学渣讲爬虫之Python爬虫从入门到出门(第三讲)
学渣讲爬虫之Python爬虫从入门到出门(第三讲)
这一讲,我将会为大家讲解稍微复杂一点的爬虫,即动态网页的爬虫。
- 学渣讲爬虫之Python爬虫从入门到出门第三讲
-
- 动态网页技术介绍
- 动态网页爬虫技术一之API请求法
- 动态网页爬虫技术二之模拟浏览器法
- 安装selenium模块
- 下载Google Chrome Driver
- 安装ChromeDriver
- 以某宝某只松鼠店铺为例爬取坚果炒货的商品名称价格销量以及评论数量
- 课后作业
- 关于作者
-
动态网页技术介绍
所谓的动态网页,是指跟静态网页相对的一种网页编程技术。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
值得强调的是,不要将动态网页和页面内容是否有动感混为一谈。这里说的动态网页,与网页上的各种动画、滚动字幕等视觉上的动态效果没有直接关系,动态网页也可以是纯文字内容的,也可以是包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,只要是采用了动态网站技术生成的网页都可以称为动态网页。(解释来源:百度百科 - “动态网页”,若链接失效请访问:https://baike.baidu.com/item/%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=aladdin)

互联网每天都在蓬勃的发展,数以万计的在线平台如雨后春笋般不断涌现,不同平台对不同用户的权限、喜好推出不同的个性化内容,传统的静态网页似乎早已不能满足社会的需求。于是,动态网页技术应运而生,当然,在如今人们对网页加载速度的要求越来越高的要求下,异步加载成为了许多大的站点的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说,就是把一些根据时间、请求而变化的内容,比如某宝的商品价格、评论,比如某瓣的热门电影评论,再比如某讯的视频等,采用先加载网页整体框架,后加载动态内容的方式呈现。
对于这一类动态页面,如果我们采用前面所说的对付静态网页的爬虫方式去爬,可能收获不到任何结果,因为这些异步加载的内容所在的位置大多是一段请求内容的JS代码。在某些触发操作下,这些JS代码开始工作,从数据库中提取对应的数据,将其放置到网页框架中相对应的位置,从而最终拼接成我们所能看到的完整的一张页面。
动态网页爬虫技术一之API请求法
看似更加复杂的操作似乎给我们的爬虫带来了很大的困扰,但其实也可能给我们带来极大的便利。我们只需要找到JS请求的API,并按照一定的要求发送带有有效参数的请求,便能获得最为整洁的数据,而不用像以前那样从层层嵌套的HTML代码中慢慢解析出我们想要的数据。
这里我们以上面提到的豆瓣电影(若链接失效请访问:https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例做一个分析,提取出热度排名前100的电影名称和评分以及在豆瓣的地址。
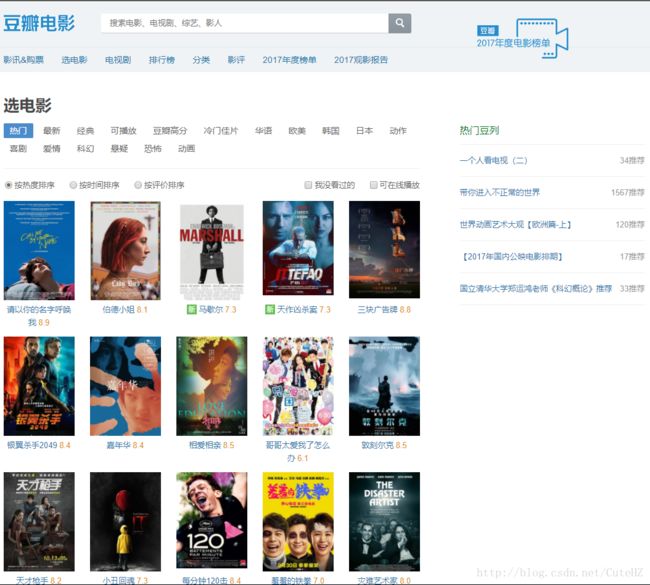
这是最近热门电影按热度排序的一个截图,每个月都有不同的新电影上映,每部电影会随着口碑效应每天呈现不同的热度排序,如果这页面是个静态网页,那么豆瓣的程序员岂不是很辛苦,每天都要上线修改这个页面。所以,我们可以大胆的猜测,这是个动态页面。但是光猜不行,我们还得证实。这里就要用到第二讲讲到的谷歌开发者工具了。按下F12或者在网页空白处右键选择检查(N),或者在键盘上按下组合键Ctrl + Shift + I,召唤出我们的神器。如下图所示:
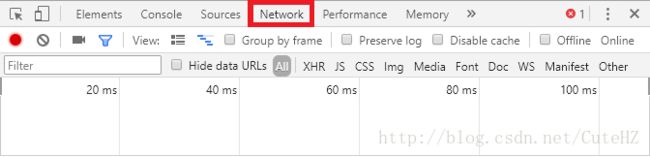
今天我们不再使用左上角的鼠标按钮了,而是使用红色框中的Network,这里显示的是网页加载出来的所有的文件,如下图所示:
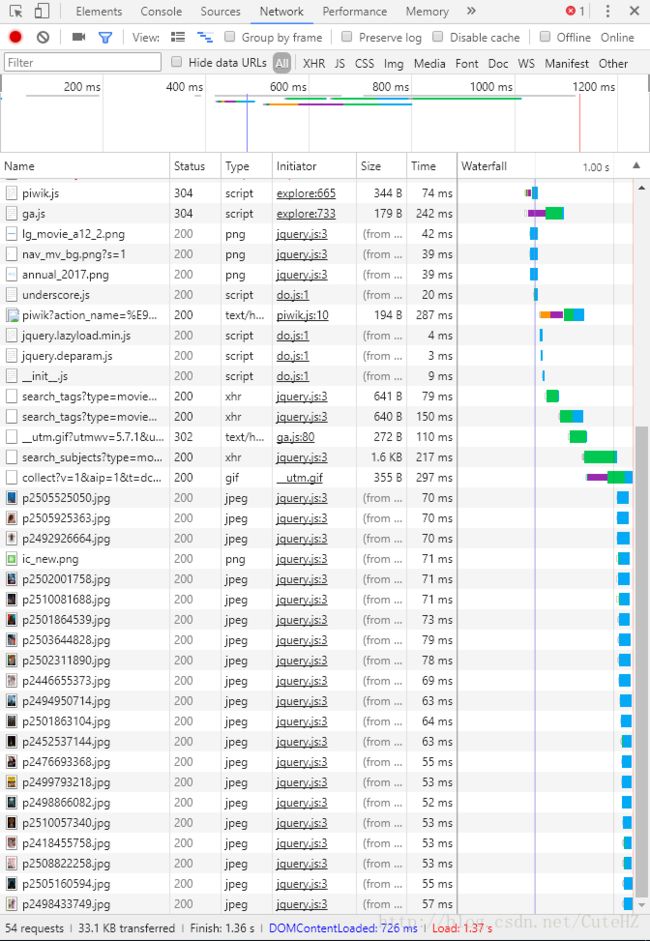
如果下方没有任何结果,需要在打开谷歌开发者工具的情况下刷新网页。

如上图所示,我们点击上方红色小框中的”XHR“按钮,就可以将这张网页中异步加载的内容筛选出来。至于到底哪一个才是我们所要的,这是个问题,看左边的地址我们似乎也看不出神马头绪,那就一个一个点出来看吧。。。经过枚举,我们发现,第三个是我们要的内容,它的内容如下图:
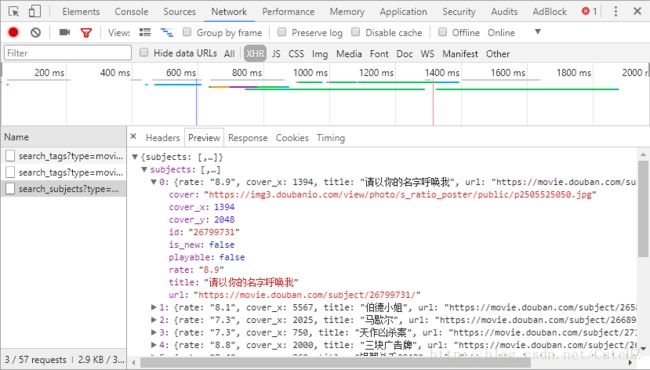
我们可以看到,这个链接里包含的内容是以JSON格式展示出来的,这时我们便有了一个大概的思路,那就是将这个链接的内容用requests模块下载后,再用Python的json模块进行解析。
但是,这好像是一页的内容,数一数也只有20部电影,我们想要的是排名前100的电影,这怎么办呢?
不方,毕竟是动态网页,内容都是可以根据请求改变的,而且这里也没有登陆啥的操作,打开网页就能看到,那我们是不是可以改变一下URL从而获取到下一页甚至下下页的内容咧?当然可以,不然我就写不下去了!
我们仔细观察一下这个URL里传递的参数:
https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
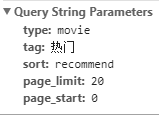
到这里我们可能还不知道这五个参数是干嘛的,但我们可以找规律啊,于是现在回到原始的网页,点击页面下方的“加载更多”,再返回到开发者工具,哇,多出了一个URL,长的跟刚才说的那个好像,内容也长的好像:
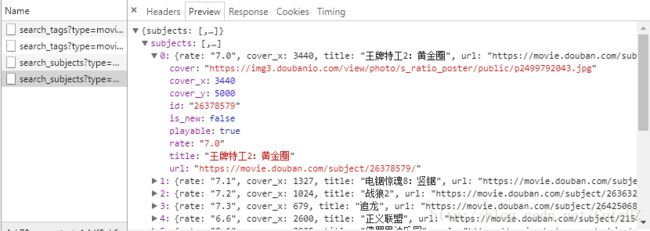
这个URL同样传递了五个参数:
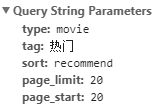
唯一的不同就是一个叫“page_start”的关键字的值改变了,简单翻译一下大概是页面起点的意思,再看上面的“page_limit”,大概就是页面限制的意思,看右边的响应内容,这一个页面传递了20个条目,也就是说“page_limit”是一个页面里条目数量的限制,也就是20条,这个数据是不变的,而“page_start”是这一页开始的条目序号,那么我们要获取后面的内容,岂不是只要改变一下这个“page_start”就好了?是的。
老规矩,先写个代码压压惊:
# -*- coding: utf-8 -*-
import requests
import json
for i in range(5):
page_start = str(i * 20) # 注释1
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=' + page_start # 注释2
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url=url, headers=headers, verify=False)
content = response.content.decode()
content_list = json.loads(content)['subjects'] # 注释3
for item in content_list: # 注释4
title = item['title'] #注释5
rate = item['rate'] # 注释6
link = item['url'] # 注释7
print(title, rate, link)注释1:因为一页有20条数据,我们要爬取100条,而page_start的起始数据是0,因此我们这里只需要用一个i,从0到4循环5次,每一次乘以20便可以轻松的设置page_start的值了,因为后面的URL是个字符串类型,这里进行乘法运算后我们用str()方法进行类型转换,转换成str类型,方便后面的调用。
注释2:这里我们每一次循环只要改变page_start的值就好了,所以在最后修改这个值;
注释3:返回的content经过decode()方法解码,变成了一个字符串类型,根据我们前面的分析,得出这是一个JSON格式的字符串,因此,我们用Python内置的标准库json来进行解析,标准库就不需要用pip工具进行安装了。json模块有两个主要方法——json.loads()和json.dumps(),前一个是用来解码JSON数据的,后一个则是编码成JSON数据的。这里我们主要用到loads()方法,将content解析成一个字典格式的内容,存储在名为content_list的对象里,最后加上“[‘subjects’]”是用来解析出我们要的最简洁的部分,这个根据具体的内容来定,不是所有的解析都要这么写。比如这里,如下图:

我们要的内容最外面有这么一个嵌套,这个嵌套的Key为”subjects”,这个Key的值为一个数组,这个数组才是我们要的,因此加上了“[‘subjects’]”。
注释4:content_list是一个数组对象,因此我们也做一个循环,分条提取。
注释5:每一条数据依然是个字典类型的对象,因此我们可以直接写对应的Key名得到想要的值,这里得到的电影的名称;
注释6:同5,这里得到的是电影的评分;
注释7:同5,这里得到的是电影的豆瓣链接;
最后的话,大家可以采用标准输入流写入txt文件,也可以采用xlwt模块写入EXCEL,还可以使用比如pymysql模块写入Mysql数据库,具体的方式大家随意,使用方法请自行百度。
到这里,这种采用寻找API并传递有效参数重放API的方法便为大家介绍完了,这是个很通用的方法,在很多网站都可以这样使用,并且速度很快,结果最精简。
动态网页爬虫技术二之模拟浏览器法
上面我们所讲的API请求法虽然好用且快,但是并不是所有的网站都会采用这种异步加载的方式来实现网站,同时还有部分网站会针对爬虫采取反爬虫措施,比如常见的验证码,虽然验证码主要是用来防止CSRF攻击的,但也有网站用来处理爬虫,比如某宝。这时候,就要为大家介绍另一个神器了,Python的Selenium模块。
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。(解释来自:百度百科 - “Selenium”,若链接失效请点击https://baike.baidu.com/item/Selenium/18266?fr=aladdin)
简单的说,Selenium是一个主要用来进行自动化测试的工具,它可以配合浏览器驱动在各个浏览器中运行,依照代码自动地模拟人的操作,去获取网页元素或对网页元素进行控制。当然,Selenium并不是Python的产物,而是一个独立的项目,Python对Selenium提供支持。(大家可以自行访问Selenium的主页进行访问,若链接失效请点击http://www.seleniumhq.org/)
安装selenium模块
要使用Selenium这种第三方的工具,我们首先要进行安装,这里依然用到pip工具。在管理员权限下运行命令行,输入pip install selenium,稍等片刻后便可以完成安装,如果觉得网络连接官方pypi镜像速度较慢,可以使用国内豆瓣的镜像源,pip install selenium -i https://pypi.douban.com/simple/,加上这个-i参数和豆瓣pypi镜像的地址就可以了,如果想要默认使用豆瓣镜像源,请自行百度修改方法。
下载Google Chrome Driver
在安装成功后,我们就需要安装下一个必要的东西了,浏览器驱动,前面说过,selenium需要配合浏览器驱动运行,因此我们以安装Google Chrome Driver为例。
首先,我们需要查看自己的谷歌浏览器版本,这个在谷歌的”帮助”中可以查看,具体方法是,打开Chrome,点击右上角的三个点状的按钮,接着在弹出的菜单中依次选择帮助(E) -> 关于 Google Chrome(G)如下图所示:
作者的浏览器是更新到当前最新的版本63的,旧版本的操作方法大致一致。
点开关于信息后,我们可以看到当前的Chrome版本,以下图为例:
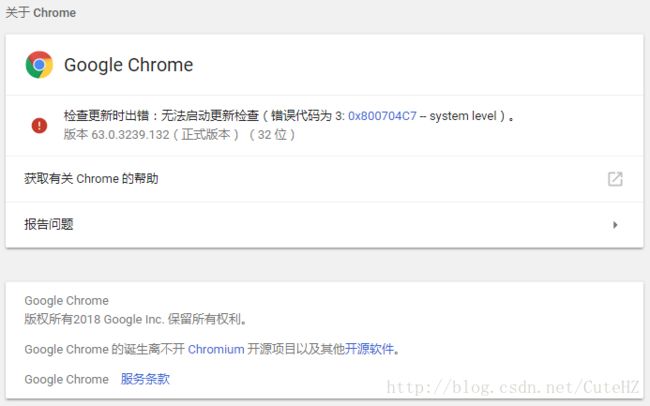
Chrome一直在升级,因此对应的驱动也得不断升级,并且与Chrome版本相适应。这里我们需要查找相应的ChromeDriver版本映射,给大家推荐一个持续更新的CSDN博客(若链接失效请点击:http://blog.csdn.net/huilan_same/article/details/51896672),根据版本映射表,下载对应版本的ChromeDriver,下载地址1(若链接失效请访问:http://chromedriver.storage.googleapis.com/index.html),下载地址2(若链接失效请访问:http://npm.taobao.org/mirrors/chromedriver/)。
安装ChromeDriver
这里需要进行环境变量的配置,如第一讲所说,为”Path”添加一行值。
首先,我们需要找到Chrome的安装位置,最为简单的办法是,在桌面找到Google Chrome的快捷方式,右键选择”打开文件所在的位置“,就能打开了。比如我这里打开的路径为C:\Program Files (x86)\Google\Chrome\Application,那么我就将这个路径添加到Path里。然后,需要我们将下载的ChromeDriver解压到exe程序,将单独的exe程序复制到刚才这个路径里,如下图所示:
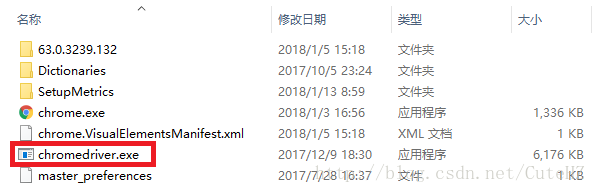
到这里,ChromeDriver便完成了安装,我们可以在命令行输入命令python,进入到python交互环境进行测试,如下图所示:

如果你的谷歌浏览器自动打开,并且跳转到百度首页,那么Congratulations~
以某宝某只松鼠店铺为例爬取”坚果炒货”的商品名称、价格、销量以及评论数量
该页面的URL为:https://sanzhisongshu.tmall.com/category-1124487841.htm?spm=a1z10.1-b-s.w5003-17763072511.42.6995d6732XB8Of&tsearch=y&scene=taobao_shop#TmshopSrchNav
老规矩,先放一段代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
driver = webdriver.Chrome() # 注释1
url = 'https://sanzhisongshu.tmall.com/category-1124487841.htm?spm=a1z10.1-b-s.w5003-17763072511.42.6995d6732XB8Of&tsearch=y&scene=taobao_shop#TmshopSrchNav'
driver.maximize_window() # 注释2
driver.get(url) # 注释3
dl_list = driver.find_elements_by_class_name('item') # 注释4
for dl in dl_list:
name = dl.find_element_by_css_selector("[class='item-name J_TGoldData']").text # 注释5
price = dl.find_element_by_class_name('cprice-area').text # 注释6
sale = dl.find_element_by_class_name('sale-area').text # 注释7
comment = dl.find_element_by_xpath('//*[@id="J_ShopSearchResult"]/div/div[3]/div[1]/dl[1]/dd[2]/div/h4/a/span').text # 注释8
print(name, price, sale, comment)
driver.close() # 注释9注释1:实例化了一个webdriver的Chrome对象,命名为driver,这时会有一个Chrome窗口自动打开。
注释2:调用了driver的maximize_window()方法,直接翻译就是最大化窗口,也就是这个功能,这句写不写不重要,作者写只是觉得看的清楚点。
注释3:调用了driver的get()方法,以get方式请求URL。
注释4:这里开始是重点,webdriver主要有八种查找元素的方式,这一行是采用class_name的形式进行查找,并且注意到elements这里的复数,这个方法用来查找页面上所有的符合条件的元素,如果是没有s的方法就只能找到首个符合条件的元素,这一行是使用谷歌开发者工具的左上角小箭头工具对元素进行审核,并找出所有的商品条目,其中一个条目范围如下图所示:
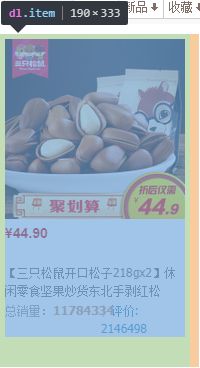
注释5:同注释4,但这里采用的是css_selector,即css选择器的方式进行查找,因为这里的类名”item-name J_TGoldData”是个复合结构,而find_element_by_class_name()方法不支持复合结构的查找,所以只能采用css_selector这种方式。
注释6:同注释4,这里是单数,即在一个商品条目的范围内查找一次。
注释7:同注释6。
注释8:同注释4,但这里采用的是xpath的方式查找。
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。(解释来自:百度百科 - “XPath”,若链接失效请访问:https://baike.baidu.com/item/XPath/5574064?fr=aladdin)
获得元素xpath的方法有几种,最为简单的一种,即在谷歌开发者工具面板上选择要查找的元素,右键选择
Copy -> Copy XPath,如下图所示: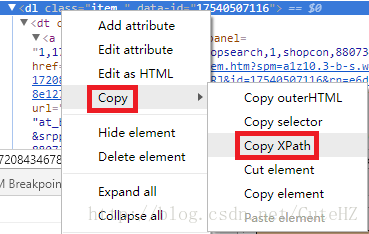
当然这种方式可能存在缺陷,即获得的XPath可能过于繁琐,也可能获取的XPath无法正确查找到相应的元素,这都需要手动的依据XPath的语法去修改。
注释9:最后一定要记得关闭实例化的对象,这时候由程序打开的浏览器也会随之关闭。
这个例子最后的结果如下图:
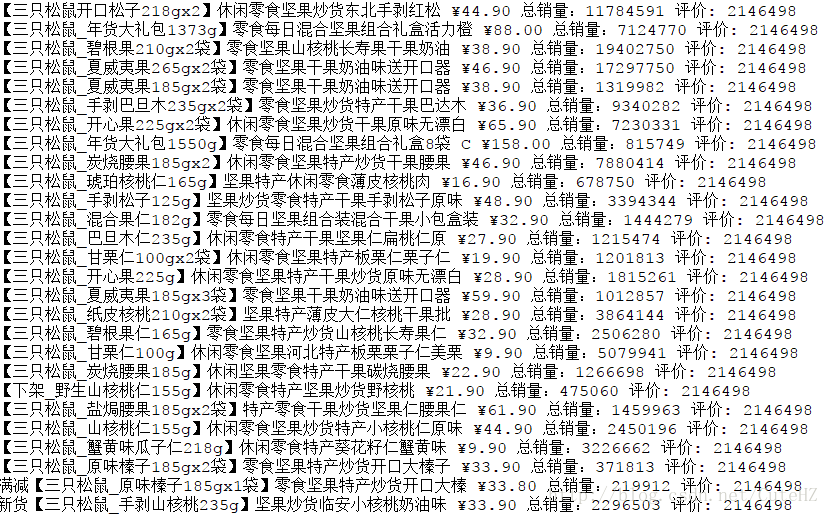
大家依然可以自由的选择数据存储方式。
这里要注意的是:使用selenium进行数据爬取相比前面的API请求法可能会慢的多,在打开到对应的窗口后,也可能窗口很长时间没有任何动作,但这不一定是出错或者是程序卡死的表现,也可能是程序在疯狂的查找网页元素,在这个过程中,如果不确定是否出错,请最好不要进行其他操作,避免有些时候造成元素失去焦点,导致莫名的错误。
当然了,selenium的功能远不止如此,几乎人能在网页上做出的行为,它都能模拟,包括点击、输入等各种行为,这个比较适用于某些网站要填写验证码的情况,更多有趣的内容大家可以自行发现。本讲就写到这里。感谢大家的耐心阅读。
课后作业
这里给大家留两个小作业,感兴趣的可以自行测试。
- 请大家使用API请求法自行在虾米音乐上找一首收费下载的歌曲,在不登录账号的情况下对这首歌曲进行下载操作。
- 请大家使用selenium爬取知乎首页的热门话题或话题回答100条。
关于作者
作者是一名即将毕业的大四学生,自学爬虫并作为数个爬虫项目的主要开发者,对各种爬虫有一定的了解和项目经验,目前正在自学分布式爬虫的内容,也将在后面陆续为大家更新。同时作者也是一个狂热的信息安全爱好者,如果有想要和作者交流经验或者想要提出意见的朋友,欢迎在下方留言,我会及时回复大家的。感谢大家的支持。