scrapy + pandas 进行数据分析的一个例子
在没有看<利用python进行数据分析>之前一直不太明白数据分析是什么事情, 就跟学了很久python以后, 还是要时常搜索下, python能用来干嘛. 学了这两个模块后, 总算对于数据分析有一个初步的概念, 进行了一次实践
注意 : 本文原则上不提供scrapy或者pandas的使用方法介绍.
环境
- python2.7
- scrapy
- pandas
- matplotlib
- windowns7
- ipython
目的
获取指定贴吧的所有主题的发帖人, 发帖时间, 回复数, 帖子链接, 之后进行以下分析:
- 每年总主题数
- 每年发主题最多的用户
- 每年回复最多的帖子
- 每年每个主题平均回复数
- 每年每个月的主题数
具体操作
数据挖掘
新建item
item我就理解成一个对象了, 但是是没有方法的对象, 或许称为一个bean更好.
import scrapy
class Tieba_hoter_item(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
times = scrapy.Field()
href = scrapy.Field()
item的建立紧扣我们的目的, 以一条帖子为一个item, 记录下它的属性.
建立爬虫
首先来分析我们信息的来源
还算简单, 不需要进帖子就可以获得回复数, 作者, 主题, 可惜没有时间(时间对我我们的分析非常重要).

进入帖子中, 发现了非常规范的时间显示, 正式我们需要的. 具体获得方式在下面代码中会有所体现, 这里不再赘述.
之后我们建立爬虫. 上一篇的时候每次都手动设定headers, 这回搜寻资料, 了解到了一个属性DEFAULT_REQUEST_HEADERS, 这个是scrapy.Request的默认header设置. scrapy爬虫开始的连接是一个数组, 我决定用循环将所有页面添加进去
start_urls = []
pagesize = 50
original_url = 'http://tieba.baidu.com/f?kw=clannad&ie=utf-8&pn='
for x in xrange(4500):
start_urls.append(original_url + str(x * pagesize))
result_list = []
之后是第一层解析, 要做的事情是获取标题, 链接, 回复数, 作者, 再根据链接进行第二层挖掘. 代码如下
def parse(self, response):
selector_title = response.css('.threadlist_title > a::attr(title)').extract()
selector_href = response.css('.threadlist_title > a::attr(href)').extract()
selector_timers = response.css('.threadlist_rep_num::text').extract()
selector_author = response.css('.tb_icon_author::attr(title)').extract()
if(len(selector_title) == (len(selector_author) if (len(selector_author) == len(selector_timers)) else False)):
for i in xrange(len(selector_author)) :
item = Tieba_hoter_item(title = selector_title[i].encode('utf-8'), href = selector_href[i].encode('utf-8'),
author = selector_author[i].encode('utf-8'), times = selector_timers[i].encode('utf-8'), date = self.temp_date)
yield scrapy.Request('http://tieba.baidu.com/' + selector_href[i], callback = (lambda r, x = item: self.parse_deal(r, x)), headers = self.DEFAULT_REQUEST_HEADERS)
pass
比较有难度的只有这一句
yield scrapy.Request('http://tieba.baidu.com/' + selector_href[i], callback = (lambda r, x = item: self.parse_deal(r, x)), headers = self.DEFAULT_REQUEST_HEADERS)
yield是根据官方文档写的, 还没有看源码, 应该是用生成器形式调用parse的. 其中费了一番力气的是这一句 callback = (lambda r, x = item: self.parse_deal(r, x)).
先说一下我想做什么事情. 将parse()中获得的数据(标题, 作者等)传到第二级解析函数也就是callback函数parse_deal()中. 我曾经尝试将获得数据设置成class的成员变量. 可是scrapy使用了多线程, parse 跟 parse_deal 并不是线性进行. 最好的方式就是在callback中进行传值. 一开始不知道该怎么传(你可以试试直接写callback=parse_deal(xxxx)), 后来通过一番查找, 用lambda解决了这个问题. 这句代码的意思就是接收两个参数(第一个self), 第二个参数设置为item(我们需要下一级函数处理的数据).
还剩下一件事情, 就是数据的本地化. 我放在了closed()函数中, 保证在任何原因(包括完成)爬虫停止的时候将数据存在本地.
以下完整代码
#-*- coding:utf-8 -*-
import scrapy
import urllib2
import os
from test1.items import Tieba_hoter_item
import json
import sys;reload(sys);sys.setdefaultencoding('utf-8')
class TiebaSpider(scrapy.Spider):
name = 'tieba'
DEFAULT_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3', 'Accept-Encoding': 'none', 'Accept-Language': 'en-US,en;q=0.8', 'Connection': 'keep-alive'}
start_urls = []
pagesize = 50
original_url = 'http://tieba.baidu.com/f?kw=clannad&ie=utf-8&pn='
for x in xrange(4500):
start_urls.append(original_url + str(x * pagesize))
result_list = []
temp_date = ''
def parse(self, response):
selector_title = response.css('.threadlist_title > a::attr(title)').extract()
selector_href = response.css('.threadlist_title > a::attr(href)').extract()
selector_timers = response.css('.threadlist_rep_num::text').extract()
selector_author = response.css('.tb_icon_author::attr(title)').extract()
if(len(selector_title) == (len(selector_author) if (len(selector_author) == len(selector_timers)) else False)):
for i in xrange(len(selector_author)) :
item = Tieba_hoter_item(title = selector_title[i].encode('utf-8'), href = selector_href[i].encode('utf-8'),
author = selector_author[i].encode('utf-8'), times = selector_timers[i].encode('utf-8'), date = self.temp_date)
yield scrapy.Request('http://tieba.baidu.com/' + selector_href[i], callback = (lambda r, x = item: self.parse_deal(r, x)), headers = self.DEFAULT_REQUEST_HEADERS)
pass
def parse_deal(self, response, item):
temp_date = response.css('.post-tail-wrap > .tail-info::text')[-1].extract()
item['date'] = temp_date
self.result_list.append(item)
pass
def closed(self, reason):
print reason
with open('tieba_temp/data.json', 'wb+') as f:
f.write('[')
for i in self.result_list:
f.write(json.dumps(dict(i), ensure_ascii = False) + ',')
f.write('{}]')
f.close()
开爬
用命令行启动爬虫, crawl什么的. 最后爬到了30MB左右的数据.
数据分析
将数据转换成DataFrame
DataFrame是pandas基础数据结构, 与json的契合度很高.
json_data = json.load(open('200000data.json'))
df = DataFrame(json_data)
数据规整
我本来以为数据规整会花费很长的时间, 没想到爬到的数据意外规整(也因为数据不复杂啦). 只需要进行常规几部就可以开始进行分析了.
df = df.dropna() #去除空行
df = df.drop_duplicates() #去除重复行
def me_parse_date(row):
try:
return datetime.strptime(row, '%Y-%m-%d %H:%M')
except:
return np.nan
def me_parse_num(row):
try:
return int(row)
except:
return np.nan
df['times'] = df['times'].apply(me_parse_num) #times是回帖数, 需要参与计算, 原本数据类型为str, 需要转换为int
df['date'] = df['date'].apply(me_parse_date) #date是发帖时间, 需要参与计算, 是最重要的数据标识, 需要转换为一致的时间格式
这样我们的数据就规整结束, 可以开始进行数据分析了.
每年总主题数
很简单的一个统计. 现在date已经规整过, 只需要下面的语句就能得出某年的主题数
df[df['date'] > '2015'][df['date'] < '2016'].count()
之后新建一个dataframe, 再plot出来, 就是需要的统计图.
df_count_year = DataFrame([df[df['date'] > '2015'][df['date'] < '2016']['title'].count(), df[df['date'] > '2016'][df['date'] < '2017']['title'].count()], index = [2015, 2016])
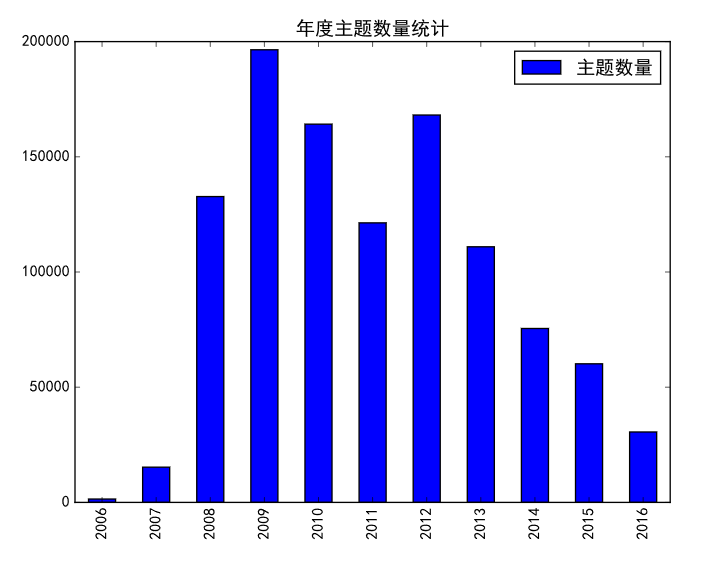
每年发主题最多的用户
这个统计也不难. 只需要计算当年用户id出现次数就可以. 跟上一个没区别, 只是多了一个判定, 就不举例了.
每年被回复最多的用户
这个分析使用到了分组和排序, 因为需要计算times的总和.
df[df['date'] > '2014'][df['date'] < '2015'].groupby(df['author']).sum().sort_values('times')
首先取到某一年的数据, 再以author进行分组, 计算各行的总和, 再以times进行排序, 得到了需要的数据.

每个月的主题数
这个最像数据分析, 使用了pandas的resample(‘M’). 感兴趣可以自己了解下, 这里直接给出结果.
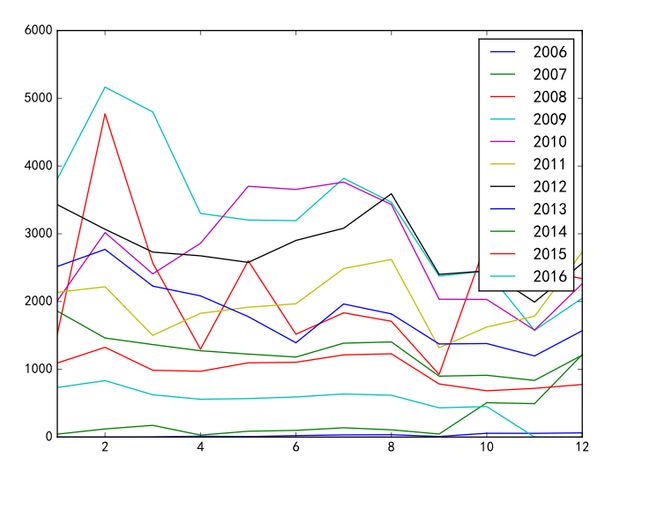
总结
- json转换的时候出了很多次编码问题, 需要注意
- 爬数据用了八个小时有余. 到最后看着python内存占用越来越大, 真怕出点什么意外导致本地化失败. 也说明了爬虫并不合理, 应该分段进行储存. 主要也没想到会爬这么多数据.
- ipython对于中文并不算友好, 尤其用中文当key去检索数据的时候, 非常麻烦, 最好想个方法解决.
- matplotlib对中文支持有限, 需要自己去修改一些配置.