基于R统计分析——样本与分布
1 数据抽样
(1) 简单随机抽样
sample(x,size,replace=FALSE,prob=NULL)其中,x表示待抽取对象,一般情况下以向量形式表示;size为非负整数,表示想要抽取样本的个数;replace表示是否为可放回抽样,默认不放回;prob用于设置各个抽样样本的抽样概率,默认等概率抽样。
例子:
library(MASS)
data(Insurance)
sub1=sample(nrow(Insurance),10,replace=T)
sub2=sample(nrow(Insurance),10)
sub3=sample(nrow(Insurance),10,replace=T,prob=c(rep(0,nrow(Insurance)-1),1))
#设置最后一个样本的抽样概率为1,其他样本被抽到的概率为0备注:sample为自带函数
(2) 分层抽样
strata(data, stratanames=NULL, size, method=c(“srswor”,”srswr”,”poisson”,”systematic”), description=FALSE)其中,data为待抽样数据集;stratanames中放置进行分层所依据的变量名称;size用于设置各层中将要抽出的观测样本数,其顺序应该与数据集中变量各水平出现顺序一致,且在使用该函数前,应当首先对数据集按照该变量进行升序排列;method参数用于选择抽样方法,分别对应于无放回、有放回、泊松、系统抽样,默认无放回;pik用于设置各层中各样本的抽样概率;description参数用于选择是否输出含有各层基本信息的结果。
sub4=strata(Insurance,stratanames="District",size=c(1,2,3,4),method="srswor")
#按照街区进行分层,且1~4个街区中无放回抽取1-4个样本
(3) 整群抽样
cluster(data, clustername, size, method=c(“srswor”,”srswr”,”poisson”,”systematic”), description=FALSE)与分层抽样稍微不同的是,clustername指用来划分群的变量的名称,而size不再为分层抽样中的一个向量,这里仅为一个正整数,表示需要抽取的群数。
sub5=cluster(Insurance,clustername="District",size=2,method="srswor")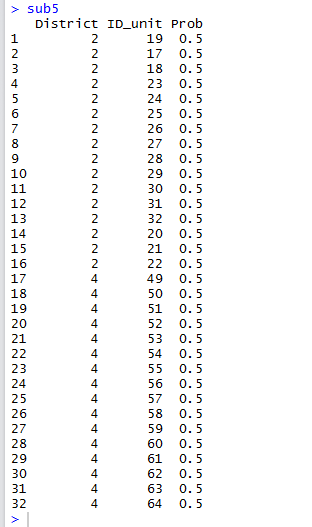
备注:strata和cluster函数需要加载sampling包
2 概率分布
R中提供了18个分布函数
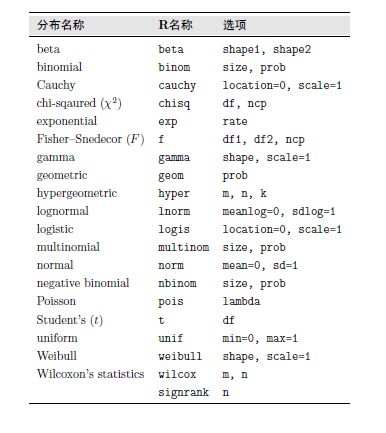
对于所给的分布名称,加前缀“d”(代表密度函数, density)就得到R的密度函数(对于离散分布, 指分布律); 加前缀“p”(代表分布函数或概率, CDF)就得到R的分布函数; 加前缀“q”(代表分位函数, quantile)就得到R的分位数函数; 加前缀“r”(代表随机模拟, random)就得到R的随机数发生函数.