八大深度学习最佳实践

翻译 | AI科技大本营
参与 | 刘畅
[AI 科技大本营导读]2017年,许多的人工智能算法得到了实践和应用。名博Hack Noon作者 Brian Muhia 认为想要玩转人工智能,不仅要拥有必要的数学背景知识,还需要拥有实际的人工智能项目经验。
因此,Muhia参加了一个叫AI Grant的人工智能比赛,并在去年9月,申请了 fast.ai 网站上杰里米·霍华德(Jeremy Howard)教授的“实用深度学习”(Practical Deep Learning for Coders,第二版)的第一部分。
仅用了7周多,Muhia 就学会了如何使用8种人工智能技术来进行工程实践,并进行了归纳整理。
对于每一种实践方法,Muhia 都用了简短的 fastai 代码来概述总体思想,并指出该技术是否普遍适用,例如:对于图像识别和分类,自然语言处理,对结构化数据或协同过滤进行建模),或者对于某种特定的深度学习的数据类型。
原作者注:在这篇博文中,图像识别技术使用的数据集来自于Kaggle上的两个竞赛。
Dogs vs. Cats: Kernels Edition, Dog Breed Identification
链接:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/
Planet: Understanding the Amazon from Space
链接:https://www.kaggle.com/c/planet-understanding-the-amazon-from-space
文中提到的所有实践方法都是通过 Jupyter Notebook 这个高效接口来完成的,PyTorch 本身和 fastai 深度学习库均支持 Jupyter Notebook。
Muhia 设计了一个类似于狗与猫竞赛的分类任务,即分类蜘蛛与蝎子图片(Spiders vs. Scorpions)。通过在谷歌上搜索“蜘蛛”和“沙漠蝎子”,作者从Google Images上下载了约1500张图片,然后作者从中去除了非jpg图像和不完整的图像。剩下大约815张图片用作任务分类的数据。
训练集中每个类 [spiders,scorpions] 有290张图片,在测试/验证集中有118张蜘蛛图片和117张蝎子图片。通过一系列训练后,作者采用的模型拥有高达95%的分类准确率。

如何构建任意类别(world-class)的图像分类器
▌八大深度学习最佳实践
1. 通过微调的VGG-16和ResNext50模型来完成迁移学习(用于计算机视觉和图像分类)
通常,对于图像分类任务,采用神经网络架构效果普遍较好,针对具体问题,你可以通过微调效果较好的神经网络,来大幅改善分类器的性能。。
50层的卷积神经网络-残差网络 ResNext50 就是一个不错的选择。该网络使用了 ImageNet 数据集上的1000种类别进行了预训练,效果表现非常好。它可以将图像数据中的特征进行提取并多次利用。
当我们想要用它来解决实际问题时,我们只需替换掉最后的输出层,即用一个二维的输出层替换原来 ImageNet 任务中的1000维输出层。这两个输出类别存在于上面代码片段中的PATH文件夹中。
对于蜘蛛与蝎子分类任务的挑战,我认为以下几点需要注意:

请注意,训练集文件夹的两个内容本身就是文件夹,每个文件夹包含了290张图像。
下图显示了一个微调过程的示例图,它将最终层输出从1000维调成了10维:
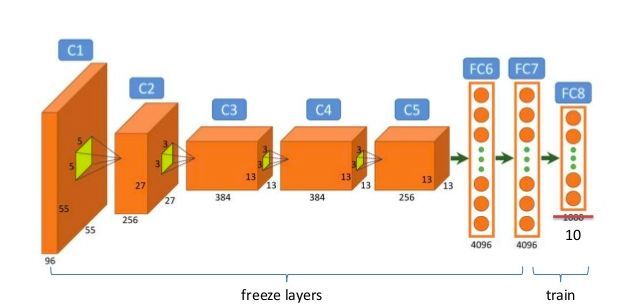
2. 周期性学习率(通常适用)
学习率应该是训练深层神经网络最重要的超参数。一种普遍的做法是:在一个非自适应设置中(即不使用 Adam、AdaDelta 或它们变体的算法),由深度学习工程师/研究员进行多组并行实验,每组实验在学习率上有微小的差异。这种做法对数据和参与人员的要求都极高,经验的缺失或者数据集庞大且易出错都可能使整个过程消耗更多的时间。
然而,在2015年,美国海军研究实验室的Leslie N. Smith发现了一种自动搜索最有学习率的方法,即从极小值开始,在网络中运行一些小批量( mini-batch )数据,调整学习率的同时观察损失值的变化,直到损失值开始降低。
这里有两个fast.ai的学生解释周期性学习速率方法的博客。
http://teleported.in/posts/cyclic-learning-rate/
https://techburst.io/improving-the-way-we-work-with-learning-rate-5e99554f163b
在fastai中,你只需在学习的对象上运行lr_find()函数,学习率退火算法就能发挥效用。同时,sched.plot()函数可以用来确定与最优学习速率相一致的点。

0.1似乎是一个不错的学习率
下面论文中的数据表明:0.1的学习率表现更好,能达到最高的准确性,并且在衰减速度上比原始的学习率和指数级的学习率快了两倍。
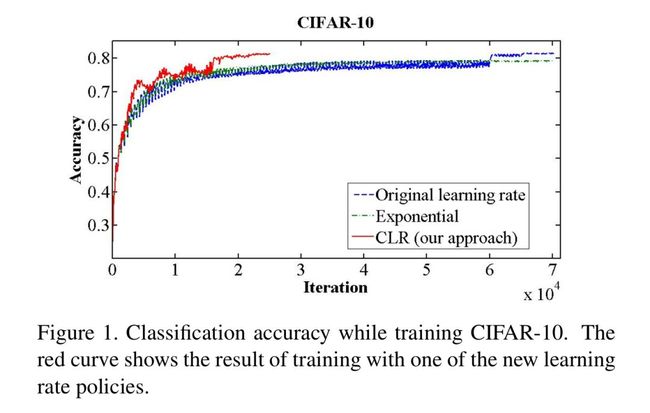
Smith (2017) “Cyclical learning rates for training neural networks.”
3. 可重启的随即梯度下降
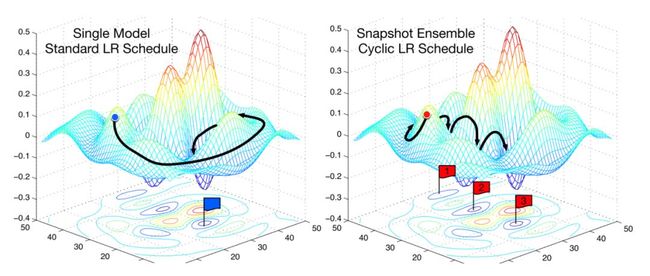
SGD vs. snapshot ensembles (Huang et al., 2017)
另一种加速随机梯度下降的方法是,随着训练的进行,逐渐降低学习的速率。这种方法有助于观察学习速率的变化与损失值的改善是否一致。当模型的参数接近最佳权重时,你需要采取更小的移动步长,因为如果步长过大,你可能会跳过损失值表面的最佳区域。
如果学习率和损失值之间的关系不稳定,即如果学习率中一个微小的变化就导致损失值的巨大变化。这就表明,当前的最优点还不在一个稳定的区域(如上面的图2所示)。应对策略则是周期性地提高学习率。
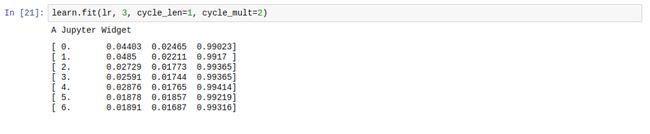
这里的“周期”是指提高学习率的次数。在 fastai 中,可以使用 cycle_len 和 cycle_mult 参数来设置 learner.fit。
在上面的图2中,学习速率被重置了3次。在使用正常的学习速率时间表时,通常需要更长的时间才能找到最佳的损失。在这种情况下,开发人员会等待所有的时间点完成后,再尝试不同的学习速率。
4. 数据增强(计算机视觉和图像分类任务 —现在的方法)
数据增强可以用来增加现有的训练和测试数据量。对于图像问题,则取决于数据集中具有对称性质的图像数量。
一个例子是蜘蛛与蝎子图片分类的挑战。 在这个数据集中,许多图片进行了垂直变换后,里面的动物仍能正常显示。 这就是所谓的 transforms_side_on。

从上到下,注意图片不同角度的缩放和反射
5. 测试时间进行数据增强(计算机视觉和图像分类任务 —现在的方法)
我们也可以在推理时间(或测试时间)中使用数据增强。在推理预测的时候,你可以使用测试集中的单个图像来完成数据增强。但是,如果访问的测试集中的每个图像都能随机生成几个增量图片,则该过程会变得更加鲁棒。在fastai中,我在预测时使用了每个测试图像的4个随机增量,并将各个预测的平均值用作该图像的预测。
6. 用预训练的循环神经网络替换词向量(word vectors)
这是一种不使用词向量就可以获得任意类别的情感分析框架方法。它的原理是,将需要分析的整个训练数据进行集中,并从中构建一个深层的循环神经网络语言模型。当训练的模型精度增高时,就将此时模型的编码器保存,并使用从编码器中获得的嵌入来构建情感分析模型。
用循环神经网络要优于单词向量获得的嵌入矩阵,它可以比单词向量更好地追踪长距离的依赖性。
7. 时间反向传播(BPTT)(用于NLP)
深度循环神经网络的隐藏状态往往会随着反向传播的训练时间变得越来越臃肿,也变得难以处理。
例如,在处理字符的循环神经网络时,如果你有一百万个字符,那么你就需要建立一百万个隐藏状态向量以及他们对应的历史信息。为了训练神经网络,我们还需要对每个字符执行相同数量级的链式计算法则。这将消耗巨大的内存和计算资源。
所以,为了降低内存需求,我们设置了最大的反向传播距离。由于循环神经网络中的每个循环相当于一个时间步长,所以限制反向传播并保持隐藏状态的历史层数的任务被称为时间反向传播。虽然这个数字的值决定了模型计算的时间和内存要求,但它同时提高了模型处理长句或动作序列的能力。
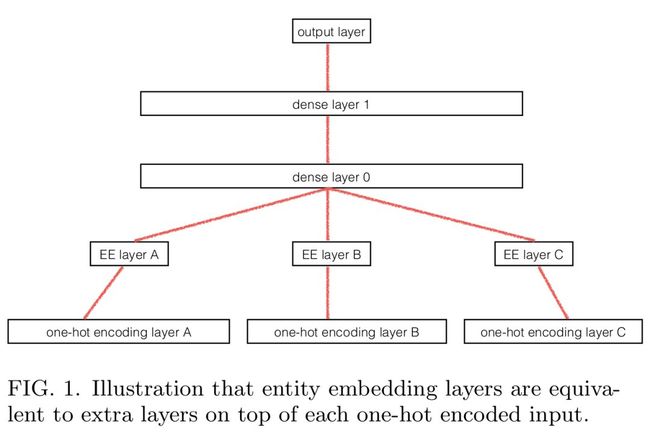
8. 分类变量实体向量化。 (用于结构化数据和NLP)
当对结构化的数据集进行深度学习时,该方法能将包含连续数据的列,例如在线商店中的价格信息,和分类数据的列,例如,日期和接送地点等,以此进行区分。然后,这些分类列的单热 (one-hot) 编码过程会被转换为指向神经网络全连接层的查找表。因此,神经网络模型就有机会绕过列的分类性质,去了解那些被忽略的分类变量/列的信息。
这种方法可以用来学习多年的数据集的周期性规律,例如一周中的哪一天销售量最大,公众假期之前和之后发生了什么事。
这样做的最终结果是能产生一个非常有效的方法,它能帮助协同过滤和预测产品的最优定价。这也是目前所有拥有表格数据的公司进行标准数据分析和预测的方法。
▌结语
这一年来,深度学习进步斐然。大批研究人员和从业人员的努力,使得数据集和CPU越来越完善,开源的深度学习框架和工具也越来越多。
目前,我们还没有创造出通用人工智能,但是我们已经可以将深度学习运用到不同的领域了。不过,我更期待人工智能在于教育和医学领域的运用,尤其是复兴生物技术。因为,这会创造出更多的可能性。
作者 | Brian Muhia
原文链接
https://medium.com/@muhia/8-deep-learning-best-practices-i-learned-about-in-2017-700f32409512
新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:[email protected],期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:[email protected]
如果以上两者你都参与不了,那就加入AI科技大本营的读者群,成为营长的真爱粉儿吧!后台回复:读者群,加入营长的大家庭,添加营长请备注自己的姓名,研究方向,营长邀请你入群。
热文精选
比特币的价格今年会达到10万美元吗?有人用蒙特卡罗方法预测了一下
Tomaso Poggio:深度学习需要从炼金术走向化学
一文教你如何用Python预测股票价格
开发者AI职业指南:CSDN《AI技术人才成长路线图V1.0》重磅发布
企业智能化升级之路:CSDN《2017-2018中国人工智能产业路线图V1.0》重磅发布
蒋涛:重新回归的我,将带领CSDN全方位升级,为AI转型者打造一站式平台
速成班出来的AI人才,老板到底要不要?6位导师告诉你行业真相
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的

☟☟☟点击 | 阅读原文 | 查看更多精彩内容