AMOS分析技术:验证性因子分析介绍;信度与效度指标详解
基础准备
上一篇文章,草堂君介绍了测量模型分析的内容,阐述了探索性因子分析(EFA)和验证性因子分析(CFA)的区别与联系,大家可以点击下方文章链接回顾:
AMOS分析技术:测量模型分析;聊聊验证性因子分析(CFA)与探索性因子分析(EFA)的异同点
接下来草堂君将用几篇文章来详细介绍如何用AMOS进行多种验证性因子分析,包括一阶斜交验证性因子分析、一阶直交验证性因子分析和二阶验证性因子分析。
验证性因子分析的类型
前面介绍了,验证性因子分析与探索性因子分析不同,分析者经过大量的调研和文献阅读,其实心中已经有了测量模型(问卷量表结构)的大体框架。例如,某市场调研机构承接了一项来自于某视频网站的市场调研项目,设计的量表中包括三个潜在变量(一级指标),每个潜在变量对应四个量表题项:

验证性因子分析就是通过样本数据来验证上方分析者假设的模型结构(量表题项与潜在变量的对应关系,潜在变量之间的关系)是否与实际数据情况一致。需要注意,量表题项的答案都要采用相同的利克特等级结果,例如五级量表可以是非常不符合、比较不符合、一般符合、比较符合和非常符合。
验证性因子分析根据假设模型的潜在变量之间是否相关,可以分为斜交验证性因子分析和直交验证性因子分析。如下图所示,直交模型表示潜在变量之间不相关,相互独立,需要设置三个潜在变量之间的协方差为0;而斜交模型表示潜在变量之间是相关的,不需要对三个潜在变量之间的协方差做任何限制:
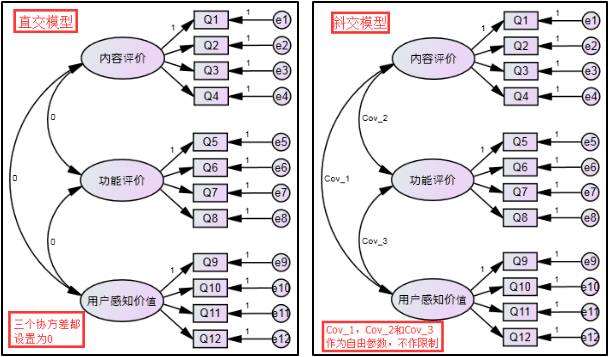
如果三个潜在变量之间相关,而且相关系数比较高(大于0.6),那么说明三个潜在变量还可以被另一个潜在变量所解释,可以进行二阶验证性因子分析,如下图所示:

在上面这个模型中,草堂君标注了两个注意点:1、内容评价、功能评价和用户感知价值相互之间高度相关,说明能够被同一个潜在变量解释,因此内容评价、功能评价和用户感知价值三个潜在变量在这个关系中是因变量,箭头指向它们。2、新的潜在变量一定要根据实际研究情况来对其定义(到底什么因素会同时影响内容评价、功能评价和用户感知价值),如果实在无法定义,那么也就没有必要做二阶验证性因子分析了。所有验证性分析都需要特别注意,不能完全依靠数据来建立和修改模型,而应该把数据结果作为线索,指引分析者思考在模型是否有遗漏的关系没有考虑到,再根据实际情况修正模型。
信度与效度
看过草堂君信度与效度文章的朋友应该还记得:虽然求取不同领域信度和效度的分析方法会有不同,但是信度和效度的内涵是一致的:信度代表内部一致性,稳定性和聚集性,效度代表准确性和区分性。大家可以点击下面文章回顾信度和效度: 数据分析技术:信度与效度;信度和效度代表什么?
在量表型问卷的分析中,信度表示同一个潜在变量下的测量变量的相关性(聚集性),如果同一个潜在变量下的测量变量高度相关,说明信度高。效度表示潜在变量之间的区分性,如果效度高,那么区分性好,同一个潜在变量下的测量变量相关性强,不同潜在变量下的测量变量相关性弱。由此可见,测量模型的效度高,信度一般也高;而信度高,效度不一定高。
验证性因子分析能够告诉我们什么信息呢?其实就是信度和效度信息。在社会学、管理学和经济学领域,凡是运用量表型问卷发表的文章(毕业论文和学术期刊)都会要求作者对潜在变量(测量模型)的信度和效度进行描述,只不过指标不是两个,而是一套,如下表所示:
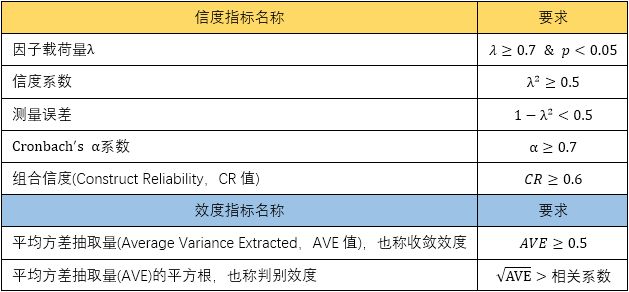
因子载荷量:潜在变量到测量变量的标准化回归系数(上面测量模型图中内容评价对Q1、Q2、Q3和Q4的标准化回归系数)。因子载荷量越大,代表潜在变量对测量变量的解释能力越强,表示“指标信度”越好。因子载荷量在AMOS测量模型图中显示的位置如下图所示:

信度系数:因子载荷量的平方,相当于测量变量(因变量)和潜在变量(自变量)建立的一元线性回归方程的R方值。信度系数越高,表示潜在变量对测量变量的解释能力越强,“指标信度”越好。
测量误差:1减去信度系数的值;信度系数越大,测量误差越小,表示潜在变量对测量变量的解释能力越强,“指标信度”越好。
克隆巴赫α系数:在介绍SPSS的可靠性分析菜单功能时,介绍过这个指标的计算公式和含义,大家可以回顾文章:SPSS分析技术:问卷(试卷)的信度分析;以某机构的《英语学习策略》问卷调查数据为例 。这个指标越高,表示“内部一致性信度”越好。需要注意:Amos的验证性因子分析无法直接获得克隆巴赫α系数,需要用SPSS来进行计算。
组合信度(Construct Reliability,CR值):通过因子载荷量计算的表示内部一致性信度质量的指标值,计算公式如下:

平均方差抽取量(Average Variance Extracted,AVE值):通过因子载荷量计算的表示收敛效度的指标值。计算公式如下:

看起来AVE值和CR值的计算公式是一样的,其实差别很大。CR值用的是因子载荷值加和的平方,题项之间相关性越强,潜在变量对它们的解释能力也越强,因子载荷值加和的平方就越大,内部一致性就越好。AVE值用的是因子载荷值平方的和,代表潜在变量对所有测量变量的综合解释能力,AVE值越大,潜在变量能够同时解释它所对应的题项能力就越强,反回来,题项表现潜在变量性质的能力也越强(收敛于一点),收敛效度越好。
AVE的平方根:可以将理解成潜在变量内部数据的相关系数。根据Fornell和Larcker给出的标准,如果AVE算术平方根要大于潜在变量之间相关系数绝对值,说明内部相关性要大于外部相关性,表示潜在变量之间是有区别的,那么判别效度高。依然使用上面的案例举例说明,建立判别效度表格:

红色的数字表示AVE的平方根,黑色的数字表示潜在变量之间的相关系数。可以发现,红色的数字都比黑色的数字大,说明测量模型的判别效度是符合要求的。
总结一下
草堂君今天介绍了验证性因子分析的几种不同类型,以及每种类型的使用情况。同时介绍了通过验证性因子分析能够获得的信度和效度指标。信度指标包括因子载荷量、信度系数、测量误差、克隆巴赫α系数(SPSS求取)、组合信度(公式求取);效度指标包括收敛效度AVE值(公式求取)和判别效度(相关系数对比)。
后面几篇文章将具体介绍如何使用AMOS软件进行斜交验证性因子分析、直交验证性因子分析和二阶验证性因子分析,并根据AMOS分析结果整理出能够在论文中使用的信度与效度指标结果表格。
平台的文章都是一文一例,所有例题的数据文件都已上传到QQ群(群号:134373751),需要对照练习Amos数据分析技术的朋友可以前往下载。
温馨提示:
数据分析课程私人定制,一对一辅导,添加微信(possitive2)咨询!目前推出的一对一课程:《问卷分析与分析思维培养》课程。
生活统计学QQ群:134373751,用于分享文章提到的各种案例资料、软件、数据文件等。支持各种资料的直接下载和百度云盘下载。
生活统计学微信交流群,用于各自行业的数据研究项目及其成果交流分享;由于人数大于100人,请添加微信possitive2,拉您入群。
数据分析咨询,请点击首页下方“互动咨询”板块,获取咨询流程!
草堂君的统计基础导航页文章已经整理发表,可以前往任意电商网站购买
