Solr6 多词匹配度查询搜索及排序的解决方案
前言
操作系统:CentOS6.9
Solr版本:6.1,测试发现Solr6的都是可以的,7的没有试
需求:
数据有不同数据的类型(可以认为是不同数据库表,Solr中有一个字段专门用来标识数据的类型),
不同的字段类型,
数据还有不同的日期
现在要查询一个长文本,查询结果要满足以下要求:
- 匹配度越高的排名越靠前,
- 数据类型越重要的排名越靠前,
- 字段越重要的排名越靠前,
- 时间越近的排名越靠前
像这种情况如何合理的控制Solr查询的命中的数量和质量呢?
构造以下文本片段:
我要买绝地武士星空仪
买绝地武士星空仪
买星空绝地武士仪
黑武士星空仪
我要买小米
进一步分析我们会发现其实我们要做的主要是两件事儿
- 查询
- 排序
查询:
在使用多个条件进行查询的时候,或者对查询内容进行分词的时候,Solr可能返回满足所有条件的结果或者满足部分条件的结果。solrQueryParser控制这一行为,这个属性是配置在schema.xml文件里的:
属性值只可以是"AND"和"OR"。
AND将返回所有条件(分词)的结果
OR将返回满足任一条件的结果
这里使用OR操作,edismax的mm参数可以控制匹配度
不过这个配置项需要删掉,不知道是为什么,加上这个配置后,就算是"OR",也达不到想要的效果
查询的时候会自动对要查询的关键字进行分词,分词后它们的关系是OR
另外可以再在要查询的关键字前后加上"*"
OK查询完了,下面说说排序,妈的,最难的就是这个
##排序
最简单的排序就是设置sort参数,一般是sort一个时间,不过这里光一个sort参数是不能满足需求的,怎么办呢?
有三种实现方式:
-
定制Lucene的boost算法,加入自己希望的业务规则;
-
使用Solr的edismax实现的方法,通过bf查询配置来影响boost打分。
-
在建索引的schema时设置一个字段做排序字段,通过它来影响文档的总体boost打分。
具体怎么用的,可以去网上查,这里仅提供实现思路及解决方案
这三种实现方式归根到底其实就是就是Solr打分方式
这是采用第二种方案,使用edismax可以控制Solr的评分排序规则,
使用mm,来控制模糊查询的匹配程度
使用bq,来控制不同数据类型的重要性
使用qf,来控制不同的字段的重要性
使用bf,来控制日期的重要性
使用pf,来控制要查询的文本片段之间的关系
mm参数:
用来控制模糊查询的匹配程序如要搜索以下文本片段:我要买绝地武士星空仪
查询的时候会进行分词分成以下几个词:我,要,买,绝地,武士,星空,仪

一个文本片段分词分成了7个,mm配置为80%那么,7个词至少得匹配6个
###bq参数:
bq是boost query的简写,给符合查询条件的添加添加权重,
比如说bq设置为title:“shanghai”^10.0,它的意思就是给所有查询结果中条件字段名为title字段值为shanhai的条件添加权重为10.0,
多个条件的话用空格隔开
###qf参数:
这个参数用于指定q参数的条件要查哪个些字段,并给这些字段添加不同的权重
如:title^10.0意思为查询title字段,并给这个字段添加权重为10.0
多个字段用空格隔开
bf参数:
意思是通过数学公式来影响评分,不局限在qf中的字段
如:recip(div(ms(NOW+8HOUR,capture_time),86400000),1,1,1)
recpi函数:recip(x,m,a,b)转换为数据公式为:a/(m*x + b),a,b,m为常数,x为变量
div函数:除法div(a,b)表示:a/b
ms函数:表示两个日期相减
NOW+8HOUR表示当前时间加上8个小时,Solr使用的是UTC时区与比东8区少了8个小时
capture_time:Solr中一个数字类型的字段
86400000:一天时间的毫秒数
通过这个函数就可以根据capture_time生成不同的权重,capture_time离当时时间越近权重越大,越远权重越小,如果是未来则为负
###pf参数:
可以配置pf参数与qf参数一样
pf和qf参数的格式是一样的,不同的是pf会更加注重短语匹配
比如说:搜索"绝地武士星空仪"
绝地武士星空仪的权重就比星空绝地武士仪的权重大
##配置
网上好多地方都是直接用一个URL链接进行配置的,其实可以直接配置到Solr里面,这样每次查询的时候就不用加这么多参数了。
可以把edismax配置到solrconfig.xml文件的"/select" 的requestHandler
explicit
edismax
80%
*:*
recip(div(ms(NOW+8HOUR,capture_time),86400000),1,1,1)
docType:(真实 | 虚拟)^10.0 OR docType:聊天^5.0
SUMMARY^10.0 MSG^10.0 TITLE^10.0 KEYWORD^10.0 FILE_NAME^5.0 CONTENT^1.0
SUMMARY^10.0 MSG^10.0 TITLE^10.0 KEYWORD^10.0 FILE_NAME^5.0 CONTENT^1.0
10
*,score
中间遇到下面这个问题也记录一下
问题描述:
用Solr搜索一个比较长的文本片段搜不出结果。比如说,搜索:"我一定要买绝地武士星空仪"或者搜索:“我要买绝地武士星”。构造的数据中有好多相关的数据,但是都没有显示出来。
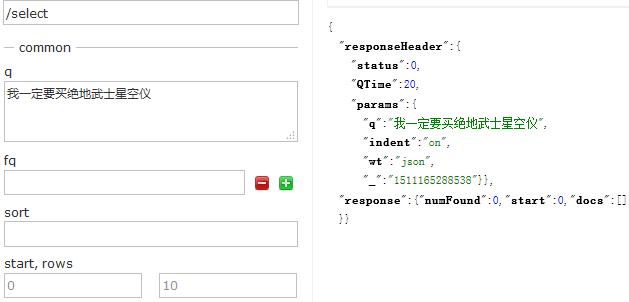
原因:
Solr的配置文件schema.xml中配置了对要搜索的关键字进行完全匹配,即必须包含所有搜索的关键字,而且只能多不能少,比如说"我一定要买美丽的绝地武士的星空仪"是可以被搜索出来的,“我要绝地武士星空仪"就搜索不出来(少了"一定”)。而"我要买绝地武士星"之所以搜不出来是因为Solr认为星空仪、星空是一个词,因此进行了索引,但是认为"星"不是一个词,没有进行索引所以查不出来。