验:
## C值= 0.1253891
## C值<0.35, GM(1,1)预测精度等级为:好
## 
gm11(Data$x3,length(Data$x3)+2)## GM(1,1)参数估计值:
## 发展系数-a= 0.1481547 灰色作用量u= 325.0103
##
## x(0)的模拟值:
## 448.19 421.8931 489.2662 567.3983 658.0074 763.0861 884.9451 1026.264 1190.151 1380.209 1600.617 1856.224 2152.648 2496.41 2895.067 3357.387 3893.536 4515.304 5236.363 6072.57 7042.313 8166.916
##
## 残差平方和= 2632445
## 平均相对误差= 14.39723 %
## 相对精度= 85.60277 %
##
## 后验差比值检验:
## C值= 0.1294414
## C值<0.35, GM(1,1)预测精度等级为:好
## 
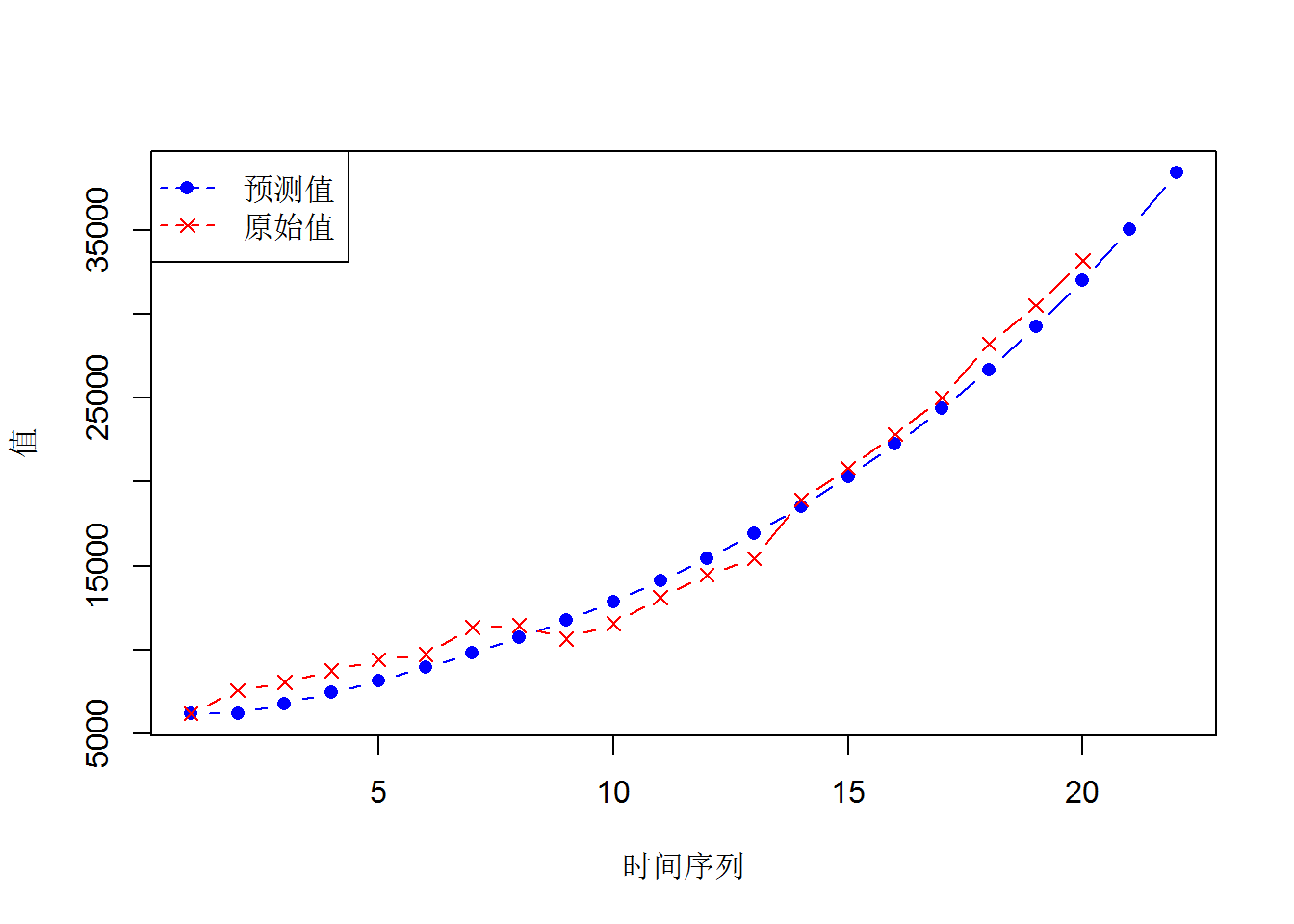
gm11(Data$x4,length(Data$x4)+2)## GM(1,1)参数估计值:
## 发展系数-a= 0.09153405 灰色作用量u= 6623.01
##
## x(0)的模拟值:
## 7571 7661.301 8395.668 9200.427 10082.33 11048.76 12107.83 13268.41 14540.24 15933.98 17461.32 19135.06 20969.24 22979.22 25181.87 27595.66 30240.82 33139.52 36316.08 39797.13 43611.84 47792.22
##
## 残差平方和= 28272186
## 平均相对误差= 6.861215 %
## 相对精度= 93.13878 %
##
## 后验差比值检验:
## C值= 0.06165169
## C值<0.35, GM(1,1)预测精度等级为:好
## 
gm11(Data$x5,length(Data$x5)+2)## GM(1,1)参数估计值:
## 发展系数-a= 0.09096704 灰色作用量u= 5379.414
##
## x(0)的模拟值:
## 6212.7 6223.333 6815.999 7465.106 8176.03 8954.657 9807.435 10741.43 11764.36 12884.72 14111.77 15455.67 16927.56 18539.62 20305.2 22238.93 24356.8 26676.37 29216.84 31999.24 35046.63 38384.22
##
## 残差平方和= 23928475
## 平均相对误差= 8.349924 %
## 相对精度= 91.65008 %
##
## 后验差比值检验:
## C值= 0.05264316
## C值<0.35, GM(1,1)预测精度等级为:好
## 
gm11(Data$x7,length(Data$x7)+2)## GM(1,1)参数估计值:
## 发展系数-a= 0.1253527 灰色作用量u= 333.0637
##
## x(0)的模拟值:
## 525.71 425.0468 481.811 546.1559 619.094 701.7729 795.4933 901.73 1022.154 1158.661 1313.398 1488.8 1687.626 1913.006 2168.484 2458.081 2786.353 3158.466 3580.273 4058.412 4600.405 5214.78
##
## 残差平方和= 677775.7
## 平均相对误差= 9.980516 %
## 相对精度= 90.01948 %
##
## 后验差比值检验:
## C值= 0.1109471
## C值<0.35, GM(1,1)预测精度等级为:好
## 
#读入数据
library(nnet)
Data=read.csv("C:\\Users\\Administrator\\Desktop\\R\\adaptive-lasso\\revenue.csv",header=F)
asData=scale(Data)
colnames(asData) <- c("x1","x2","x3","x4","x5","x7","y") #每列列名
nn<-nnet(y~.,asData[1:21,],size=6,decay=0.00000001,maxit=10000,linout=T,trace=T)## # weights: 49
## initial value 40.317478
## iter 10 value 0.326297
## iter 20 value 0.121196
## iter 30 value 0.034224
## iter 40 value 0.023359
## iter 50 value 0.016672
## iter 60 value 0.014192
## iter 70 value 0.011420
## iter 80 value 0.008432
## iter 90 value 0.007245
## iter 100 value 0.005231
## iter 110 value 0.004414
## iter 120 value 0.003734
## iter 130 value 0.002781
## iter 140 value 0.002027
## iter 150 value 0.001551
## iter 160 value 0.001449
## iter 170 value 0.001375
## iter 180 value 0.001350
## iter 190 value 0.001335
## iter 200 value 0.001256
## iter 210 value 0.001244
## iter 220 value 0.001208
## iter 230 value 0.001193
## iter 240 value 0.001139
## iter 250 value 0.001079
## iter 260 value 0.001027
## iter 270 value 0.000970
## iter 280 value 0.000913
## iter 290 value 0.000849
## iter 300 value 0.000797
## iter 310 value 0.000761
## iter 320 value 0.000740
## iter 330 value 0.000724
## iter 340 value 0.000706
## iter 350 value 0.000665
## iter 360 value 0.000620
## iter 370 value 0.000535
## iter 380 value 0.000493
## iter 390 value 0.000344
## iter 400 value 0.000276
## iter 410 value 0.000263
## iter 420 value 0.000238
## iter 430 value 0.000216
## iter 440 value 0.000186
## iter 450 value 0.000175
## iter 460 value 0.000145
## iter 470 value 0.000129
## final value 0.000099
## convergedpredict<-predict(nn,asData[,1:6])
predict=predict*sd(Data[1:21,7])+mean(Data[1:21,7])
a=1994:2015
#画出序列预测值、真实值图像
plot(predict,col='red',type='b',pch=16,xlab='年份',ylab='地方财政收入 / 万元',xaxt="n")
points(Data[1:21,7],col='blue',type='b',pch=4)
legend('topleft',c('地方财政收入预测值','地方财政收入真实值'),pch=c(16,4),col=c('red','blue'))
axis(1,at=1:22,labels=a)