Spark之训练分类模型练习(2)
上接博文。
1 改进模型及参数调优
1.1 数值特征标准化
使用RowMatrix类计算列的统计量。每一行为某一样本的特征向量
import org.apache.spark.mllib.linalg.distributed.RowMatrix
val vectors = data.map(lp => lp.features)
val matrix = new RowMatrix(vectors)
val matrixSummary = matrix.computeColumnSummaryStatistics()
//每一列的常用统计量
println(matrixSummary.mean) //均值
println(matrixSummary.min) //最小值
println(matrixSummary.max) //最大值
println(matrixSummary.variance)//方差
println(matrixSummary.numNonzeros)//非零的个数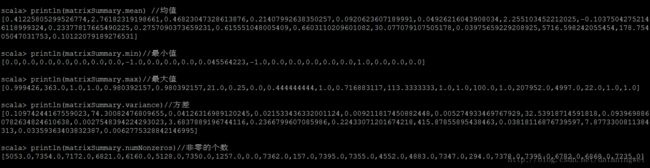
使用去均值归一化方法:
(x−μ)/sqrt(variance)
//对数据进行标准化预处理,选择性的去均值操作,和标准方差操作
import org.apache.spark.mllib.feature.StandardScaler
val scaler = new StandardScaler(withMean = true, withStd = true).fit(vectors)
val scaledData = data.map(lp => LabeledPoint(lp.label,
scaler.transform(lp.features)))
// 验证逻辑回归算法性能改善情况。NB和DT算法不受数据归一化的影响
val lrModelScaled = LogisticRegressionWithSGD.train(scaledData, numIterations)
val lrTotalCorrectScaled = scaledData.map { point =>
if (lrModelScaled.predict(point.features) == point.label) 1 else 0
}.sum
val lrAccuracyScaled = lrTotalCorrectScaled / numData
val lrPredictionsVsTrue = scaledData.map { point =>
(lrModelScaled.predict(point.features), point.label)
}
val lrMetricsScaled = new BinaryClassificationMetrics(lrPredictionsVsTrue)
val lrPr = lrMetricsScaled.areaUnderPR
val lrRoc = lrMetricsScaled.areaUnderROC
println(f"${lrModelScaled.getClass.getSimpleName}\nAccuracy:${lrAccuracyScaled * 100}%2.4f%%\nArea under PR: ${lrPr *
100.0}%2.4f%%\nArea under ROC: ${lrRoc * 100.0}%2.4f%%")***LogisticRegressionModel
Accuracy:62.0419%
Area under PR: 72.7254%
Area under ROC: 61.9663%*
1.2 其他特征(增加类别特征向量)
//加入类别特征
val categories = records.map(r => r(3)).distinct.collect.zipWithIndex.toMap
val numCategories = categories.size
println(categories)
val dataCategories = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val categoryIdx = categories(r(3)) //增加类别向量列表
val categoryFeatures = Array.ofDim[Double](numCategories)
categoryFeatures(categoryIdx) = 1.0
val otherFeatures = trimmed.slice(4, r.size - 1).map(d => if
(d == "?") 0.0 else d.toDouble)
val features = categoryFeatures ++ otherFeatures
LabeledPoint(label, Vectors.dense(features))
}
println(dataCategories.first)
// 标准化输出
val scalerCats = new StandardScaler(withMean = true, withStd = true).
fit(dataCategories.map(lp => lp.features))
val scaledDataCats = dataCategories.map(lp =>
LabeledPoint(lp.label, scalerCats.transform(lp.features)))
// 再次查看lr算法性能
val lrModelScaledCats = LogisticRegressionWithSGD.train(scaledDataCats,
numIterations)
val lrTotalCorrectScaledCats = scaledDataCats.map { point =>
if (lrModelScaledCats.predict(point.features) == point.label) 1 else 0
}.sum
val lrAccuracyScaledCats = lrTotalCorrectScaledCats / numData
val lrPredictionsVsTrueCats = scaledDataCats.map { point =>
(lrModelScaledCats.predict(point.features), point.label)
}
val lrMetricsScaledCats = new BinaryClassificationMetrics(lrPredictionsVsTrueCats)
val lrPrCats = lrMetricsScaledCats.areaUnderPR
val lrRocCats = lrMetricsScaledCats.areaUnderROC
println(f"${lrModelScaledCats.getClass.getSimpleName}\nAccuracy:${lrAccuracyScaledCats * 100}%2.4f%%\nArea under PR: ${lrPrCats *
100.0}%2.4f%%\nArea under ROC: ${lrRocCats * 100.0}%2.4f%%")LogisticRegressionModel
Accuracy:66.5720%
Area under PR: 75.7964%
Area under ROC: 66.5483%
1.3 使用更符合模型的特征
朴素贝叶斯更适用于类别特征,仅仅使用类别特征对样本进行分类实验:
// 生成仅有类别属性的特征向量
val dataNB = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val categoryIdx = categories(r(3))
val categoryFeatures = Array.ofDim[Double](numCategories)
categoryFeatures(categoryIdx) = 1.0
LabeledPoint(label, Vectors.dense(categoryFeatures))
}
//验证NB算法的性能
val nbModelCats = NaiveBayes.train(dataNB)
val nbTotalCorrectCats = dataNB.map { point =>
if (nbModelCats.predict(point.features) == point.label) 1 else 0
}.sum
val nbAccuracyCats = nbTotalCorrectCats / numData
val nbPredictionsVsTrueCats = dataNB.map { point =>
(nbModelCats.predict(point.features), point.label)
}
val nbMetricsCats = new BinaryClassificationMetrics(nbPredictionsVsTrueCats)
val nbPrCats = nbMetricsCats.areaUnderPR
val nbRocCats = nbMetricsCats.areaUnderROC
println(f"${nbModelCats.getClass.getSimpleName}\nAccuracy:${nbAccuracyCats * 100}%2.4f%%\nArea under PR: ${nbPrCats *
100.0}%2.4f%%\nArea under ROC: ${nbRocCats * 100.0}%2.4f%%")结果:
NaiveBayesModel
Accuracy: 60.9601%
Area under PR: 74.0522%
Area under ROC: 60.5138%
从结果看,NB算法有了很大提升,说明数据特征对模型的适应性。
1.4 模型的参数调优
已讨论的对模型性能影响因素:特征提取、特征的选择、数据格式和对数据分布的假设
接下来,讨论模型参数对性能的影响。