决策树实现
树模型参数解释
criterion gini or entropy : 选择决策树剪枝使用gini系数或者是熵值法
splitter best or random: 选择在所有特征中找最佳切分点或在部分特征中找最佳切分点
max_depth:对决策树深度做限制(预剪枝)
min_samples_split: 判断是否叶子节点继续进行分裂,如果小于这个值如10,节点样本数只有9了,就不会再继续分裂
min_samples_leaf: 限制叶子节点最小样本数
max_leaf_nodes :限制最大叶子节点个数
n_estimators :要建立树的个数
库函数导入注意事项
from sklearn.externals.six import StringIO
import matplotlib.pyplot as plt
import pandas as pd
import pydotplus
from sklearn.model_selection import train_test_split
from sklearn.datasets.california_housing import fetch_california_housing
from IPython.display import Image
from sklearn.model_selection import GridSearchCV
from sklearn import tree
注意:pydotplus库用于查看建立的树文件(虽然我没用到),StringIO库用于传递给输出树图参数(必写),另外导入GridSearchCV和train_test_split必须从model_selection中进行导入操作,而不能从cross——validation或者gridxx中导入,因为这样会存在由于更新导致的冲突问题。
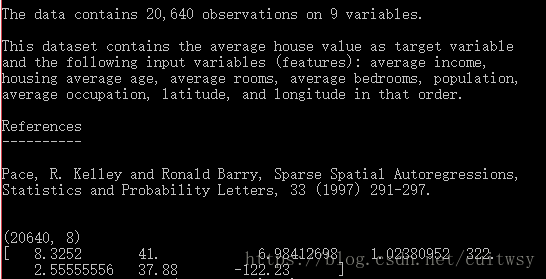
housing = fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.data[0])
首先看一下我们的加州房屋数据中包含什么信息,使用housing.DESCR,使用housing.data.shape查看数据量和数据表包含多少特征列,最后用**data[0]**来看看第一行数据是什么。
dtr = tree.DecisionTreeRegressor(max_depth = 3)
dtr.fit(housing.data[:,[6,7]],housing.target)
print(dtr)
out_graph = StringIO()
dot_data = \
tree.export_graphviz(
dtr,
out_file = out_graph,
feature_names = housing.feature_names[6:8],
filled = True,
impurity = False,
rounded = True
)
graph = pydotplus.graph_from_dot_data(out_graph.getvalue())
graph.write_pdf("iritian.pdf")
graph.write_png("juece kk.png")
首先,使用tree.DecisionTreeRegressor建立决策树,这时我在括号里面使用max_depth限制了树深度,也就是进行了剪枝操作,也可以加上我一开始就说的那些树的参数信息,比如splitter = 'best’来进一步限制树的形状,紧接着就是导入数据了,使用fit函数来导入数据和特征,第一个是数据,我导入了经纬度,也就是最后2个特征(6,7),然后利用target自动找到了数据的特征,在完成了树的建立后,首先使用StringIO()来建立输出图像,接着使用下载好的graphviz来通过建立的树画出图像,在dot_data里面我们需要关心的就是输出图像,我们需要设定为刚刚通过StringIO()建立的图像参数上去,dtr是刚刚建立的决策树,feature_names要注意是建立的我们之前选择的特征列,并且需要多加一位到8而不是6,7;下面的graph即是对输出图像的处理和图片,pdf格式的输出


data_train,data_test,target_train,target_test = \
train_test_split(housing.data,housing.target,test_size = 0.1, random_state = 42)
dtr = tree.DecisionTreeRegressor(random_state = 42)
dtr.fit(data_train,target_train)
print(dtr.score(data_test,target_test))
from sklearn.ensemble import RandomForestRegressor
rtf = RandomForestRegressor(random_state = 42)
dtr.fit(data_train,target_train)
print('RANDOMFOREST SCORE')
print(dtr.score(data_test,target_test))
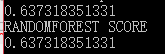
这段代码相信大家应该很熟悉了,第一段是针对数据集的分割,用9:1来分割为训练集和测试集,并且先确定此种分割状态为42,fit和上面的一样,也是导入数据,特征,然后通过dtr.score函数来获取针对测试集的输出,第二个是随机森林的算法,之后再讲哈
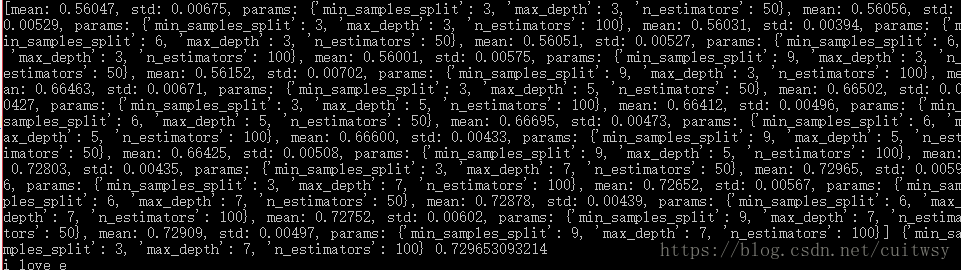
tree_param_grid = { 'max_depth': list((3,5,7)),'min_samples_split': list((3,6,9)),'n_estimators':list((50,100))}
grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(data_train, target_train)
grid.grid_scores_, grid.best_params_, grid.best_score_
print(grid.grid_scores_, grid.best_params_, grid.best_score_)
print('i love e')
特征选择
最后我们如何选择最好的特征呢?要通过GridSearchCV来实现(类似多重for循环,来寻找最优特征), tree_param_grid = { ‘max_depth’: list((3,5,7)),‘min_samples_split’: list((3,6,9)),‘n_estimators’:list((50,100))} 这一行是我们需要判定哪个值相对来说预测的准确度或者说效果最好,我选择了深度,节点最大分裂数值,树个数,并给与了几个不同的参数来进行判定,之后,同样的,我们需要导入随机森林算法(树的个数对整体效果有作用),刚刚提到的各个需要判定的参数,和循环检测次数,循环检测是什么呢?cv=5是通过把训练集分割为5个相等的小训练集,比如abcde,在把e作为测试集,abcd训练得到模型后拿e测试一下准确度,循环做几次取准确度均值。在导入训练集数据,特征,最后使用 ** grid.grid_scores_** 查看各个参数的得分, ** grid.best_params_** 查看效果最好的参数, grid.best_score_ 查看最佳得分是多少