python学习:机器学习下的pybrain和多线程编程
最近实习需要用到这几个库,主要是用pybrain里的神经网络来做预测模型,而多线程编程的知识是我自己想学的,对于IO密集型的数据处理和保存来说,多线程的使用是必须的,所以我就把这两者加入了学习计划。先占个坑,慢慢更新
我去。。还没写这个就变成我博客涨访问最快的了。。心理难安啊,本来打算慢慢来的,看来要速度点了,明天(3.13)前就把pybrain的写好!
pybrain的神经网络看的差不多了,总结如下!
一 pybrain
关于pybrain的安装,会git的兄弟们只要使用如下命令:
git clone git://github.com/pybrain/pybrain.git
python setup.py install就可以安装pybrain了,什么,你不会用git!?那你可以进入上面那个网站,直接下载zip格式再解压文件。
然后pybrain本身有一些关联的包需要下载如:numpy,scipy,我的建议是下载anaconda,这个IDE是专门用来给python做数据分析的,里面把各种关联的库都帮你绑定好了,连scikit-learn都有,我之前自己关联各种库的时候老是会出错,所以建议大家就用这个了,省心省力啊。安装好后可以输入import pybrain验证一下是否成功了。接下来讲pybrain的使用。
anaconda下载地址:
https://www.continuum.io/downloads
pybrain内部集成了一些分类器,有BP神经网络、循环神经网络RNN,还有增强学习RL的东西,这里只介绍下怎么使用BP神经网络,其他的大家要是感兴趣可以去看官方文档:
http://www.pybrain.org/docs/
1、导入包
#如下,首先import一些需要的包:
from pybrain.tools.shortcuts import buildNetwork
from pybrain.datasets import SupervisedDataSet
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure import TanhLayer,LinearLayer,SigmoidLayer,SoftmaxLayer
from pybrain.tools.validation import CrossValidator,Validator
import numpy as np
import pandas as pd
2、创建数据X和Y
x1=[float(x) for x in range(-100,400)] #换成float型是为了后期可以标准化为0-1
x2=[float(x) for x in range(-200,800,2)]
x3=[float(x) for x in range(-500,1000,3)]
num=len(x1)
y=[]
for i in range(num):
y.append(x1[i]**2+x2[i]**2+x3[i]**2)x1=[(x-min(x1))/(max(x1)-min(x1)) for x in x1]
x2=[(x-min(x2))/(max(x2)-min(x2)) for x in x2]
x3=[(x-min(x3))/(max(x3)-min(x3)) for x in x3]
y=[(x-min(y))/(max(y)-min(y)) for x in y]#将X和Y转化为array格式
x=np.array([x1,x2,x3]).T
y=np.array(y)
xdim=x.shape[1] #确定输入特征维度
ydim=1 #确定输出的维度
此时x和y的格式如下:
X:500行3列
array([[ 0. , 0. , 0. ],
[ 0.00200401, 0.00200401, 0.00200401],
[ 0.00400802, 0.00400802, 0.00400802],
...,
[ 0.99599198, 0.99599198, 0.99599198],
[ 0.99799599, 0.99799599, 0.99799599],
[ 1. , 1. , 1. ]])
Y:500行1列
array([ 1.60899642e-01, 1.58654929e-01, 1.56425984e-01,
1.54212807e-01, 1.52015399e-01, 1.49833758e-01,
1.47667886e-01, 1.45517782e-01, 1.43383446e-01,
...,
1.35003784e-01, 1.32948289e-01, 1.30908563e-01])
4、创建神经网络使用的监督数据集
DS=SupervisedDataSet(xdim,ydim)
for i in range(num):
DS.addSample(x[i],y[i])
train,test=DS.splitWithProportion(0.75) #将数据拆分,0.75为训练数据,0.25为测试数据
#DS['input'] #输入x的值
#DS['target'] #输出y的值
#DS.clear() #清除数据
5、创建神经网络
#如下,我这次总共创建了4层的神经网络,一层输入,2个隐含层,分别是10个节点和5个节点,一层输出,多少层可以根据自己需求来确定
#隐含层使用的是tanh函数,输出则使用的是y=x线性输出函数
ann=buildNetwork(xdim,10,5,ydim,hiddenclass=TanhLayer,outclass=LinearLayer)
#BP算法训练,参数为学习率和动量
trainer=BackpropTrainer(ann,dataset=train,learningrate=0.1,momentum=0.1,verbose=True)
#trainer.trainEpochs(epochs=20) #epochs表示迭代的次数
trainer.trainUntilConvergence(maxEpochs=50) #以上这两种训练方法都可以,看自己喜欢
6、预测与作图
#预测test情况
output=ann.activateOnDataset(test)
#ann.activate(onedata)可以只对一个数据进行预测
#稍微整理下output输出,为了后期作图
out=[]
for i in output:
out.append(i[0])
#使用pandas作图
df=pd.DataFrame(out,columns=['predict'])
df['real']=test['target']
df1=df.sort_values(by='real')
df1.index=range(df.shape[0])
df.plot(kind='line')
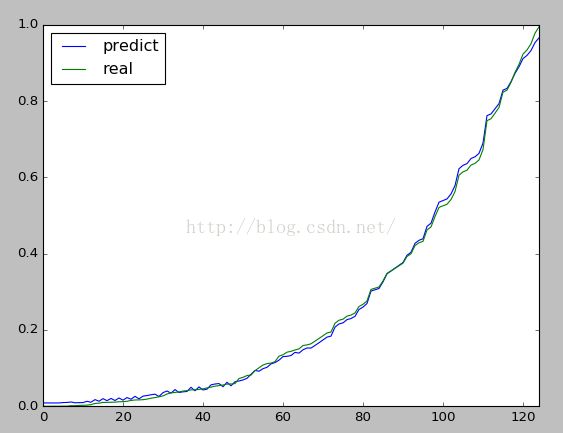
其中横坐标仅表示第几个数,纵坐标表示标准化后的y
若对整个五百组数据拟合的话,情况如下:
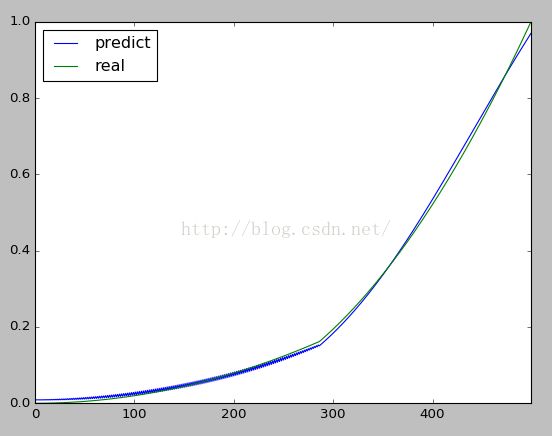
只需将代码中的test都改成DS即可。
到了这里操作基本差不多了,其他模块还有一些附加功能,如:
#Validator可以进行一些误差的计算
v=Validator()
v.MSE(output,test['target']) #计算test的原始值和预测值的均方差和,两者格式必须相等#使用交叉验证
CrossValidator(trainer, DS, n_folds=5,max_epochs=20)然后以上的神经网络训练针对的是连续型输出的,当要使用分类的神经网络时,最好设置下神经网络中代表分类的变量,具体可以查阅pybrain的doc
最后总结下这几天学习操作和查的资料对神经网络做个总结。
首先,神经网络这玩意的激活函数的范围基本都在0-1或者-1-1,所以数据必须标准化,不然如下:
sigmoid函数
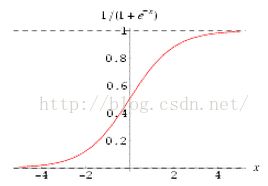
可以看到,当X>4之后,得到的转化值基本都是1了,这样后期拟合将无法收敛。然后关于隐藏节点和输出节点的激活函数选择,一般是这样的,如果是连续型的输出,我们一般使用输出函数为y=x的线性输出函数,如果是分类的神经网络,二元分类的时候我们使用sigmoid,多元分类的时候则采用softmax。softmax具有将一个较大的值转化为1,其他值转化为0的功能,相当于一个max函数,在多元分类中非常有用,而sigmoid多使用与二元分类,能将数据转化到0-1,通过设置阈值来判断取0还是1。然后关于为什么我选择了tanh作为隐藏节点的激活函数,因为《神经网络43个案例分析》书里提到对各个激活函数的匹配情况作了分析,发现tanh和y=x配套的时候拟合误差是最低的,所以我这里使用了这两函数。如下:
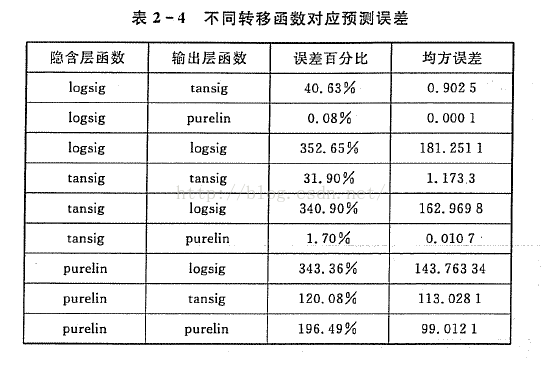
purelin就是y=x.
然后关于参数的设置:
momentun冲量:为了越过局部最小值
learningrate学习率:为了加快学习速度
weightdecay:给损失函数加个惩罚,惩罚过大的权值数,让他能够选取权值和最小的NN,目的是为了防止过拟合,一般为0.1左右
PS:weightdecay设置的不好,可能使得本身可以收敛的网络变得无法收敛,所以要嘛不设,要嘛多尝试几个