【机器学习】使用Keras开发的流程(IMDB数据集电影评论二分类)
Keras简介
\quad\quad Keras是一个Python深度学习框架,是一个模型级的库,为开发深度学习模型提供了高层次的构建模块,可以方便地定义和训练几乎所有类型的深度学习模型。
Keras具有以下重要特性:
- 相同代码可以在CPU或GPU上无缝切换运行
- 强大的API,便于开发深度学习模型
- 支持卷积神经网络(CNN),循环神经网络(RNN)以及二者的任意组合
- 支持任意网络架构,比如:多输入或多输出模型
- 与所有的Python版本都兼容
- 有三个后端实现:Tensorflow后端、Theano后端和微软认知工具包(CNTK)
一般使用Tensorflow后端作为大部分深度学习任务的默认后端
通过Tensorflow,Keras可以在CPU和GPU上无缝运行
Keras开发
Keras工作流程如下:
- (1)定义训练数据:输入张量和目标张量
- (2)构建网络(或模型),将输入映射到目标
- (3)配置学习过程:选择损失函数、优化器和需要监控的指标
- (4)调用模型的fit方法在训练数据上进行迭代
- (5)使用模型预测
案例
(1)定义训练数据
- IMDB数据集包含来自互联网电影数据库的50000条严重两极分化的英文评论,25000条用于训练,25000条用于测试,训练集和测试集都包含50%的正面评论和50%的负面评论
加载数据集:
from keras.datasets import imdb
# imdb.load_data(path='imdb.npz', num_words=None, skip_top=0, maxlen=None, seed=113, start_char=1, oov_char=2, index_from=3, **kwargs)
# num_words=10000 表示仅保留训练数据中前10000个最常出现的单词,低频的被舍弃
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# 查看数据
# 每条评论为单词索引组成的列表
train_data[0]
# 标签
# 由0或1组成的列表,0表示负面,1表示正面
train_labels[0]
# 将单词索引组成的列表还原为评论
# word_index是将单词映射到整数索引的字典
word_index = imdb.get_word_index()
# 键值颠倒,将整数索引映射到单词
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 解析评论; 请注意,索引减去了3,因为0,1和2是“填充”,“序列开始”和“未知”的保留索引。
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
decoded_review
下载数据很慢,可以到网上找资源,然后放在用户目录下的
.keras目录下
安装Keras后,windows/Linux用户目录下都会生成.keras
数据准备:
- 将整型序列转换为张量
- 因为每个评论数据的整数序列不相同,需要填充列表,使它们具有相同大小,然后再转为张量
- 然后再对其进行one-hot表示
# 将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
# 创建一个形状为(len(sequences), dimension)的0矩阵
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 将results[i]的指定索引设为1
return results
# 训练数据向量化
x_train = vectorize_sequences(train_data)
# 测试数据向量化
x_test = vectorize_sequences(test_data)
# 将标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
- 编码后的数据形式如下:
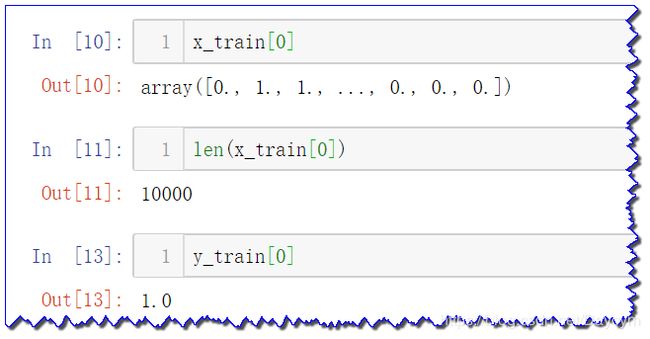
(2)构建网络

- 输入数据是向量,标签数据是标量
# 模型定义
from keras import models
from keras import layers
model = models.Sequential()
# 该层神经元个数16,使用relu作为激活函数
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
# 最后一层使用sigmoid激活,输出0-1范围内的概率,和为1
model.add(layers.Dense(1, activation='sigmoid'))
(3)配置学习过程
# 编译模型
# optimizer:优化器
# loss:损失函数
# metrics:指标(正确率)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
(4)调用模型的fit方法在训练数据上进行迭代
# 划分出测试集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
# 训练模型
history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data=(x_val, y_val))
# 测试结果
results = model.evaluate(x_test, y_test)
print(results)
model.fit()返回一个History对象,包括dict_keys([‘val_loss’, ‘val_acc’, ‘loss’, ‘acc’])可以用来绘图
# 绘制训练损失和验证损失
import matplotlib.pyplot as plt
%matplotlib inline
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" 蓝色圆点
plt.plot(epochs, loss, 'bo', label='Training loss')
# "b" 蓝色实线
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
(5)使用模型预测
model.predict(x_test)
结果

图中我们可以看出,训练损失一直在减小(这正是我们优化的对象),但验证损失先减小,大概在第4epoch后开始增大,说明第4epoch后,模型开始过拟合了
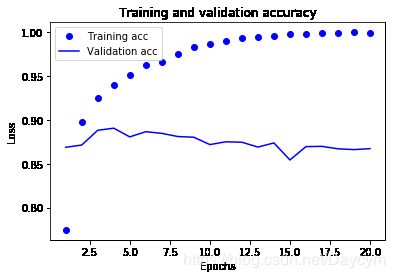
图中可以看出,训练的精度一直在提高(优化的对象),而验证的精度在第4epoch时达到最高
针对上面的过拟合问题的解决办法:
- 减少训练的次数;
- 改变隐藏层的层数或隐藏单元数;
- 使用其他的损失函数或激活函数;
- 改变优化方法等
还有其他方法,将在以后详细介绍