Tensorflow框架基本使用方法
本文是《Tensorflow实战google深度学习框架》学习整理笔记。
tensoflow基本运算模型
tensorFlow通过Graph和Session来定义运行的模型和训练,这在复杂的模型和分布式训练上有非常大好处
import tensorflow as tf
#定义运算
a=tf.constant([1.0,2.0],name="a")
b=tf.constant([2.0,3.0],name="b")
result=a+b #result=tf.add(a,b)
#执行计算
sess=tf.Session()
sess.run(result)
#Output:array([ 3., 5.], dtype=float32)
print(a.graph)
print(a.graph is tf.get_default_graph())
#Output:tensorflow计算图的使用
import tensorflow as tf
g1=tf.Graph() #生成新的计算图
with g1.as_default():
v=tf.get_variable("v",shape=[1],initializer=tf.zeros_initializer())
#定义变量v,并初始化为0
g2=tf.Graph()
with g2.as_default():
v=tf.get_variable('v',shape=[1],initializer=tf.ones_initializer())
with tf.Session(graph=g1) as sess:
tf.initialize_all_variables().run()
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))
with tf.Session(graph=g2) as sess:
tf.initialize_all_variables().run()
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))
#Output:[ 0.]
# [ 1.] 张量:对结果的引用(计算路径)
会话:运行计算张量结果
import tensorflow as tf
a=tf.constant([1.0,2.0],name="a") #数据类型匹配
b=tf.constant([2.0,3.0],name="b")
result=tf.add(a,b,name="add")
print(result)
#Output:Tensor("add_6:0", shape=(2,), dtype=float32)
sess=tf.Session() #创建一个会话作为默认会话,利用该会话得到运算结果
with sess.as_default():
print(result.eval()) #tf.Tensor.eval()计算张量取值
print(result.eval(session=sess))
print(sess.run(result))
#Output:[ 3. 5.]
# [ 3. 5.]
# [ 3. 5.]#配置会话——>并行线程数/GPU分配策略/运行超时时间
config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)
sess1=tf.InteractiveSession(config=config)
sess2=tf.Session(config=config)用tensorflow实现神经网络:输入层(线性变换)隐层1(线性变换)输出层
import tensorflow as tf
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) #2*3矩阵
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #3*1矩阵
x=tf.constant([[0.7,0.9]]) #1*2矩阵[[]]
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
sess=tf.Session()
sess.run(w1.initializer) #初始化w1,w2
sess.run(w2.initializer)
print(sess.run(y))
#Output:[[ 3.95757794]]
#init_op=tf.global_variables_initializer()
##initialize_all_variables()初始化所有变量
#sess.run(init_op)
#sess.close()tf.global_variables() #获得当前计算图上的所有变量
tf.trainable_variables() #获取当前图所需优化的参数在训练上由于数据量过大,需要每次取一小部分数据训练(batch)
tensorflow提供了placeholder机制表达一个batch的输入数据
placeholder相当于定义了一个位置,这个位置的数据在程序运行时再指定
这样在程序运行中就不需要生成大量常量来提供输入数据,只需将数据通过placeholder传入tensorflow计算图
定义placeholder时,数据类型要指定,数据维度可以根据提供的数据推导出
import tensorflow as tf
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
x=tf.placeholder(tf.float32,shape=(1,2),name="input")
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
sess=tf.Session()
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.9]]})) #必须对x赋值才能计算,通过对x赋值可以限制每个batch的计算量
#Output:[[ 3.95757794]]import tensorflow as tf
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
x=tf.placeholder(tf.float32,shape=(3,2),name="input")
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
sess=tf.Session()
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.9],[0.1,0.4],[0.5,0.8]]}))
#Output:[[ 3.95757794]
# [ 1.15376544]
# [ 3.16749239]] 神经网络训练二分类问题模型
import tensorflow as tf
from numpy.random import RandomState
batch_size=8
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
x=tf.placeholder(tf.float32,shape=(None,2),name="x-input")
y_=tf.placeholder(tf.float32,shape=(None,1),name="y-input")
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
#定义损失函数及优化器
cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0))) #clip_by_value将一个张量的取值限制在一个范围内
train_step=tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#随机生成模拟数据集
rdm=RandomState(1)
dataset_size=128
X=rdm.rand(dataset_size,2)
Y=[[int(x1+x2<1)] for (x1,x2) in X]
with tf.Session() as sess:
init_op=tf.global_variables_initializer() #先运行计算前向传播的结果
sess.run(init_op)
print("Before train w1:\n",sess.run(w1))
print("Before train w2:\n",sess.run(w2))
STEPS=5000
for i in range(STEPS): #反向传播优化算法
start=(i*batch_size)%dataset_size
end=min(start+batch_size,dataset_size)
#用当前batch里的数据训练
sess.run(train_step,feed_dict={x:X[start:end], y_:Y[start:end]})
if i%1000==0:
total_cross_entropy=sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d training step,cross entropy on all data is %g" % (i,total_cross_entropy))
print("After train w1:\n",sess.run(w1))
print("After train w2:\n",sess.run(w2))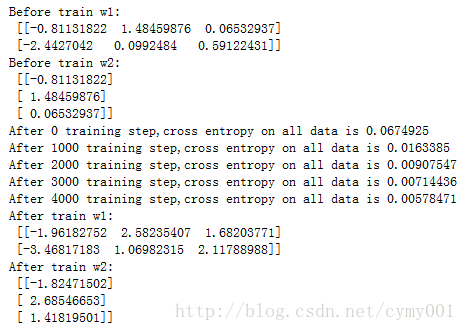
损失函数
边界截断
import tensorflow as tf
v=tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]])
sess=tf.Session()
print(tf.clip_by_value(v,2.5,4.5).eval(session=sess))
#Output: [[ 2.5 2.5 3. ]
# [ 4. 4.5 4.5]]log
import tensorflow as tf
v=tf.constant([1.0,2.0,3.0])
sess=tf.Session()
print(tf.log(v).eval(session=sess))
#Output:[ 0. 0.69314718 1.09861231]两者乘法的区别
import tensorflow as tf
v1=tf.constant([[1.0,2.0],[3.0,4.0]])
v2=tf.constant([[5.0,6.0],[7.0,8.0]])
sess=tf.Session()
with sess.as_default():
print((v1*v2).eval())
print(tf.matmul(v1,v2).eval())
#Output:[[ 5. 12.]
# [ 21. 32.]]
# [[ 19. 22.]
# [ 43. 50.]]在分类问题中,对一个batch的样本量训练,每个样本计算出各个类别的概率后,得到 m×n 维矩阵 n 是一个batch的样本数, m 是分类的类别数。对每行的每个样本可以计算交叉熵,再取 n 样本的交叉熵平均,即得一个batch的平均交叉熵。
import tensorflow as tf
v=tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0]])
sess=tf.Session()
print(tf.reduce_mean(v).eval(session=sess)) #reduce_mean计算v数组全部元素的均值
#Output:3.5分类交叉熵
cross_entropy=tf.nn.softmax_cross_entropy_withlogits(y,y)
回归MSE
mse=tf.reducemean(tf.square(y-y))
自定义损失函数
import tensorflow as tf
v1=tf.constant([1.0,2.0,3.0,4.0])
v2=tf.constant([4.0,3.0,2.0,1.0])
sess=tf.InteractiveSession()
print(tf.greater(v1,v2).eval())
#Output:[False False True True]
print(tf.where(tf.greater(v1,v2),v1,v2).eval())
#Output:[ 4. 3. 3. 4.]import tensorflow as tf
from numpy.random import RandomState
batch_size=8
x=tf.placeholder(tf.float32,shape=(None,2),name="x-input")
y_=tf.placeholder(tf.float32,shape=(None,1),name="y-input")
w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1))
y=tf.matmul(x,w1)
loss_less=10
loss_more=1
loss=tf.reduce_sum(tf.where(tf.greater(y,y_),(y-y_)*loss_more,(y_-y)*loss_less))
train_step=tf.train.AdamOptimizer(0.001).minimize(loss)
rdm=RandomState(1)
dataset_size=128
X=rdm.rand(dataset_size,2)
Y=[[x1+x2+rdm.rand()/10.0-0.05] for (x1,x2) in X]
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
STEPS=5000
for i in range(STEPS):
start=(i*batch_size)%dataset_size
end=min(start+batch_size,dataset_size)
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
print(sess.run(w1))