从编程实现角度学习 Faster R-CNN(附极简实现)
从编程实现角度学习 Faster R-CNN(附极简实现)
本文原载于知乎专栏「人工智障的深度瞎学之路」
Faster R-CNN 的极简实现: github: simple-faster-rcnn-pytorch(http://t.cn/RHCDoPv )
本文插图地址(含五幅高清矢量图):draw.io(http://t.cn/RQzroe3 )
1 概述
在目标检测领域, Faster R-CNN 表现出了极强的生命力, 虽然是 2015 年的论文(https://arxiv.org/abs/1506.01497),但它至今仍是许多目标检测算法的基础,这在日新月异的深度学习领域十分难得。Faster R-CNN 还被应用到更多的领域中, 比如人体关键点检测、目标追踪、 实例分割还有图像描述等。
现在很多优秀的 Faster R-CNN 博客大都是针对论文讲解,本文将尝试从编程角度讲解 Faster R-CNN 的实现。由于 Faster R-CNN 流程复杂,符号较多,容易混淆,本文以 VGG16 为例,所有插图、数值皆是基于 VGG16+VOC2007 。
1.1 目标
从编程实现角度角度来讲, 以 Faster R-CNN 为代表的 Object Detection 任务,可以描述成:
给定一张图片, 找出图中的有哪些对象, 以及这些对象的位置和置信概率。
 目标检测任务
目标检测任务
1.2 整体架构
Faster R-CNN 的整体流程如下图所示。
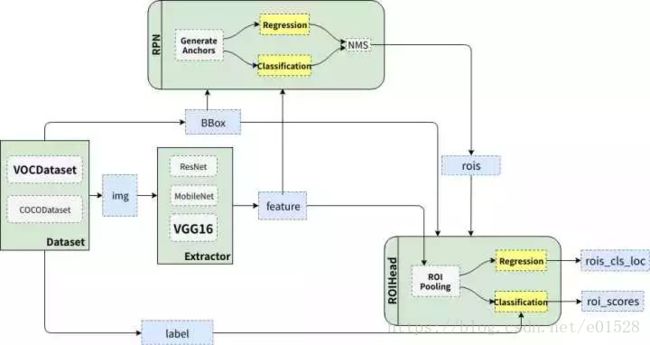
Faster R-CNN 整体架构
从编程角度来说, Faster R-CNN 主要分为四部分(图中四个绿色框):
Dataset:数据,提供符合要求的数据格式(目前常用数据集是 VOC 和 COCO)
Extractor: 利用 CNN 提取图片特征
features(原始论文用的是 ZF 和 VGG16,后来人们又用 ResNet101)RPN(Region Proposal Network): 负责提供候选区域
rois(每张图给出大概 2000 个候选框)RoIHead: 负责对
rois分类和微调。对 RPN 找出的rois,判断它是否包含目标,并修正框的位置和座标
Faster R-CNN 整体的流程可以分为三步:
提特征: 图片(
img)经过预训练的网络(Extractor),提取到了图片的特征(feature)Region Proposal: 利用提取的特征(
feature),经过 RPN 网络,找出一定数量的rois(region of interests)。分类与回归:将
rois和图像特征features,输入到RoIHead,对这些rois进行分类,判断都属于什么类别,同时对这些rois的位置进行微调。
2 详细实现
2.1 数据
对与每张图片,需要进行如下数据处理:
图片进行缩放,使得长边小于等于 1000,短边小于等于 600(至少有一个等于)。
对相应的 bounding boxes 也也进行同等尺度的缩放。
对于 Caffe 的 VGG16 预训练模型,需要图片位于 0-255,BGR 格式,并减去一个均值,使得图片像素的均值为 0。
最后返回四个值供模型训练:
images : 3×H×W ,BGR 三通道,宽 W,高 H
bboxes: 4×K , K 个 bounding boxes,每个 bounding box 的左上角和右下角的座标,形如(Y_min,X_min, Y_max,X_max), 第 Y 行,第 X 列。
labels:K, 对应 K 个 bounding boxes 的 label(对于 VOC 取值范围为 [0-19])
scale: 缩放的倍数, 原图 H'×W'被 resize 到了 HxW(scale=H/H' )
需要注意的是,目前大多数 Faster R-CNN 实现都只支持 batch-size=1 的训练(http://t.cn/RQzdbYt 和http://t.cn/R5vaVPi 实现支持 batch_size>1)。
2.2 Extractor
Extractor 使用的是预训练好的模型提取图片的特征。论文中主要使用的是 Caffe 的预训练模型 VGG16。修改如下图所示:为了节省显存,前四层卷积层的学习率设为 0。Conv4_3 的输出作为图片特征(feature)。conv4_3 相比于输入,下采样了 16 倍,也就是说输入的图片尺寸为 3×H×W,那么feature的尺寸就是 C×(H/16)×(W/16)。VGG 最后的三层全连接层的前两层,一般用来初始化 RoIHead 的部分参数,这个我们稍后再讲。总之,一张图片,经过 extractor 之后,会得到一个 C×(H/16)×(W/16) 的 feature map。
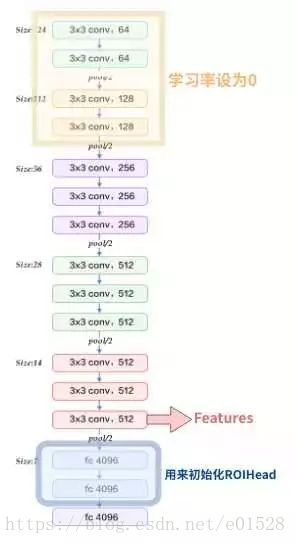
Extractor: VGG16
2.3 RPN
Faster R-CNN 最突出的贡献就在于提出了 Region Proposal Network(RPN)代替了 Selective Search,从而将候选区域提取的时间开销几乎降为 0(2s -> 0.01s)。
2.3.1 Anchor
在 RPN 中,作者提出了anchor。Anchor 是大小和尺寸固定的候选框。论文中用到的 anchor 有三种尺寸和三种比例,如下图所示,三种尺寸分别是小(蓝 128)中(红 256)大(绿 512),三个比例分别是 1:1,1:2,2:1。3×3 的组合总共有 9 种 anchor。
然后用这 9 种 anchor 在特征图(feature)左右上下移动,每一个特征图上的点都有 9 个 anchor,最终生成了 (H/16)× (W/16)×9 个anchor. 对于一个 512×62×37 的 feature map,有 62×37×9~ 20000 个 anchor。 也就是对一张图片,有 20000 个左右的 anchor。这种做法很像是暴力穷举,20000 多个 anchor,哪怕是蒙也能够把绝大多数的 ground truth bounding boxes 蒙中。
2.3.2 训练 RPN
RPN 的总体架构如下图所示:

RPN 架构
anchor 的数量和 feature map 相关,不同的 feature map 对应的 anchor 数量也不一样。RPN 在Extractor输出的 feature maps 的基础之上,先增加了一个卷积(用来语义空间转换?),然后利用两个 1x1 的卷积分别进行二分类(是否为正样本)和位置回归。进行分类的卷积核通道数为 9×2(9 个 anchor,每个 anchor 二分类,使用交叉熵损失),进行回归的卷积核通道数为 9×4(9 个 anchor,每个 anchor 有 4 个位置参数)。RPN 是一个全卷积网络(fully convolutional network),这样对输入图片的尺寸就没有要求了。
接下来 RPN 做的事情就是利用(AnchorTargetCreator)将 20000 多个候选的 anchor 选出 256 个 anchor 进行分类和回归位置。选择过程如下:
对于每一个 ground truth bounding box (
gt_bbox),选择和它重叠度(IoU)最高的一个 anchor 作为正样本对于剩下的 anchor,从中选择和任意一个
gt_bbox重叠度超过 0.7 的 anchor,作为正样本,正样本的数目不超过 128 个。随机选择和
gt_bbox重叠度小于 0.3 的 anchor 作为负样本。负样本和正样本的总数为 256。
对于每个 anchor, gt_label 要么为 1(前景),要么为 0(背景),而 gt_loc 则是由 4 个位置参数 (tx,ty,tw,th) 组成,这样比直接回归座标更好。
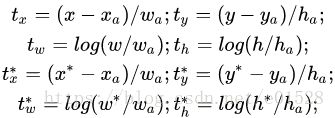
计算分类损失用的是交叉熵损失,而计算回归损失用的是 Smooth_l1_loss. 在计算回归损失的时候,只计算正样本(前景)的损失,不计算负样本的位置损失。
2.3.3 RPN 生成 RoIs
RPN 在自身训练的同时,还会提供 RoIs(region of interests)给 Fast RCNN(RoIHead)作为训练样本。RPN 生成 RoIs 的过程 (ProposalCreator) 如下:
对于每张图片,利用它的 feature map, 计算 (H/16)× (W/16)×9(大概 20000)个 anchor 属于前景的概率,以及对应的位置参数。
选取概率较大的 12000 个 anchor
利用回归的位置参数,修正这 12000 个 anchor 的位置,得到 RoIs
利用非极大值((Non-maximum suppression, NMS)抑制,选出概率最大的 2000 个 RoIs
注意:在 inference 的时候,为了提高处理速度,12000 和 2000 分别变为 6000 和 300.
注意:这部分的操作不需要进行反向传播,因此可以利用 numpy/tensor 实现。
RPN 的输出:RoIs(形如 2000×4 或者 300×4 的 tensor)
2.4 RoIHead/Fast R-CNN
RPN 只是给出了 2000 个候选框,RoI Head 在给出的 2000 候选框之上继续进行分类和位置参数的回归。
2.4.1 网络结构
RoIHea d 网络结构
d 网络结构
由于 RoIs 给出的 2000 个候选框,分别对应 feature map 不同大小的区域。首先利用ProposalTargetCreator 挑选出 128 个 sample_rois, 然后使用了 RoIPooling 将这些不同尺寸的区域全部 pooling 到同一个尺度(7×7)上。下图就是一个例子,对于 feature map 上两个不同尺度的 RoI,经过 RoIPooling 之后,最后得到了 3×3 的 feature map.

RoIPooling
RoI Pooling 是一种特殊的 Pooling 操作,给定一张图片的 Feature map (512×H/16×W/16) ,和 128 个候选区域的座标(128×4),RoI Pooling 将这些区域统一下采样到 (512×7×7),就得到了 128×512×7×7 的向量。可以看成是一个 batch-size=128,通道数为 512,7×7 的 feature map。
为什么要 pooling 成 7×7 的尺度?是为了能够共享权重。在之前讲过,除了用到 VGG 前几层的卷积之外,最后的全连接层也可以继续利用。当所有的 RoIs 都被 pooling 成(512×7×7)的 feature map 后,将它 reshape 成一个一维的向量,就可以利用 VGG16 预训练的权重,初始化前两层全连接。最后再接两个全连接层,分别是:
FC 21 用来分类,预测 RoIs 属于哪个类别(20 个类 + 背景)
FC 84 用来回归位置(21 个类,每个类都有 4 个位置参数)
2.4.2 训练
前面讲过,RPN 会产生大约 2000 个 RoIs,这 2000 个 RoIs 不是都拿去训练,而是利用ProposalTargetCreator 选择 128 个 RoIs 用以训练。选择的规则如下:
RoIs 和 gt_bboxes 的 IoU 大于 0.5 的,选择一些(比如 32 个)
选择 RoIs 和 gt_bboxes 的 IoU 小于等于 0(或者 0.1)的选择一些(比如 128-32=96 个)作为负样本
为了便于训练,对选择出的 128 个 RoIs,还对他们的gt_roi_loc 进行标准化处理(减去均值除以标准差)
对于分类问题, 直接利用交叉熵损失. 而对于位置的回归损失, 一样采用 Smooth_L1Loss, 只不过只对正样本计算损失. 而且是只对正样本中的这个类别 4 个参数计算损失。举例来说:
一个 RoI 在经过 FC 84 后会输出一个 84 维的 loc 向量. 如果这个 RoI 是负样本, 则这 84 维向量不参与计算 L1_Loss
如果这个 RoI 是正样本, 属于 label K, 那么它的第 K×4, K×4+1 ,K×4+2, K×4+3 这 4 个数参与计算损失,其余的不参与计算损失。
2.4.3 生成预测结果
测试的时候对所有的 RoIs(大概 300 个左右) 计算概率,并利用位置参数调整预测候选框的位置。然后再用一遍极大值抑制(之前在 RPN 的ProposalCreator用过)。
注意:
在 RPN 的时候,已经对 anchor 做了一遍 NMS,在 RCNN 测试的时候,还要再做一遍
在 RPN 的时候,已经对 anchor 的位置做了回归调整,在 RCNN 阶段还要对 RoI 再做一遍
在 RPN 阶段分类是二分类,而 Fast RCNN 阶段是 21 分类
2.5 模型架构图
最后整体的模型架构图如下:
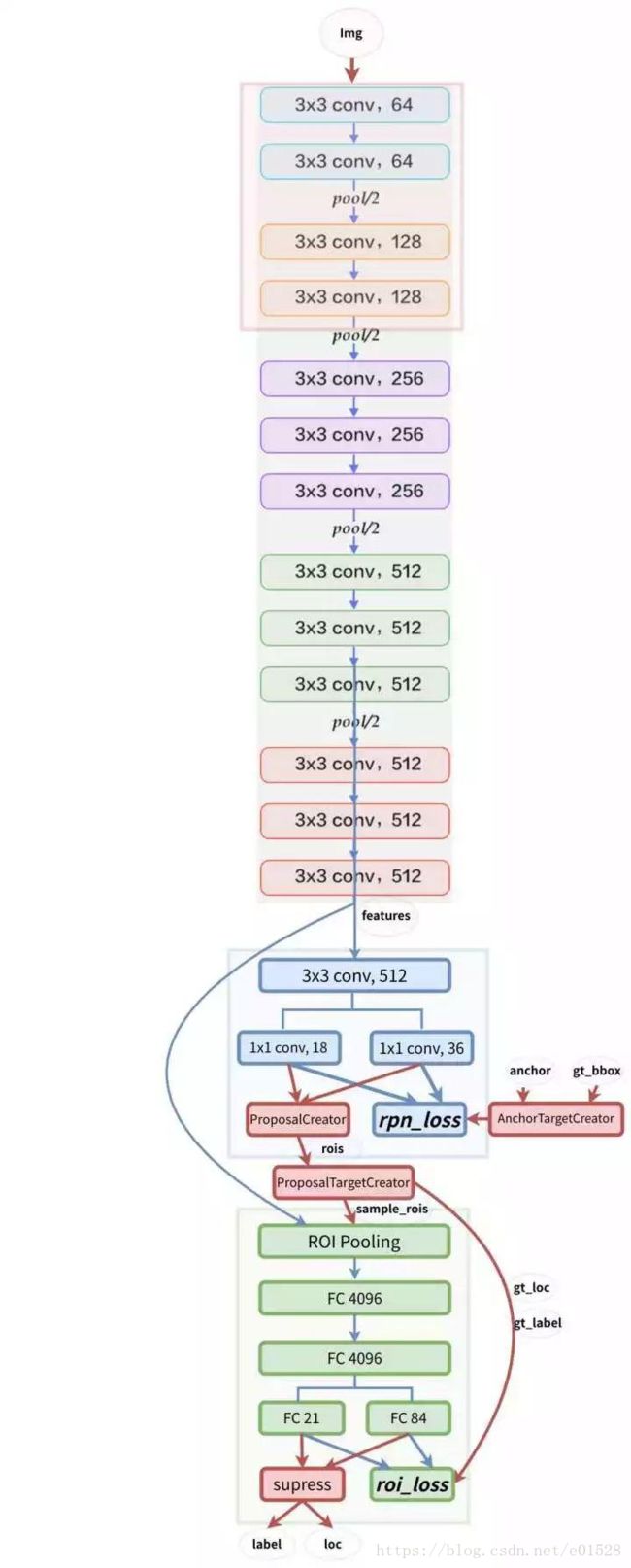 整体网络结构
整体网络结构
需要注意的是: 蓝色箭头的线代表着计算图,梯度反向传播会经过。而红色部分的线不需要进行反向传播(论文了中提到了ProposalCreator生成 RoIs 的过程也能进行反向传播,但需要专门的算法,https://arxiv.org/abs/1512.04412)。
3 概念对比
在 Faster RCNN 中有几个概念,容易混淆,或者具有较强的相似性。在此我列出来并做对比,希望对你理解有帮助。
3.1 bbox anchor RoI loc
BBox:全称是 bounding box,边界框。其中 Ground Truth Bounding Box 是每一张图中人工标注的框的位置。一张图中有几个目标,就有几个框 (一般小于 10 个框)。Faster R-CNN 的预测结果也可以叫 bounding box,不过一般叫 Predict Bounding Box.
Anchor:锚?是人为选定的具有一定尺度、比例的框。一个 feature map 的锚的数目有上万个(比如 20000)。
RoI:region of interest,候选框。Faster R-CNN 之前传统的做法是利用 selective search 从一张图上大概 2000 个候选框框。现在利用 RPN 可以从上万的 anchor 中找出一定数目更有可能的候选框。在训练 RCNN 的时候,这个数目是 2000,在测试推理阶段,这个数目是 300(为了速度)我个人实验发现 RPN 生成更多的 RoI 能得到更高的 mAP。
RoI 不是单纯的从 anchor 中选取一些出来作为候选框,它还会利用回归位置参数,微调 anchor 的形状和位置。
可以这么理解:在 RPN 阶段,先穷举生成千上万个 anchor,然后利用 Ground Truth Bounding Boxes,训练这些 anchor,而后从 anchor 中找出一定数目的候选区域(RoIs)。RoIs 在下一阶段用来训练 RoIHead,最后生成 Predict Bounding Boxes。
loc: bbox,anchor 和 RoI,本质上都是一个框,可以用四个数(y_min, x_min, y_max, x_max)表示框的位置,即左上角的座标和右下角的座标。这里之所以先写 y,再写 x 是为了数组索引方便,但也需要千万注意不要弄混了。 我在实现的时候,没注意,导致输入到 RoIPooling 的座标不对,浪费了好长时间。除了用这四个数表示一个座标之外,还可以用(y,x,h,w)表示,即框的中心座标和长宽。在训练中进行位置回归的时候,用的是后一种的表示。
3.2 四类损失
虽然原始论文中用的4-Step Alternating Training 即四步交替迭代训练。然而现在 github 上开源的实现大多是采用近似联合训练(Approximate joint training),端到端,一步到位,速度更快。
在训练 Faster RCNN 的时候有四个损失:
RPN 分类损失:anchor 是否为前景(二分类)
RPN 位置回归损失:anchor 位置微调
RoI 分类损失:RoI 所属类别(21 分类,多了一个类作为背景)
RoI 位置回归损失:继续对 RoI 位置微调
四个损失相加作为最后的损失,反向传播,更新参数。
3.3 三个 creator
在一开始阅读源码的时候,我常常把 Faster RCNN 中用到的三个Creator弄混。
AnchorTargetCreator: 负责在训练 RPN 的时候,从上万个 anchor 中选择一些 (比如 256) 进行训练,以使得正负样本比例大概是 1:1. 同时给出训练的位置参数目标。 即返回gt_rpn_loc和gt_rpn_label。ProposalTargetCreator: 负责在训练 RoIHead/Fast R-CNN 的时候,从 RoIs 选择一部分 (比如 128 个) 用以训练。同时给定训练目标, 返回(sample_RoI,gt_RoI_loc,gt_RoI_label)ProposalCreator: 在 RPN 中,从上万个 anchor 中,选择一定数目(2000 或者 300),调整大小和位置,生成 RoIs,用以 Fast R-CNN 训练或者测试。
其中AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标,只在训练阶段用到,ProposalCreator是 RPN 为 Fast R-CNN 生成 RoIs,在训练和测试阶段都会用到。三个共同点在于他们都不需要考虑反向传播(因此不同框架间可以共享 numpy 实现)
3.4 感受野与 scale
从直观上讲,感受野(receptive field)就是视觉感受区域的大小。在卷积神经网络中,感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。我的理解是,feature map 上的某一点f对应输入图片中的一个区域,这个区域中的点发生变化,f可能随之变化。而这个区域外的其它点不论如何改变,f的值都不会受之影响。VGG16 的 conv4_3 的感受野为 228,即 feature map 上每一个点,都包含了原图一个 228×228 区域的信息。
Scale:输入图片的尺寸比上 feature map 的尺寸。比如输入图片是 3×224×224,feature map 是 512×14×14,那么 scale 就是 14/224=1/16。可以认为 feature map 中一个点对应输入图片的 16 个像素。由于相邻的同尺寸、同比例的 anchor 是在 feature map 上的距离是一个点,对应到输入图片中就是 16 个像素。在一定程度上可以认为 anchor 的精度为 16 个像素。不过还需要考虑原图相比于输入图片又做过缩放(这也是 dataset 返回的scale参数的作用,这个的scale指的是原图和输入图片的缩放尺度,和上面的 scale 不一样)。
4 实现方案
其实上半年好几次都要用到 Faster R-CNN,但是每回看到各种上万行,几万行代码,简直无从下手。而且直到 罗若天大神(http://t.cn/RQzgAxb )的 ruotianluo/pytorch-faster-rcnn(http://t.cn/RQzgGEo )之前,PyTorch 的 Faster R-CNN 并未有合格的实现(速度和精度)。最早 PyTorch 实现的 Faster R-CNN 有 longcw/faster_rcnn_pytorch(http://t.cn/RJzfpuS )和 fmassa/fast_rcn(http://t.cn/RQzgJFy ) 后者是当之无愧的最简实现(1,245 行代码,包括空行注释,纯 Python 实现),然而速度太慢,效果较差,fmassa 最后也放弃了这个项目。前者又太过复杂,mAP 也比论文中差一点(0.661VS 0.699)。当前 github 上的大多数实现都是基于py-faster-rcnn,RBG 大神的代码很健壮,考虑的很全面,支持很丰富,基本上 git clone 下来,准备一下数据模型就能直接跑起来。然而对我来说太过复杂,我的脑细胞比较少,上百个文件,动不动就好几层的嵌套封装,很容易令人头大。
趁着最近时间充裕了一些,我决定从头撸一个,刚开始写没多久,就发现 chainercv(http://t.cn/RN2kZoJ ) 内置了 Faster R-CNN 的实现,而且 Faster R-CNN 中用到的许多函数(比如对 bbox 的各种操作计算),chainercv 都提供了内置支持 (其实 py-faster-rcnn 也有封装好的函数,但是 chainercv 的文档写的太详细了!)。所以大多数函数都是直接 copy&paste,把 chainer 的代码改成 pytorch/numpy,增加了一些可视化代码等。不过 cupy 的内容并没有改成 THTensor。因为 cupy 现在已经是一个独立的包,感觉比 cffi 好用(虽然我并不会 C....)。
总结
最终写了一个简单版本的 Faster R-CNN,代码地址在 github:simple-faster-rcnn-pytorch(http://t.cn/RHCDoPv )
这个实现主要有以下几个特点:
代码简单:除去空行,注释,说明等,大概有 2000 行左右代码,如果想学习如何实现 Faster R-CNN,这是个不错的参考。
效果够好:超过论文中的指标(论文 mAP 是 69.9, 本程序利用 caffe 版本 VGG16 最低能达到 0.70,最高能达到 0.712,预训练的模型在 github 中提供链接可以下载)
速度足够快:TITAN Xp 上最快只要 3 小时左右(关闭验证与可视化)就能完成训练
显存占用较小:3G 左右的显存占用
^_^
这个项目其实写代码没花太多时间,大多数时间花在调试上。有报错的 bug 都很容易解决,最怕的是逻辑 bug,只能一句句检查,或者在 ipdb 中一步一步的执行,看输出是否和预期一样,还不一定找得出来。不过通过一步步执行,感觉对 Faster R-CNN 的细节理解也更深了。
写完这个代码,也算是基本掌握了 Faster R-CNN。在写代码中踩了许多坑,也学到了很多,其中几个收获 / 教训是:
在复现别人的代码的时候,不要自作聪明做什么 “改进”,先严格的按照论文或者官方代码实现(比如把 SGD 优化器换成 Adam,基本训不动,后来调了一下发现要把学习率降 10 倍,但是效果依旧远不如 SGD)。
不要偷懒,尽可能的 “Match Everything”。由于 torchvision 中有预训练好的 VGG16,而 caffe 预训练 VGG 要求输入图片像素在 0-255 之间(torchvision 是 0-1),BGR 格式的,标准化只减均值,不除以标准差,看起来有点别扭(总之就是要多写几十行代码 + 专门下载模型)。然后我就用 torchvision 的预训练模型初始化,最后用了一大堆的 trick,各种手动调参,才把 mAP 调到 0.7(正常跑,不调参的话大概在 0.692 附近)。某天晚上抱着试试的心态,睡前把 VGG 的模型改成 caffe 的,第二天早上起来一看轻轻松松 0.705 ...
有个小 trick:把别人用其它框架训练好的模型权重转换成自己框架的,然后计算在验证集的分数,如果分数相差无几,那么说明,相关的代码没有 bug,就不用花太多时间检查这部分代码了。
认真。那几天常常一连几个小时盯着屏幕,眼睛疼,很多单词敲错了没发现,有些报错了很容易发现,但是有些就。。。 比如计算分数的代码就写错了一个单词。然后我自己看模型的泛化效果不错,但就是分数特别低,我还把模型训练部分的代码又过了好几遍。。。
纸上得来终觉浅, 绝知此事要 coding。
当初要是再仔细读一读 最近一点微小的工作(http://t.cn/RQzgn7p )和 ruotianluo/pytorch-faster-rcnn(http://t.cn/RQzgGEo )的 readme,能少踩不少坑。
P.S. 在 github 上搜索 faster rcnn,感觉有一半以上都是华人写的。
最后,求 Star github: simple-faster-rcnn-pytorch(http://t.cn/RHCDoPv )