Python爬取携程最新车票(附导出EXCEL)
这里使用的不是最优最快方式,没有选择爬取Api,而选择了使用爬取html分析dom的方式(略麻烦)以娱乐学习为主
首先,我们先找到要爬取的网站 ,第一个第二个参数是中文出发地和目的地,day是yyyy-MM-dd格式日期,最后两个参数是URL编码的第一个和第二个参数,使用urllib进行编码
https://trains.ctrip.com/TrainBooking/Search.aspx?from={}&to={}&day={}&number=&fromCn={}&toCn={}
这里尝试使用普通的get方式是没有办法获取到完整的网页内容,我这里利用splinter集成的Selenium进行完整html的获取(看到这用过的人就知道为什么说麻烦了,需要手动安装谷歌浏览器驱动,和配置浏览器环境变量)页面的数据是这样一行一行的:
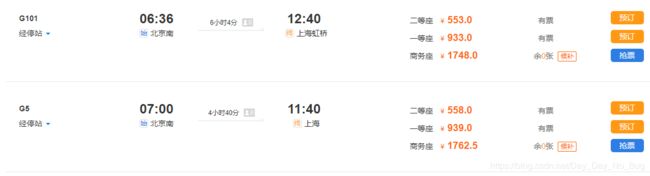
然后就是分析dom结构,我这里使用BeautifulSoup进行分析内容,xlwt作为excel导出,整体就这些功能,下面是导出的效果
![]()

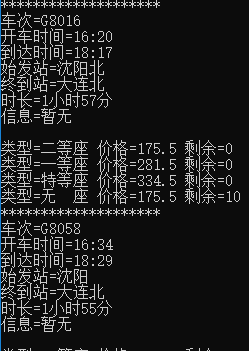
控制台输出:
最后贴上全部完整代码(不要谢我以学习为主):
import time
import urllib.parse
import xlwt
import sys
from bs4 import BeautifulSoup
from splinter import Browser
URL = "https://trains.ctrip.com/TrainBooking/Search.aspx?from={}&to={}&day={}&number=&fromCn={}&toCn={}"
def checkNull(str):
if len(str) == 0 :
return False
elif str.isspace():
return False
else:
return True
def autoBrowser(start,end,date=time.strftime('%Y/%m/%d',time.localtime(time.time()))):
if checkNull(start) and checkNull(end):
with Browser('chrome') as bs:
fromCn = urllib.parse.quote(start.encode('gb2312'))
toCn = urllib.parse.quote(end.encode('gb2312'))
bs.visit(URL.format(start,end,date,fromCn,toCn))
workbook = xlwt.Workbook()
sheet = workbook.add_sheet('车程')
title = ['车次信息', '发车时间', '到达时间', '始发站', '终到站', '时长', '信息',
'A类型', 'A价格', 'A剩余', 'B类型', 'B价格', 'B剩余', 'C类型', 'C价格', 'C剩余']
for i in range(0, len(title)):
sheet.write(0, i, title[i])
bfs = BeautifulSoup(bs.html,'html.parser')
list = bfs.find(id='searchlsit')
for ii,content in enumerate(list):
contents = []
number = content.select('.w1 strong')[0].get_text().strip()
startTime = content.select('.w2 strong')[0].get_text().strip()
startHome = content.select('.w2 span')[0].get_text().strip()
endTime = content.select('.w3 strong')[0].get_text().strip()
endHome = content.select('.w3 span')[0].get_text().strip()
longTime = content.select('.haoshi')[0].get_text().strip()
info = '暂无'
if(len(content.select('p')) >0 ):
info = content.select('p')[0].get_text().strip()
lists = content.select('.w5 div')
print(f'车次={number} \n'
f'开车时间={startTime} \n'
f'到达时间={endTime} \n'
f'始发站={startHome} \n'
f'终到站={endHome} \n'
f'时长={longTime} \n'
f'信息={info} \n'
)
contents.append(number)
contents.append(startTime)
contents.append(endTime)
contents.append(startHome)
contents.append(endHome)
contents.append(longTime)
contents.append(info)
types = []
for price in lists:
if len(price.select('span')) > 0 and len(price.select('b')) > 0 and len(price.select('em')) > 0:
teyp = price.select('span')[0].get_text().strip()
jiage = price.select('b')[0].get_text().strip()
last = price.select('em')[0].get_text()
print(f'类型={teyp} 价格={jiage} 剩余={last}')
types.append(teyp)
types.append(jiage)
types.append(last)
for type in types:
contents.append(type)
print('*' * 20)
for i in range(0, len(contents)):
sheet.write(ii+1, i, contents[i])
workbook.save('C:\{}-{}-{}.xls'.format(start,end,date))
else:
print("参数格式错误")
if __name__ == '__main__':
if(len(sys.argv) == 4):
#出发地 例:北京
fromCn = sys.argv[1]
#目的地 例:上海
toCn = sys.argv[2]
#时间 例:2019-10-01
date = sys.argv[3]
autoBrowser(fromCn,toCn,date)
else:
print('参数错误')
当然仅仅是复制粘贴,安装包之后并没办法用,所以为了方便我简单写一下配置环境(如果感觉写的不细可以去其他博客了解一下),首先我这里是基于谷歌浏览器的,所以要先有谷歌浏览器并且配置环境变量例如:
![]()
然后,下载和浏览器版本符合的驱动,先去网上找一下和浏览器版本兼容的驱动版本然后去【这里】下载,并且放在浏览器目录下和python目录下