从零开始hadoop分布式环境搭建
1. Linux虚机换机环境安装
1.1 linux环境安装
1.建议选择虚拟机:VirtualBox
2.Linux版本:Ubuntu
3.安装时选择动态扩展磁盘,最大磁盘容量50G(最大磁盘容量太小,hadoop使用过程中容易出现意想不到的的问题)
4.网络选择桥接网卡(不要选择NAT,不然路由器不会为虚拟机分配独立的IP地址)
5.安装增强功能开启双向开启共享剪切板
6.安装用户使用同样的用户名:如hadoop,在建立分布式环境时需要保证通用的用户名
7.设置hadoop主机名为:hadoop-master hadoop-slave01 hadoop-slave02 (如果忘记设置可以看1.2修改主机名)
ps:具体安装过程不再赘述
安装成功后:ifconfig查看机器ip
机器1的ip

机器2的ip

机器3的ip

1.2 linux主机名修改
- sudo apt-get install vim
- sudo vim /etc/hostname
- 修改为自己想要的域名如:hadoop-master,并保存
- reboot(重启)
- 确认主机名修改成功:hadoop@hadoop-VirtualBox 变为hadoop@hadoop-master
2 ssh和polysh工具安装
ssh和polysh的安装的目的是通过自己的机器去访问虚拟机如:本人macbook去访问virtualbox中的hadoop-master hadoop-slave01 hadoop-slave02 3台虚拟机。
其中ssh需要在四台机器都安装,polysh则只需要在自己本机安装,从而通过一个shell的形式访问3台机器
2.1 ssh安装和使用
- sudo apt-get install ssh (各个虚拟机都要先安装,下面的步骤都可以同ssh远程登录机器操作)
- 在本地机器建立虚拟机host和ip映射关系:/etc/hosts 输入如下内容: 192.168.31.88 hadoop-master
192.168.31.234 hadoop-slave01
192.168.31.186 hadoop-slave02 - ssh hadoop@hadoop-master (输入虚拟机密码)
- ssh-keygen(生成免密登录的几个文件,全部回车即可)
- 切换目标cd .ssh 显示文件ls (id_rsa id_rsa.pub 文件具体意义自己百度)
- 如果要免密登录到一台机器,需要把自己机器的id_rsa.pub文件导入到要登录机器.ssh/authorized_keys文件中
- 到虚拟机上执行命令:echo “ssh-rsa xxxxxxxx” >> .ssh/authorized_keys (”ssh xxx“为本地机器的id_rsa.pub的内容)
- exit关闭虚拟机shell
- ssh hadoop@hadoop-master (不再需要密码)
- 最好是将所有虚拟机的id_rsa.pub也导入到本地机器的authorized_keys中使得互相传文件时不用输密码
- 现在可以无密码的登录三台机器ssh hadoop@hadoop-master ssh hadoop@hadoop-slave01 ssh hadoop@hadoop-slave02
2.2 polysh安装
polysh是批量登录多台机器的工具,如上面如果你要传一个hadoop的安装文件包到虚拟机上,你需要建立三个ssh链接,并在每个ssh的shell中上传同样的文件,而polysh的作用就是你可以在polysh的shell中操作三台机器,如上传文件,只需要一次上传,就在三台虚拟机中都上传了文件。
polysh脚本安装
wget http://guichaz.free.fr/polysh/files/polysh-0.4.tar.gz
tar -zxvf polysh-0.4.tar.gz
cd polysh-0.4
sudo python setup.py install
polysh -help 如果有提示表示安装成功
# 将polysh命令加入path中
echo "export PATH=~/polysh/bin:$PATH" >> ~/.bash_profile
source ~/.bash_profilepolysh使用
echo "alias hadoop-login=\"polysh 'hadoop@hadoop-master' 'hadoop@hadoop-slave<01-02>' \" ">> ~/.bash_profile
source ~/.bash_profile
#以后就可通过hadoop-login来登录三台机器
hadoop-login列如:hadoop主从机器的host和ip映射
sudo sh -c "echo \"192.168.31.88 hadoop-master\n192.168.31.234 hadoop-slave01\n192.168.31.186 hadoop-slave02\n\" >> /etc/hosts"
#这里会要求输入密码(输入hadoop)
cat /etc/hosts
#可以看到如下内容:(:前面是机器hostname,后面是内容)
hadoop@hadoop-slave01 : 192.168.31.88 hadoop-master
hadoop@hadoop-slave01 : 192.168.31.234 hadoop-slave01
hadoop@hadoop-slave01 : 192.168.31.186 hadoop-slave02
hadoop@hadoop-master : 192.168.31.88 hadoop-master
hadoop@hadoop-master : 192.168.31.234 hadoop-slave01
hadoop@hadoop-master : 192.168.31.186 hadoop-slave02
hadoop@hadoop-slave02 : 192.168.31.88 hadoop-master
hadoop@hadoop-slave02 : 192.168.31.234 hadoop-slave01
hadoop@hadoop-slave02 : 192.168.31.186 hadoop-slave023 hadoop安装
3.1 hadoop安装包下载和上传
- 下载hadoop安装包:hadoop-1.2.1-bin.tar.gz
- scp [email protected]:/Users/username/Downloads/hadoop-1.2.1-bin.tar.gz ./ (通过polysh从本地机器将安装包上传到虚拟机上,如果你没有把虚拟机的id_rsa.pub设置到本地机器的authorized_keys文件中,你需要输入本地机器登陆的密码-建议设置)
- ls hadoop*
hadoop@hadoop-slave01 : hadoop-1.2.1-bin.tar.gz
hadoop@hadoop-slave02 : hadoop-1.2.1-bin.tar.gz
hadoop@hadoop-master : hadoop-1.2.1-bin.tar.gz - 下载jdk安装包:jdk-8u111-linux-x64.tar.gz
- scp [email protected]:/Users/username/Downloads/jdk-8u111-linux-x64.tar.gz ./
3.2 hadoop安装
1.安装jdk和配置环境变量
#解压
tar -xzvf jdk-8u111-linux-x64.tar.gz
#设置jdk环境变量path和classpath
echo "export JAVA_HOME=/home/hadoop/workspace/jdk8" >> .bash_profile
echo "export PATH=$JAVA_HOME/bin:$PATH" >> .bash_profile
source .bash_profile
echo "export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar" >> .bash_profile
source .bash_profile
2.安装hadoop和修改配置
#解压
tar -xzvf hadoop-1.2.1-bin.tar.gz
#配置环境变量
echo "export HADOOP_HOME=/home/hadoop/workspace/hadoop" >> .bash_profile
source .bash_profile
echo "export PATH=$HADOOP_HOME/bin:$PATH" >> .bash_profile
source .bash_profile
//修改conf中配置文件
#修改hadoop-env.sh
#修改JAVA_HOME变量
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export JAVA_HOME=/home/hadoop/workspace/jdk8
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=#修改core-site.xml
#设置namenode的地址和端口
#设置hadoop的中间结果和中间日志文件等的临时目录
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://hadoop-master:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/workspace/hadoop_dir/tmpvalue>
property>
configuration>#修改hdfs-site.xml
#配置namenode节点目录
#配置datanode节点目录
#配置备份数量
<configuration>
<property>
<name>dfs.name.dirname>
<value>/home/hadoop/workspace/hadoop_dir/namevalue>
property>
<property>
<name>dfs.data.dirname>
<value>/home/hadoop/workspace/hadoop_dir/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
configuration>#修改mapred-site.xml
#配置map-reduce中的jobtracker的地址和端口
<configuration>
<property>
<name>mapred.job.trackername>
<value>hadoop-master:8021value>
property>
configuration>#修改masters
#配置master机器的hostname列表
hadoop-master#修改slaves
#配置slave机器的hastname列表
hadoop-slave01
hadoop-slave02三台虚拟机按照同样的方式配置成功后,hadoop就安装和配置成功了
hadoop服务启动
1.启动hadoop服务
- ssh hadoop@hadoop-master
- hadoop namenode -format (这个命令只需要执行一次)
正常格式化namenode输出结果如下:
************************************************************/
17/01/07 21:31:32 INFO util.GSet: Computing capacity for map BlocksMap
17/01/07 21:31:32 INFO util.GSet: VM type = 64-bit
17/01/07 21:31:32 INFO util.GSet: 2.0% max memory = 1013645312
17/01/07 21:31:32 INFO util.GSet: capacity = 2^21 = 2097152 entries
17/01/07 21:31:32 INFO util.GSet: recommended=2097152, actual=2097152
17/01/07 21:31:32 INFO namenode.FSNamesystem: fsOwner=hadoop
17/01/07 21:31:32 INFO namenode.FSNamesystem: supergroup=supergroup
17/01/07 21:31:32 INFO namenode.FSNamesystem: isPermissionEnabled=true
17/01/07 21:31:32 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
17/01/07 21:31:32 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
17/01/07 21:31:32 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0
17/01/07 21:31:32 INFO namenode.NameNode: Caching file names occuring more than 10 times
17/01/07 21:31:33 INFO common.Storage: Image file /home/hadoop/workspace/hadoop_dir/name/current/fsimage of size 112 bytes saved in 0 seconds.
17/01/07 21:31:33 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/home/hadoop/workspace/hadoop_dir/name/current/edits
17/01/07 21:31:33 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/home/hadoop/workspace/hadoop_dir/name/current/edits
17/01/07 21:31:33 INFO common.Storage: Storage directory /home/hadoop/workspace/hadoop_dir/name has been successfully formatted.
17/01/07 21:31:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.31.88
************************************************************/- 设置hadoop-master到hadoop-slave01 hadoop-slave02的ssh免密登录
- cd workspace/hadoop/bin/
- sh start-all.sh
正常启动输入日志如下:
starting namenode, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-namenode-hadoop-master.out
hadoop-slave01: starting datanode, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-datanode-hadoop-slave01.out
hadoop-slave02: starting datanode, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-datanode-hadoop-slave02.out
hadoop-master: starting secondarynamenode, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-secondarynamenode-hadoop-master.out
starting jobtracker, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-jobtracker-hadoop-master.out
hadoop-slave02: starting tasktracker, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-hadoop-slave02.out
hadoop-slave01: starting tasktracker, logging to /home/hadoop/workspace/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-hadoop-slave01.out可以看出master会启动:namenode、secondarynamenode、jobtracker三个java进程
slave会启动:datanode、tasktracker两个java进程
- jps 查看是否和日志中启动的进程一致
hadoop@hadoop-master : 6549 SecondaryNameNode
hadoop@hadoop-master : 6629 JobTracker
hadoop@hadoop-master : 6358 NameNode
hadoop@hadoop-master : 6874 Jps
hadoop@hadoop-slave01 : 4096 DataNode
hadoop@hadoop-slave01 : 4197 TaskTracker
hadoop@hadoop-slave01 : 4253 Jps
hadoop@hadoop-slave02 : 5177 TaskTracker
hadoop@hadoop-slave02 : 5076 DataNode
hadoop@hadoop-slave02 : 5230 Jps
- 停止hadoop服务:sh stop-all.sh
stopping jobtracker
hadoop-slave02: stopping tasktracker
hadoop-slave01: stopping tasktracker
stopping namenode
hadoop-slave01: stopping datanode
hadoop-slave02: stopping datanode
hadoop-master: stopping secondarynamenode2.状态查看网站
map-reduce任务情况:http://hadoop-master:50030/jobtracker.jsp
dfs使用情况:http://hadoop-master:50070/dfshealth.jsp
4 执行hadoop任务
百度实现一个wordcount的hadoop jar包任务。百度上很多不在此说明
1.上传本地文件到hdfs文件系统中
- hadoop fs -mkdir input (在hdfs文件系统上创建input文件夹)
- hadoop fs -put input/* input (将本地文件夹input中的文件上传到hdfs文件夹中)
- hadoop fs -ls input
hadoop@hadoop-master:~/workspace$ hadoop fs -ls input
Found 3 items
-rw-r--r-- 3 hadoop supergroup 2416 2017-01-07 22:58 /user/hadoop/input/wiki01
-rw-r--r-- 3 hadoop supergroup 3475 2017-01-07 22:58 /user/hadoop/input/wiki02
-rw-r--r-- 3 hadoop supergroup 4778 2017-01-07 22:58 /user/hadoop/input/wiki03- scp [email protected]:/Users/wenyi/workspace/smart-industry-parent/hadoop-wordcount/target/hadoop-wordcount-1.0-SNAPSHOT.jar ./ (将本地的hadoop程序上传到虚拟机)
- hadoop jar hadoop-wordcount-1.0-SNAPSHOT.jar com.cweeyii.hadoop/WordCount input output (运行hadoop的wordcount单词计数程序)
hadoop调度和运行日志:
hadoop@hadoop-master:~/workspace$ hadoop jar hadoop-wordcount-1.0-SNAPSHOT.jar com.cweeyii.hadoop/WordCount input output
开始执行
input output
17/01/07 23:24:33 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
17/01/07 23:24:33 INFO util.NativeCodeLoader: Loaded the native-hadoop library
17/01/07 23:24:33 WARN snappy.LoadSnappy: Snappy native library not loaded
17/01/07 23:24:33 INFO mapred.FileInputFormat: Total input paths to process : 3
17/01/07 23:24:34 INFO mapred.JobClient: Running job: job_201701072322_0002
17/01/07 23:24:35 INFO mapred.JobClient: map 0% reduce 0%
17/01/07 23:24:41 INFO mapred.JobClient: map 33% reduce 0%
17/01/07 23:24:42 INFO mapred.JobClient: map 100% reduce 0%
17/01/07 23:24:49 INFO mapred.JobClient: map 100% reduce 33%
17/01/07 23:24:51 INFO mapred.JobClient: map 100% reduce 100%
17/01/07 23:24:51 INFO mapred.JobClient: Job complete: job_201701072322_0002
17/01/07 23:24:51 INFO mapred.JobClient: Counters: 30
17/01/07 23:24:51 INFO mapred.JobClient: Map-Reduce Framework
17/01/07 23:24:51 INFO mapred.JobClient: Spilled Records=3400
17/01/07 23:24:51 INFO mapred.JobClient: Map output materialized bytes=20878
17/01/07 23:24:51 INFO mapred.JobClient: Reduce input records=1700
17/01/07 23:24:51 INFO mapred.JobClient: Virtual memory (bytes) snapshot=7414968320
17/01/07 23:24:51 INFO mapred.JobClient: Map input records=31
17/01/07 23:24:51 INFO mapred.JobClient: SPLIT_RAW_BYTES=309
17/01/07 23:24:51 INFO mapred.JobClient: Map output bytes=17460
17/01/07 23:24:51 INFO mapred.JobClient: Reduce shuffle bytes=20878
17/01/07 23:24:51 INFO mapred.JobClient: Physical memory (bytes) snapshot=584658944
17/01/07 23:24:51 INFO mapred.JobClient: Map input bytes=10669
17/01/07 23:24:51 INFO mapred.JobClient: Reduce input groups=782
17/01/07 23:24:51 INFO mapred.JobClient: Combine output records=0
17/01/07 23:24:51 INFO mapred.JobClient: Reduce output records=782
17/01/07 23:24:51 INFO mapred.JobClient: Map output records=1700
17/01/07 23:24:51 INFO mapred.JobClient: Combine input records=0
17/01/07 23:24:51 INFO mapred.JobClient: CPU time spent (ms)=1950
17/01/07 23:24:51 INFO mapred.JobClient: Total committed heap usage (bytes)=498544640
17/01/07 23:24:51 INFO mapred.JobClient: File Input Format Counters
17/01/07 23:24:51 INFO mapred.JobClient: Bytes Read=10669
17/01/07 23:24:51 INFO mapred.JobClient: FileSystemCounters
17/01/07 23:24:51 INFO mapred.JobClient: HDFS_BYTES_READ=10978
17/01/07 23:24:51 INFO mapred.JobClient: FILE_BYTES_WRITTEN=285064
17/01/07 23:24:51 INFO mapred.JobClient: FILE_BYTES_READ=20866
17/01/07 23:24:51 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=7918
17/01/07 23:24:51 INFO mapred.JobClient: File Output Format Counters
17/01/07 23:24:51 INFO mapred.JobClient: Bytes Written=7918
17/01/07 23:24:51 INFO mapred.JobClient: Job Counters
17/01/07 23:24:51 INFO mapred.JobClient: Launched map tasks=3
17/01/07 23:24:51 INFO mapred.JobClient: Launched reduce tasks=1
17/01/07 23:24:51 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9720
17/01/07 23:24:51 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
17/01/07 23:24:51 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=13500
17/01/07 23:24:51 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
17/01/07 23:24:51 INFO mapred.JobClient: Data-local map tasks=3- hadoop fs -ls output/ (查看执行结果)
# _SUCESS表示执行结果的状态
# _logs表示执行的日志
# part-00000表示执行结果
-rw-r--r-- 3 hadoop supergroup 0 2017-01-07 23:24 /user/hadoop/output/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2017-01-07 23:24 /user/hadoop/output/_logs
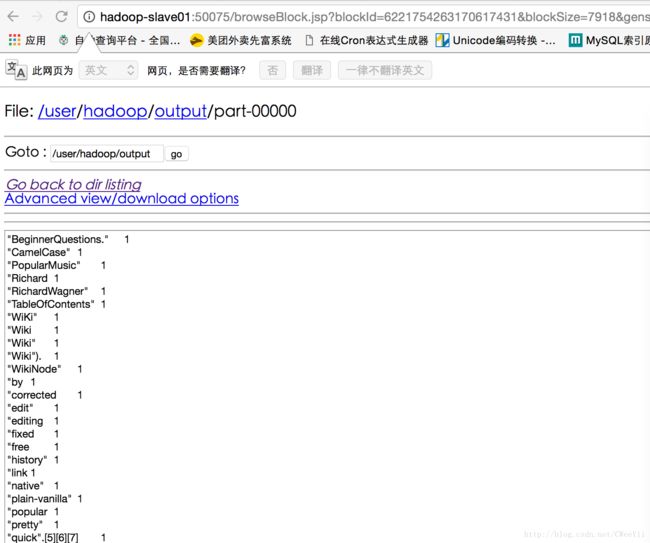
-rw-r--r-- 3 hadoop supergroup 7918 2017-01-07 23:24 /user/hadoop/output/part-00000- hadoop fs -cat output/part-00000 (最终输出结果)
hadoop@hadoop-master:~/workspace$ hadoop fs -cat output/part-00000
"BeginnerQuestions." 1
"CamelCase" 1
"PopularMusic" 1
"Richard 1
"RichardWagner" 1
"TableOfContents" 1
"WiKi" 1
"Wiki 1
"Wiki" 1
"Wiki"). 1
"WikiNode" 1
"by 1
"corrected 1
"edit" 1
"editing 1
"fixed 1
"free 1
"history" 1
"link 1
"native" 1
"plain-vanilla" 1
"popular 1
"pretty" 1
"quick".[5][6][7] 1
"tag" 2
"the 2
"wiki 2- 更加友好的查看结果的方式可以通过:http://hadoop-master:50070/dfshealth.jsp 来查看