Python中iteration(迭代)、iterator(迭代器)、generator(生成器)等相关概念的理解
在阅读Python tutorial类这一章的时候出现了iterator的概念,我是一个是编程的半吊子,虽然在其它语言(比如Java和C++)中也听过这个概念,但是一直没认真的去理解,这次我参考了一些文章,总结了一些我的看法。
首先,我在理解相关的概念的时候总是试图探索引入相关概念的背后的真正意图,我们看到的多半都是用法,那么为什么要这么用,也许搞清楚了每件事情背后的目的,接下来产生的解决方案才能顺理成章水到渠成。那么这篇文章大多数是我通过现有的一些线索,推测出背后的一些可能的,也许我的理解充满各种主观因素,但是至少能够自圆其说,也请各位能不吝赐教。其次,其中有些表述可能会有些啰嗦。
1. “迭代”这个概念引入主要是解决什么问题的
首先你要知道什么叫做迭代
迭代就是单向地、逐个地访问某个容器中的元素的行为。 (可以理解为线性的方式访问容器中元素,单向、逐个是其特征)
在程序实现中我们最常进行的一种操作就是将容器(以下认为“数据结构”和“容器”是同义词)里元素一个接一个的取出来,但是为了实现这个简单的目的,针对不同的数据结构,我每次写的代码还都不一样(这背后其实是要了解每个数据结构的特性,并根据这些特性构造合适的代码),太麻烦了,于是我们想能不能这样?能不能写一个工具,每次我们需要在某个数据结构上进行迭代操作的时候,就调用这个工具,这个工具可以我们把不同数据结构在方法实现细节上的不同屏蔽掉,这个工具就是迭代器,在python中是由类实现的。
迭代器是是一个抽象的概念,它代表了一种目的,而并非细节。所有实现了在某个特定数据结构上进行迭代行为的类都是迭代器。
延展概念
迭代是遍历的一种特例,遍历(traverse)是可以在数据结构上来回的游走,不仅可以往前,还可以往后,同时还能保证不重不漏的,也就是把非线性的东西映射成线性的访问方式,而且还是不重不漏的,迭代是单向的而且只来一次。
2. 在这个程序语言中,这个概念是如何实现的
我们来看看这个东西在语言设计的层面是如何实现的:
我们假设,在理想的情况下,如果有一个模块或者一个函数里面实现了所有数据类型的迭代方式,假设这个模块叫iterator,里面有一个方法叫做iteration,那么每次我用的时候,先import iterator,然后用iterator.iteration(带迭代的变量)实现了一次迭代,这是比较理想的方式,但是现实中很难做到这点,除了系统内置的数据结构之外,用户自己实现的数据结构咋办,于是放弃这种大一统的思路,而把所有的实现都下放给用户自己实现。在这种情况下,为了保证每个用户写的迭代器能够被其它用户使用,需要制定一些规范让大家遵守,我斗胆把这个规范称之为“迭代规范”吧,这个规范可以分成两个层面来理解,一个是使用层面,一个是实现层面。
首先我们来看使用层面,在python中迭代器的使用是这么一个套路:
- 第一步,由待迭代的容器变量创建一个对应的迭代器。
在python中,有一个内置的函数iter(),这个函数以待迭代的容器变量为参数,创建出对应于这种容器的迭代器。 - 第二步,调用迭代器的next方法,每一次调用next方法只会得到一个元素。
在python中,迭代器里面有一个next()方法,我们可以直接调用这个方法,但是常用的方法是利用python的内置函数next(),这个函数以迭代器为参数,相当于调用了迭代器的next()方法,简单一点。
- 第一步,由待迭代的容器变量创建一个对应的迭代器。
然后是实现层面,也分成两步:
- 第一步,我称之为“数据的可迭代声明”(或者叫做“可迭代实现”)
你必须要证明你的数据结构是可迭代(iteratable)的,从观念上或者数学上看你的数据结构里的数据必须是有限可列或者至少是可列的(可列的概念其实是有理数或者无理数中用到的概念)。只有数据结构可迭代,才有为这个数据结构构造迭代器的意义。在具体的实现层面,一个可迭代的数据结构要满足下面的要求(这个数据结构一般来说是一个类),必须实现iter方法,这个方法需要返回一个迭代器。 - 第二步,叫做“迭代器的实现”
实现iterator需要实现两个方法,这两个方法一起被称之为迭代器协议(iterator protocol)。
- 第一个方法是iter,这个方法返回的是实现迭代器的这个类自身,你会奇怪,实现了iter方法的不是说明这个类是可迭代的吗?是的,迭代器一般来说也是可迭代的。
- 第二个方法是next方法,这个方法返回的是容器中的下个元素,如果没有更多的元素了,则会raise一个StopIteration异常。
- 第一步,我称之为“数据的可迭代声明”(或者叫做“可迭代实现”)
迭代器协议的要点和难点在next方法的实现上(这为生成器的引入埋下了伏笔),而在next方法的实现有三个要点,其中最难的一点在于理解“数据现用现生成”或者说“用到某个元素的时候才把它生成(计算)出来”的思想。
这里就要引入另一个问题了,我斗胆把它称之为“数据的准备问题”。
啥意思呢?比方说在程序中,在用一个数据之前我们首先得“有”一个数据,那么我们如何“有”一个数据?
两种方法,一种方式是我把所有可能要用到元素都生成出来并且全部保存在内存中然后再在使用的过程中去拿我要用的元素;还有一种是我用某个元素的前一刻时才去生成元素,然后再去用。你会觉得,我靠这还算一个问题么,必须后一种啊,前一种明显是在浪费空间么(参考firstn的例子)。很不幸的时候,在python2有很多底层的数据实现就是没有效率,你单看他们的时候都没有问题,但是一旦代码的规模变大,层层调用之后就不好说了。好,我们统一观点之后,再讨论下一个问题。
在使用数据的前一刻把数据生成可能吗?
其实是可能的,这也分两种可能,一种可能是我们要自己“凭空创造”数据,其实说“凭空创造”其实不准确,因为本质上任何可列的数据都是自然数的函数(这个函数是数学意义上的函数),只要有函数(映射法则)以及自变量,求出因变量不是很简单的事情吗?还有一种可能就是数据原来就存在了(比如说存在数据库里或者文件里),我们只需要取出来就可以,那么在这种情况下我们只要获取保存数据的位置信息就能获取到实际的数据值了,其实也可以理解为建立自然数和位置信息的映射。理解了这点,另外两个实现细节就好说了,比如我们经常会用(不是绝对)一个游标来记录位置信息,可能这个游标是一个计数器,然后我们利用循环的方式让其自增从而实现迭代特性中的“单向”,“逐个”特征。再有就是最后一定要返回StopIteration。小结一下next方法的要点就是:
1. 数据现用现生成
2. 单向,逐个特性的实现
3. 最后返回StopIteration
在语法上,返回StopIteration比其它两点都重要,next方法啥也不做,直接返回StopIteration都行。例如下面这个例子
>>> class Simplest_Iterator(object):
... def next(self): # Python 2 compatibility
... return self.__next__()
... def __next__(self):
... raise StopIteration
...
>>> z = Simplest_Iterator()
>>> next(z)
Traceback (most recent call last):
File "" , line 1, in
File "" , line 5, in __next__
StopIteration 值得注意的是,依据在“数据的可迭代声明”这一步中iter方法返回的容器对象是自身还是其它对象的不同,迭代器在使用上会表现出不同的特性。
1. iter方法返回的是容器对象本身。这种实现方式叫做“容器本身既是迭代器”,这种情况迭代器构造出来之后只能使用一次。
2. iter方法返回的是其他的对象。这种实现方式叫做“数据和迭代器的分离”,其实这个更像是工具的思想,我第一次阅读与迭代器实现相关的文档时脑海里首先想到是这种方法。
那么这两种方式有什么区别呢?在Python中,大多数容器类型(哪些属于容器类型,参考这篇文章)都是采用第二种方式实现的,都是采用“数据和迭代器分离”的实现的方式的,这是因为“可迭代”其实从观念上意味着,我在这个种容器上反复进行迭代的,如果“容器本身即是迭代器”的话,每次容器每次调用iter方法返回的是自身,在经过一次迭代之后,游标指到容器最后一个元素后面,同时抛出了异常,迭代器就再也无法工作了,除非你利用一些方法把next方法中的游标置为初始状态。而我们采用数据和迭代器分离的方式话,每次容器调用iter方法的时候,都会重新生成一个新的迭代器对象,这样就可以无限次的在容器上进行迭代了。

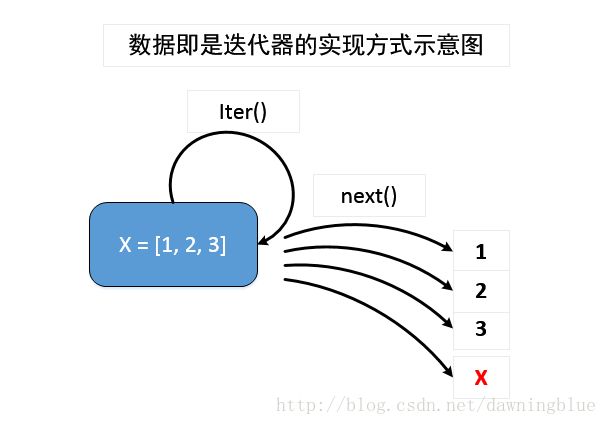
下面用例子来说明,我们实现一个与内置函数xrange的类似的类
实现方式1:“容器本身即是迭代器”
class yrange:
def __init__(self, n):
self.i = 0
self.n = n
def __iter__(self):
return self
def __next__(self):
if self.i < self.n:
i = self.i
self.i += 1
return i
else:
raise StopIteration()之后我们来做一下测试:
>>> y = yrange(3)
>>> y.next()
0
>>> y.next()
1
>>> y.next()
2
>>> y.next()
Traceback (most recent call last):
File "" , line 1, in <module>
File "" , line 14, in next
StopIteration实现方式2. 数据和迭代器的分离的例子:
class zrange:
def __init__(self, n):
self.n = n
def __iter__(self):
return zrange_iter(self.n)
class zrange_iter:
def __init__(self, n):
self.i = 0
self.n = n
def __iter__(self):
# Iterators are iterables too.
# Adding this functions to make them so.
return self
def __next__(self):
if self.i < self.n:
i = self.i
self.i += 1
return i
else:
raise StopIteration()然后我们比较一下两个类的不同
>>> y = yrange(5)
>>> list(y)
[0, 1, 2, 3, 4]
>>> list(y)
[]
>>> z = zrange(5)
>>> list(z)
[0, 1, 2, 3, 4]
>>> list(z)
[0, 1, 2, 3, 4]3. 这些概念有什么用?
毫无疑问第一个应用就是做遍历
学过数据结构的都知道所有操作的基础都是基于遍历,如果解决了遍历的问题,就等于说解决了一大半的问题
甚至文件都可以进行迭代哦可以用来生成数据(我估计生成器的名字就是这样来的吧)
在迭代器实现的核心思想就是“数据用到的时候才生成”,那么我们是不是可以用这个方式来生成数据?而且这种实现方式意外的节省空间?这点正好引入下一个要讨论的知识点,也就是生成器
最有说服力的是那个斐波那契数列的例子
4. 生成器
简单来说,生成器就是迭代器实现的简化。相比用一个实现迭代器协议的类来实现迭代器而言,我们只要定义一个函数就可以实现迭代器,这个函数就是生成器。
那么这个函数如何定义呢?我们以yrange迭代器为例,生成器实现如下:
def yrange(n):
i = 0
while i < n:
yield i
i += 1怎么理解这个代码,有很多人说这个东西简单,但是我不这么觉得,其实越是看似简单的东西里面越是有深刻的知识在里面。就像我在next方法实现那部分中对“在使用数据的前一刻把数据生成可能吗?”这个问题进行的讨论一样,对于数据的生成,除了在已经存储数据的地方进行获取以外,还有一种方式是“把它计算出来”,而计算的方法,本质上是建立一个从自然数序列到我们所要的序列的一个映射。对于后一种方式来说,我们要做的事情就是,遍历自然数序列,对于每个自然数,把它作为映射法则的因变量放入到映射法则中去进行运算,把运算出来的结果返回出去。比如映射关系是f(x),那么这个代码可以这么写:
def generatorexample(n):
i = 0
while i < n:
yield f(i)
i += 1也就说把计算的结果(在程序中就是一个表达式)返回出去的那步用yield关键字来返回就行了。
那么这个背后实现机制是怎么样的,
1. 当generator function被调用的时候,这个函数会返回一个generator对象之后什么都不做。
2. 当next方法被调用的时候,函数就会开始执行直到yield所在的位置,计算出来的值在这个位置被返回,之后这个函数就停下了。之后再调用next方法的时候,函数继续执行,直到遇到下一个yield。
3. 如果执行完的代码,还没有遇到yield,就会抛出StopIteration异常。
>>> def foo():
... print "begin"
... for i in range(3):
... print "before yield", i
... yield i
... print "after yield", i
... print "end"
...
>>> f = foo()
>>> f.next()
begin
before yield 0
0
>>> f.next()
after yield 0
before yield 1
1
>>> f.next()
after yield 1
before yield 2
2
>>> f.next()
after yield 2
end
Traceback (most recent call last):
File "" , line 1, in
StopIteration
>>> 再比如:
def my_generator():
print("return first value")
yield 1
print("return second value")
yield 2
print("return last value")
yield 3
print("raise StopIteration")
z = my_generator()
next(z)
next(z)
next(z)
next(z)这里面有一些地方一下说明一下,其实如果深究起“generator”来,其实这还是一个非常模糊的词呢,generator到底是说那个函数呢?还是说这个函数返回的值呢?
在官方的glossary里面,generator就指得是那个包含yield语句的函数体,也就是“generator function”,而这个如果要指代这个函数返回的对象,一般称之为“generator iterator”,官方建议为了避免歧义,最好把词说全一点。
而我还是喜欢这篇文章的描述,“generator function ”就是那个函数体,“generator”表示“generator function”这个函数返回的对象。
5. 生成器表达式
生成器表达式可以看成迭代器在生成器的基础上进一步简化(还能在懒一点吗),用好理解的话说就是——生成器表达式可以看成列表推导式的生成器版。列表推导是可以看我的另一篇文章
虽所简化了形式,但是我感觉更接近迭代器的本质了——也就是“构造一个和自然数序列一一对应的序列”
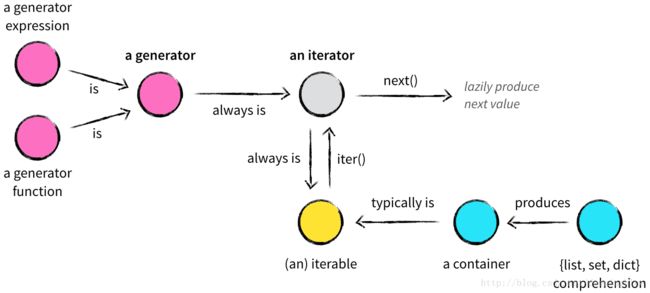
6. 总结一下这几个概念的关系
借用一张图
7.迭代思想在Python中的广泛存在
在tutorial里面有这么一句话The use of iterators pervades and unifies Python.
基本上来说迭代的思想在Python这门语言的实现过程中已经渗透在各个角落,已经是底层的设计思想了,很多语法都是基于迭代这个概念向上建造的。以下是一些例子
很多容器类型都是iterable
甚至文件类型都是可以用for语句来访问的。我们最常用的一个数据结构list,它是用iterable作为参数来初始化一个list,其实执行了这样的初始化函数class list(object): ... def __init__(self, iterable): for i in iterable: self.value.append(i) ...很多函数的参数以及返回值都是iterable
map(), filter() ,zip() ,range()
dict.keys(), dict.items() 和 dict.values()for其实也是语法糖
基于迭代的语法糖
比如:for i in iterable: func(i)本质上是:
z = iter(iterable) try: while True: func(next(z)) except StopIteration: passunpack也是语法糖
比如:>>> a,b = b,a # 等价于 a,b = (b,a) >>> a,b,*_ = [1,2.3,4] # 仅适用于 Python 3 >>> a,b,*_ = iter([1,2.3,4]) # 也可以用于迭代器 >>> a 1 >>> b 2.3 >>> _ [4]其实是赋值是这么实现的:
k = iter(iterable) a = next(k) b = next(k) _ = list(k)list comperhension也是语法糖
上面虽然说generator experssion是生成器版本的list comperhension,这只是为了便于理解,其实先后顺序应该颠倒过来。
List Comprehension 也只是语法糖而已,甚至还可以写出 tuple/set/dict comprehension(其实 set 就是所有 key 的 value 都为 None 的 dict)>>> [x*x for x in range(10)] [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> list(x*x for x in range(10)) [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> tuple(x*x for x in range(10)) (0, 1, 4, 9, 16, 25, 36, 49, 64, 81) >>> set(x*x for x in range(10)) {0, 1, 64, 4, 36, 9, 16, 49, 81, 25} >>> dict((x,x*x) for x in range(10)) {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
参考文献
- Python Practice Book 我的不少例子都引自这个
- 官网wiki对于iterator的解释 官方的迭代器的解释 Q&A 不错 说明了iter方法和next方法的不一定非要是一个 链接里的IBM链接失效了,但是搜索一下就行了
- 官网wiki对于generator的解释 节省空间的例子不错
- 官方文档对于iterator protocol的解释
- Python 笔记(3):可迭代变量 后面的好多语法糖的例子都来自这篇文章,感谢这位作者,PS:你的博客里的那个背景音也是我喜欢的,很想和你交个朋友呢,可是你没写联系方式
- python迭代器与生成器小结 这篇文章值得一看
- Iterables vs. Iterators vs. Generators 引用率也很高的文章,我引用了其中一张图片,根据我的理解修改了一些图片
- Python yield 使用浅析斐波那契数列的例子 仔细看了一下这个居然是廖雪峰写的