机器学习之密度聚类及代码示例
一、密度聚类
密度聚类的思想,在于通过计算样本点的密度的大小来实现一个簇/类别的形成,样本点密度越大,越容易形成一个类,从而实现聚类。
密度聚类算法可以克服基于距离的聚类算法只能发现凸型集合的缺点,其可根据密度的分布发现任意形状的聚类,且对噪声数据不敏感。
因密度聚类算法需计算每个样本点附件的样本密度,因此计算复杂度比较大。
二、DBSCAN算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,一个比较具有代表性的基于密度的聚类算法。与划分聚类、层次聚类不同的是,它将簇定义为密度相连的样本点的最大集合,可在有噪声样本的样本集中发现任意形状的簇。
1、DBSCAN算法的一些概念
a. 对象:可看作样本点
b. 对象的 ![]() - 邻域:给定对象在半径
- 邻域:给定对象在半径 ![]() 内的区域。
内的区域。
c. 核心对象:给定一个数目 m ,如果一个对象的 ![]() - 邻域至少包含 m 个对象,则称该对象为核心对象。
- 邻域至少包含 m 个对象,则称该对象为核心对象。
d. 直接密度可达:如果对象 p 是在 对象 q 的 ![]() - 邻域内,且对象 q 是一个核心对象。我们可以说从对象 q 出发,对象 p 是直接密度可达的。
- 邻域内,且对象 q 是一个核心对象。我们可以说从对象 q 出发,对象 p 是直接密度可达的。
e. 密度可达:如果对象 p 是从对象 q 出发关于 ![]() 和 m(含义同上)直接密度可达的;又有 如果对象 r 是从对象 p 出发关于
和 m(含义同上)直接密度可达的;又有 如果对象 r 是从对象 p 出发关于 ![]() 和 m 直接密度可达的,那么对象 r 是从对象 q 出发关于
和 m 直接密度可达的,那么对象 r 是从对象 q 出发关于 ![]() 和 m 密度可达的;
和 m 密度可达的;
f. 密度相连:若存在一个对象 o ,使得对象 p 和 q 是从 对象 o 关于 ![]() 和 m 密度可达的,那么对象 p 和 q 是关于
和 m 密度可达的,那么对象 p 和 q 是关于 ![]() 和 m 密度相连的。
和 m 密度相连的。
g. 簇:最大的、密度相连对象的集合。
h. 噪声:不包含在任何簇里面的对象
2、DBSCAN算法流程
a. 如果一个样本点的 ![]() - 邻域 包含多于 m 个对象,则创建一个 p 作为核心对象的新簇。
- 邻域 包含多于 m 个对象,则创建一个 p 作为核心对象的新簇。
b. 寻找核心对象的直接密度可达的对象,被合并为一个新的簇。
c. 直到没有点可以更新簇时算法结束。
注意:非核心对象是没有直接密度可达的对象的,它们一般构成了簇的边缘。每个簇可包含多个核心对象。DBSCAN算法有两个参数:一个是 ![]() ,另一个是 m 。
,另一个是 m 。
三、密度最大值聚类
密度最大值聚类也有密度聚类的特点,可识别各种形状的簇,其可根据样本点的局部密度和高局部密度距离来确定聚类中心或噪声样本。
1、局部密度
定义一个样本的局部密度为 ![]() ,
,![]() 有两种表示。
有两种表示。
一种使用Cut-off Kernel的计算表示为:![]() ,即在离该点的一定距离d_c范围内所有点的总数。(i 不等于 j)
,即在离该点的一定距离d_c范围内所有点的总数。(i 不等于 j)
一种使用Gaussian Kernel的计算表示为:![]() ,高斯核函数是根据距离衰减的。(i 不等于 j)
,高斯核函数是根据距离衰减的。(i 不等于 j)
其中d_c为截断距离,为该算法的一个超参数。又因为各个样本 ![]() 的大小是相对的,d_c 的选择是稳健的。
的大小是相对的,d_c 的选择是稳健的。
2、更高局部密度点的最小距离
定义一个样本的更高局部密度点的最短距离为 ![]() ,
, ![]() 的数学表示为
的数学表示为 ![]() 。
。
即在局部密度高于对象(样本) i 的所有对象中,到 对象 i 最近的距离 为 对象 i 的 更高局部密度的最小距离。
对于局部密度最大的对象(样本),设置其 ![]() , 其
, 其 ![]() 为无穷大。
为无穷大。
对于每一个样本点,都有与其相对应的 ![]() 和
和 ![]() ,一般来说,只有局部密度在其周围是最大的那些样本点,它们才会有较大的更高局部密度点最小距离。(周围的情况有两种:一种是周围没有其他样本点,另一种是它的局部密度真的很大。)。
,一般来说,只有局部密度在其周围是最大的那些样本点,它们才会有较大的更高局部密度点最小距离。(周围的情况有两种:一种是周围没有其他样本点,另一种是它的局部密度真的很大。)。
3、簇中心和噪声的识别
对于那些有着比较大的局部密度 ![]() 和 很大的更高局部密度最小距离
和 很大的更高局部密度最小距离 ![]() 的样本点,它们往往会被认为是簇的中心。
的样本点,它们往往会被认为是簇的中心。
而对于那些 很大的更高局部密度最小距离 ![]() 但 局部密度
但 局部密度 ![]() 较小的点 往往会被认为是噪声样本点。
较小的点 往往会被认为是噪声样本点。
将下面这种( ![]() ,
,![]() )对应的图成为决策图。例如如下决策图:
)对应的图成为决策图。例如如下决策图:

其中 1 号和10 号 可被视为聚类中心,而28号可被视为 噪声样本。这种判断是一种定性分析,只是主观地去判断聚类中心/噪声。
在确定聚类中心之后,其他点可以再基于距离/密度的算法进行分类。
四、代码示例
主要是DBSCAN算法与K-Means算法的聚类效果的比较。
from sklearn.datasets.samples_generator import make_moonsX,y_true = make_moons(n_samples=1000,noise=0.15)import matplotlib.pyplot as pltplt.scatter(X[:,0],X[:,1],c=y_true)
plt.show()
import timefrom sklearn.cluster import KMeanst0 = time.time()
kmeans = KMeans(init = 'k-means++',n_clusters=2, random_state=8).fit(X)
t = time.time() - t0plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_)
plt.title('time : %f'%t)
plt.show()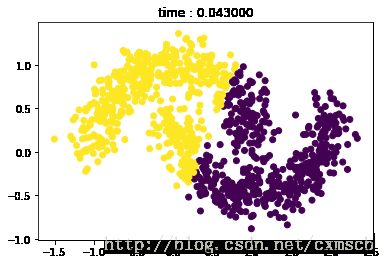
from sklearn.cluster import DBSCANt0 = time.time()
dbscan = DBSCAN(eps=.1,min_samples=6).fit(X)
t = time.time()-t0plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_)
plt.title('time : %f'%t)
plt.show()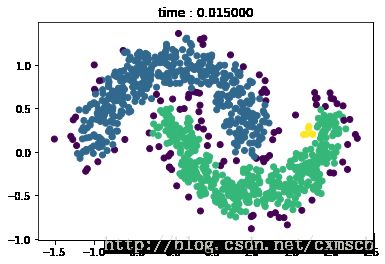
from sklearn.datasets.samples_generator import make_circlesX,y_true = make_circles(n_samples=2000,factor=0.45,noise=0.1)plt.scatter(X[:,0],X[:,1],c=y_true)
plt.show()
t0 = time.time()
kmeans = KMeans(init = 'k-means++',n_clusters=2, random_state=8).fit(X)
t = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_)
plt.title('time : %f'%t)
plt.show()
t0 = time.time()
dbscan = DBSCAN(eps=.1,min_samples=6).fit(X)
t = time.time()-t0
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_)
plt.title('time : %f'%t)
plt.show()
由图可看出,K-means算法实现簇的形状的一些局限性。