68款大规模机器学习数据集,涵盖CV、语音、NLP | 十年资源集

参加 2019 Python开发者日,请扫码咨询 ↑↑↑
作者 | 琥珀
出品 | AI科技大本营(ID:rgznai100)
此前营长为大家分享过不少机器学习相关数据集的资源,例如 Mozilla 的 1400 小时开源语音数据集;ApolloScape 的大规模自动驾驶数据集;腾讯 AI Lab 的 “Tencent ML-Images” 项目,甚至还有谷歌团队推出的 Google Dataset Search(Google 数据集搜索)……
对于日常从事模型训练的研究人员来讲,无论是图像处理还是语音识别,都离不开一些高质量的数据集,通过它们以改善模型的性能。
近日,reddit 论坛上,一位网友发帖分享了 datasetlist.com 的网站链接,得到了不少同行们的点赞。据了解上面集合了从 2009 年 ImageNet 发布以来共计 68 项机器学习相关的大规模数据集,囊括计算机视觉(46 项)、自然语言处理(18 项)、语音(4 项)三大类别,帮助用户快速找到相应的数据集。由此,我们还可以看到自 2015 年以来,大规模数据集的不断涌现也暗示着人工智能技术作为集大成者的快速演进。
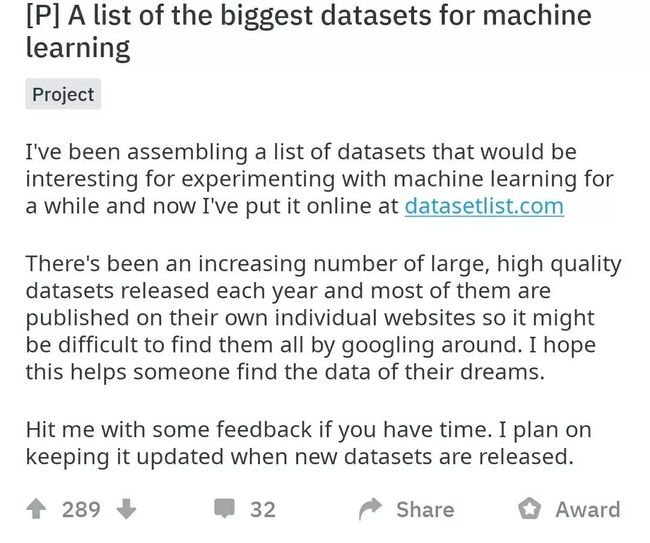
这套数据集搜索列表的出现,也满足了不少强迫症患者对于选择 / 整理数据集的想法。不过,也正如这位网友所言:这个数据集列表的形式将有待完善和丰富,设计这个网页的目的也是希望接下来不断更新新的数据集,同时,用户也可以通过邮箱、Twitter、Facebook 等方式订阅以获取最新内容。
下面,让营长介绍下该数据集列表的主要内容:
语音识别:
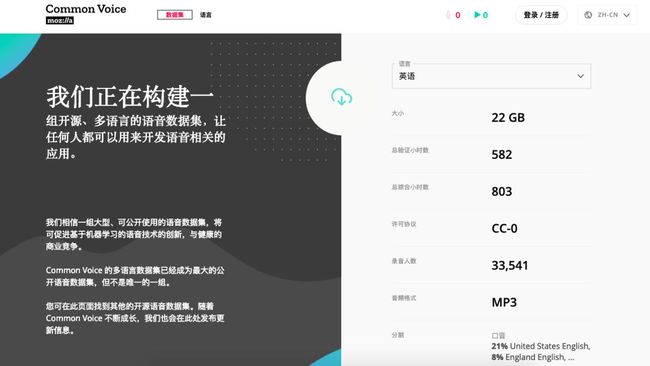
Mozilla Common Voice
2019 年 3 月 1 日,由 Mozilla 基金会发起的 Common Voice 项目,发布新版语音识别数据集,包括来自 42000 名贡献者,超过 1400 小时的语音样本数据,涵盖包括英语、法语、德语、荷兰语、汉语在内的 18 种语言。
地址:https://voice.mozilla.org/zh-CN
NSynth
Google Audioset
LibriSpeech
计算机视觉
IBM Diversity in Faces Dataset
IBM 推出的“人脸多样性”(Diversity in Faces Dataset,DiF)是一个庞大而多样化的数据集,与以前的数据集相比,DiF 数据集提供了更均衡的分布和更广泛的面部图像覆盖率。DiFferences 提供了 100 万注释的数据集人类面部图像。
地址:
https://www.research.ibm.com/artificial-intelligence/trusted-ai/diversity-in-faces/

NVIDIA Flickr-Faces-HQ 数据集
英伟达推出的 Flicker 人脸高清数据集(FFHQ)由 70,000 个高质量的 PNG 格式图像组成,分辨率为 1024*1024。这些图片在年龄、种族和图像背景方面有很强的多样性,并且还有如眼镜、太阳镜、帽子等元素。
地址:
https://github.com/NVlabs/ffhq-dataset

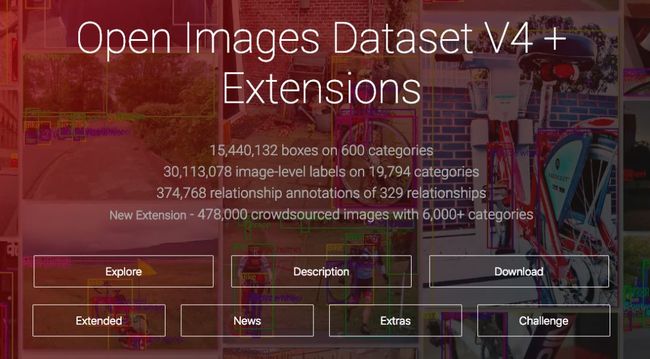
Google Open Images V4
Open Images 是一个包含约 900 万个 URL 的数据集,由谷歌在 2018 年 4 月 30 日开放,它包含在 190 万张图片上针对 600 个类别的 1540 万个边框盒。
地址:
https://storage.googleapis.com/openimages/web/index.html
Tencent ML- Images
Tencent ML- Images 是最大的开源多标签图像数据集,包括 17,609,752 个训练和 88,739 个验证图像 URL,最多可注释 11,166 个类别。
地址:
https://github.com/Tencent/tencent-ml-images

Youtube-8M 2018
Youtube-8M 2018 是一个大型标记视频数据集,由 600 万个 YouTube 视频 ID 组成,目前具有 4700 多个视觉实体标签,同时它还配备了数十亿帧和音频片段的预先计算的视听功能。
地址:
https://research.google.com/youtube8m/index.html

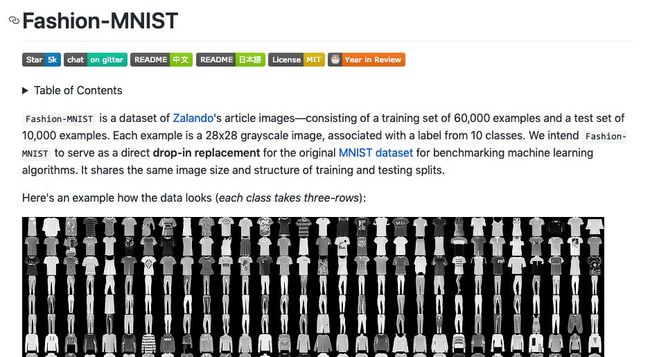
Fashion MNIST
Fashion-MNIST 由德国研究机构 Zalando Research 公布,包含 60000 个样本,测试集包含 10000 个样本,分为 10 类,每一个都是 28×28 的灰度图。
地址:
https://github.com/zalandoresearch/fashion-mnist
当然,此外还有 MegaFace、ImageNet 等非常经典的数据集,以下营长就不一一列举了。
GQA
Berkeley Deep Drive (BDD100K)
HighD - The Highway Drone Data
Comma 2k19
HD1K Benchmark Suite
VQA Visual Question Answering
ApolloScape
nuScenes
MURA
Synscapes
fastMRI Dataset
Mapillary Vistas
Places2
Youtube-BoundingBoxes
ADE20K
WildDash
Oxford RobotCar Dataset
Recipe1M
MegaFace
SceneNet RGB-D
MS-Celeb-1M
SYNTHIA
UMD Faces
comma.ai
Spacenet
CompCars
ShapeNet
WIDER Face
WIDER
LSUN
Visual Genome
Cityscapes
ACTIVITYNET
COCO
Yahoo Flickr Creative Commons 100M
Pascal part
Flickr30k
KITTI
SVHN Street View House Numbers
ImageNet
自然语言处理
SQuAD
斯坦福问答数据集(SQuAD)是一个全新的阅读理解数据集,由工作人员基于一系列维基百科文章中的提问和答案组成,其中每个问题的答案是来自相应阅读段落的一段文本片段或区间。其中包括超过 500 篇文章中超过 100,000 个问答配对,使得 SQuAD 显著大于以前的阅读理解数据集。SQuAD2.0 结合了 SQuAD1.1 中的 100,000 个问题。
地址:
https://rajpurkar.github.io/SQuAD-explorer/

此外还有:
MultiNLI
CoQA
Spider 1.0
HotpotQA
Question Pairs (Quora)
Yelp open dataset
Facebook bAbI
MS MARCO
NewsQA
Datasets from DBPedia, Amazon, Yelp, Yahoo!, Sogou, a
DeepMind Q&A dataset
Text Classification Datasets
SNLI
Billion Words
Stanford Sentiment Treebank
Large Movie Review Dataset
Princeton WordNet
(本文为 AI科技大本营原创文章,转载请微信联系 1092722531)
◆
精彩推荐
◆

推荐阅读:
数学界“诺奖”Abel Prize迎来首位女性得主
NLP实践:对话系统技术原理和应用
提升效率,这十个Pandas技巧必不可少!
超常用的Python代码片段 | 备忘单
没有新芯片,没有大核弹,黄教主这次给大家带来了个PRADA
淘宝、飞猪、闲鱼都挂了,阿里云却正常?!
要钱还是要命? 比特币正悄悄杀死你...
前阿里 P9 级员工称离婚是模拟测试,已回滚复婚!
教训!学 Python 没找对路到底有多惨?
![]()
❤点击“阅读原文”,查看历史精彩文章。