Multi-Hop Knowledge Graph Reasoning with Reward Shaping
Multi-Hop Knowledge Graph Reasoning with Reward Shaping
- 来源
- 背景
- motivation:
- 模型
- 改进
- 实验
- 代码
来源
2018 EMNLP
Xi Victoria Lin Richard Socher Caiming Xiong
Salesforce Research
{xilin,rsocher,cxiong}@salesforce.com
背景
大型的知识图谱可以支持下游的许多NLP应用,例如语义搜索、对话生成,由于知识图谱的不完整性,知识图谱并不是非常实用,因此知识图谱上的推理非常重要,可以用来补充知识图谱。目前知识推理的方法主要分为了两类:一类是基于embedding的方法,另外一种是基于路径的方法。基于embedding的方法忽略符号的组合性,在比较复杂的推理任务上存在局限性。基于路径的方法,目前很多工作将多跳推理建模为一个序列决策问题,使用强化学习方法寻找有效的路径。
motivation:
目前很多工作将多跳推理建模为一个序列决策问题,使用强化学习的方法寻找有效的路径,MINERVA是其中非常重要的一个模型,它使用强化学习训练了一个端到端的模型用于知识图谱上的查询问答,给定一个关系和源实体,训练智能体在没有预先计算好路径的条件下在知识图谱上搜索候选答案。这种基于行走的查询问答在训练时有很大的挑战:
- 智能体到达一个正确的答案,但是在训练图中缺少到源实体的链接,因此不会获得任何奖励。(假阴)
- 没有正确的路径用于训练,智能体只会偶然的到达一个正确的答案(假阳)。
基于路径的问答框架存在上述两个问题,本文针对上面提到的两个问题进行了改进。1. 预训练一个目前最好的基于embedding的模型去估计一个软奖励对于目标实体的正确性没有办法确定 2. 随机的进行action dropout, 在训练的每一步随机的锁住外向边,来鼓励选择多样性的路径,淡化假阳的负面影响2. 没有正确的路径用于训练,智能体只会偶然的到达一个正确的答案(假阳)。基于路径的问答框架存在上述两个问题,本文针对上面提到的两个问题进行了改进。1. 预训练一个目前最好的基于embedding的模型去估计一个软奖励对于目标实体的正确性没有办法确定 2. 随机的进行action dropout, 在训练的每一步随机的锁住外向边,来鼓励选择多样性的路径,淡化假阳的负面影响
模型
问题定义: 对于给定的一个查询 ( e s , r q , ? ) (e_s, r_q,?) (es,rq,?), e s e_s es是一个源实体, r q r_q rq是感兴趣的关系,通过在知识图谱上搜索,得到可能的答案集合 E o = e o E_o={e_o} Eo=eo, 由于知识图谱的不完整性, ( e s , r q , e o ) (e_s, r_q,e_o) (es,rq,eo)不在知识图谱中
强化学习框架:
将路径寻找问题建模为马尔科夫决策过程,马尔科夫决策过程包括如下几部分:
state: s t = ( e t , ( e s , r q ) ) ∈ S s_t = (e_t, (e_s, r_q))\in S st=(et,(es,rq))∈S, e t e_t et表示第t步访问的实体
action: 第t步可能的动作 A t ∈ A A_t \in A At∈A 包含所有 e t e_t et的外向边,即 { ( r ′ , e ′ ) ∣ ( e t , r ′ , e ′ ) } \{(r^\prime, e^\prime)|(e_t, r^\prime,e^\prime)\} {(r′,e′)∣(et,r′,e′)}, 对于每个 A t A_t At中加入自循环,当搜索数没有到达固定步数时,自循环代表停止的意思。
转移函数: 转移函数 δ : S × A ⟶ S \delta: S\times A\longrightarrow S δ:S×A⟶S, 定义为 δ ( s t , A t ) = δ ( e t , ( e s , r q ) , A t ) \delta(s_t, A_t) = \delta(e_t, (e_s,r_q),A_t) δ(st,At)=δ(et,(es,rq),At)
奖励函数: 如果智能体搜索结束后最终到达目标实体,则获得奖励1
R b ( s T ) = 1 { ( e s , r q , e t ) ∈ G } R_b(s_T) = 1\{(e_s,r_q,e_t) \in G\} Rb(sT)=1{(es,rq,et)∈G}
策略网络:
一个具体的action表示为关系embedding 和 下一个节点的embedding的组合 a t = ( r t + 1 , e t + 1 ) ] a_t = (r_{t+1}, e_{t+1})] at=(rt+1,et+1)]
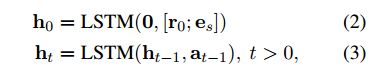
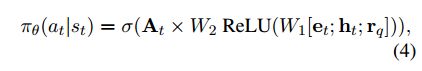
优化


改进
知识库奖励:
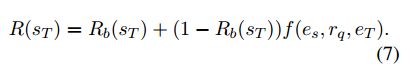
如果 e T e_T eT是一个正确的实体,智能体获得奖励1,否则智能体获得的奖励用 f ( e s , r q . e T ) f(e_s,r_q.e_T) f(es,rq.eT)估计,函数 f ( e s , r q , e T ) f(e_s,r_q,e_T) f(es,rq,eT)预训练的打分函数,f 函数可以使用目前存在较好的打分函数
action dropout:
强化学习训练算法根据策略概率分布进行策略采样,利用策略梯度算法更新参数。对于一个智能体来说,可能会通过不相关的路径到达正确的目标实体,例如 Obama −endorsedBy→ McCain −liveIn→ U.S. ←locatedIn− Hawaii,并不能推断出 b o r n I n ( O b a m a , H a w a i i ) bornIn(Obama, Hawaii) bornIn(Obama,Hawaii)。
判断路径的质量并非简单的事情,目前的方法很大程度上依赖于最终的奖励指导搜索。通常虚假路径的数量要多于正确的数量,虚假的路径通常被更早的发现,接下来的搜索会加剧这样的虚假路径,尤其是对于扇入输出较大的实体节点。
为了缓解这种情况,本文采用action-dropout的方法,在强化学习中智能体采样中,随机的mask一部分扇出边。
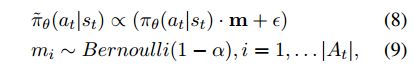
ϵ \epsilon ϵ 是用来平滑 m = 0 m=0 m=0时的情况,此时是一个均匀分布
实验
数据集:
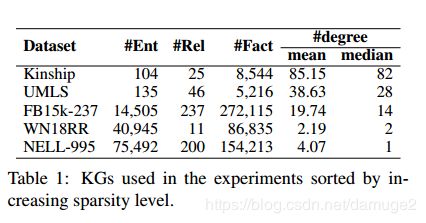
路径查询任务:

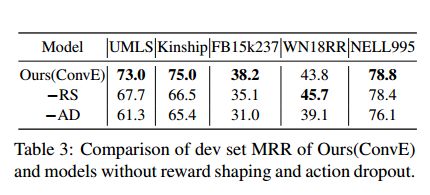
消融测试:
收敛速度:

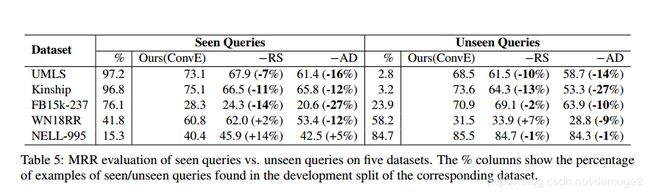
不同的关系类型:

代码
代码