【NLP】隐马尔可夫模型三个基本问题相关算法实现
前言
隐马尔可夫模型详解,本篇详细介绍了隐马尔可夫模型的相关理论知识,为了进一步的理解它,本篇将通过具体的计算例子,通过代码实现解决三个基本问题的算法,前向-后向算法、Baum-Welch算法、Viterbi算法。
-
概率计算问题:
前向-后向算法给定模型 λ = ( A , B , π ) λ=(A,B,π) λ=(A,B,π) 和观测序列 Q = { q 1 , q 2 , . . . , q T } Q=\{q_1,q_2,...,q_T\} Q={q1,q2,...,qT},计算模型 λ λ λ 下观测到序列Q出现的概率 P ( Q ∣ λ ) P(Q|λ) P(Q∣λ)
-
学习问题:
Baum-Welch算法(状态未知)已知观测序列 Q = { q 1 , q 2 , . . . , q T } Q=\{q_1,q_2,...,q_T\} Q={q1,q2,...,qT},估计模型 λ = ( A , B , π ) λ=(A,B,π) λ=(A,B,π) 的参数,使得在该模型下观测序列 P ( Q ∣ λ ) P(Q|λ) P(Q∣λ) 最大。
-
预测问题:
Viterbi算法给定模型 λ = ( A , B , π ) λ=(A,B,π) λ=(A,B,π) 和观测序列 Q = { q 1 , q 2 , . . . , q T } Q=\{q_1,q_2,...,q_T\} Q={q1,q2,...,qT},求给定观测序列条件概率 P ( I ∣ Q , λ ) P(I|Q,λ) P(I∣Q,λ) 最大的状态序列 I I I
理论部分内容可参考 隐马尔可夫模型详解,本篇不再重复叙述。
本篇代码可见:Github
一、案例描述
假设有三个盒子,编号为 1 , 2 , 3 1,2,3 1,2,3 ;每个盒子都装有黑白两种颜色的小球,球的比例如下:
| 编号 | 白球 | 黑球 |
|---|---|---|
| 1 | 4 | 6 |
| 2 | 8 | 2 |
| 3 | 5 | 5 |
按照下列规则的方式进行有放回的抽取小球,得到球颜色的观测序列:
- 按照 π π π 的概率选择一个盒子,从盒子中随机抽取出一个小球,记录颜色后,放回盒子中;
- 按照某种条件概率选择新的盒子,重复该操作;
- 最终得到观测序列:“白黑白白黑”
该问题中的变量定义:
- 状态集合: S = { 盒 子 1 , 盒 子 2 , 盒 子 3 } S=\{盒子1,盒子2,盒子3\} S={盒子1,盒子2,盒子3}
- 观测集合: O = { 白 , 黑 } O=\{白,黑\} O={白,黑}
- 状态序列和观测序列的长度 T = 5 T=5 T=5
- 初始概率分布 π π π
π = ( 0.2 , 0.5 , 0.3 ) T \pi = (0.2,0.5,0.3)^T π=(0.2,0.5,0.3)T
- 状态转移概率矩阵 A A A
A = [ 0.5 0.4 0.1 0.2 0.2 0.6 0.2 0.5 0.3 ] A =\left[ \begin{matrix} 0.5 & 0.4&0.1\\ 0.2 & 0.2&0.6\\ 0.2 & 0.5&0.3 \end{matrix}\right] A=⎣⎡0.50.20.20.40.20.50.10.60.3⎦⎤
- 观测概率矩阵 B B B
B = [ 0.4 0.6 0.8 0.2 0.5 0.5 ] B =\left[ \begin{matrix} 0.4 & 0.6\\ 0.8 & 0.2\\ 0.5 & 0.5 \end{matrix}\right] B=⎣⎡0.40.80.50.60.20.5⎦⎤
在给定参数 π 、 A 、 B π、A、B π、A、B 的时候,得到观测序列 Y = { 白 , 黑 , 白 , 白 , 黑 } Y=\{白,黑,白,白,黑\} Y={白,黑,白,白,黑} 的概率是多少?
二、概率计算问题
2.1 前向算法
前向算法描述如下:
输入:隐马尔可夫模型 λ \lambda λ,观测序列 Y Y Y
输出:观测序列概率 P ( Y ∣ λ ) P(Y|\lambda) P(Y∣λ)
(1)初值
α 1 ( i ) = π i b i ( y 1 ) , i = 1 , 2 , . . , N \alpha_1(i) = \pi_ib_i(y_1),i = 1,2,..,N α1(i)=πibi(y1),i=1,2,..,N
(2)递推 \quad 对 t = 1 , 2 , . . . , T − 1 t = 1,2,...,T-1 t=1,2,...,T−1
α t + 1 ( i ) = [ ∑ j = 1 N α t ( j ) a i j ] b i ( y t + 1 ) , i = 1 , 2 , . . . , N \alpha_{t+1}(i) = \Big[\sum_{j=1}^N \alpha_t(j)a_{ij}\Big]b_i(y_{t+1}),i = 1,2,...,N αt+1(i)=[j=1∑Nαt(j)aij]bi(yt+1),i=1,2,...,N
(3)终止
p ( Y ∣ λ ) = ∑ i = 1 N α T ( i ) p(Y|\lambda) = \sum_{i=1}^N \alpha_T(i) p(Y∣λ)=i=1∑NαT(i)
手动计算:
(1)初值
α 1 ( 1 ) = π 1 b 1 ( y 1 ) = 0.2 × 0.4 = 0.08 \alpha_1(1)=\pi_1b_1(y_1)=0.2 \times 0.4 = 0.08 α1(1)=π1b1(y1)=0.2×0.4=0.08
α 1 ( 2 ) = π 2 b 2 ( y 1 ) = 0.5 × 0.8 = 0.40 \alpha_1(2)=\pi_2b_2(y_1)=0.5 \times 0.8 = 0.40 α1(2)=π2b2(y1)=0.5×0.8=0.40
α 1 ( 2 ) = π 3 b 3 ( y 1 ) = 0.3 × 0.5 = 0.15 \alpha_1(2)=\pi_ 3b_3(y_1)=0.3 \times 0.5 = 0.15 α1(2)=π3b3(y1)=0.3×0.5=0.15
(2)递推
α 2 ( 1 ) = ( ∑ j = 1 3 α 1 ( j ) a j 1 ) b 1 ( y 2 ) = ( 0.08 × 0.5 + 0.4 × 0.2 + 0.15 × 0.2 ) × 0.6 = 0.09 α 2 ( 2 ) = ( ∑ j = 1 3 α 1 ( j ) a j 2 ) b 2 ( y 2 ) = ( 0.08 × 0.4 + 0.4 × 0.2 + 0.15 × 0.5 ) × 0.2 = 0.0374 α 2 ( 3 ) = ( ∑ j = 1 3 α 1 ( j ) a j 3 ) b 3 ( y 2 ) = ( 0.08 × 0.1 + 0.4 × 0.6 + 0.15 × 0.3 ) × 0.5 = 0.1465 \alpha_2(1)=\Big(\sum_{j=1}^3\alpha_1(j)a_{j1}\Big)b_1(y_2)=\Big(0.08\times0.5+0.4\times0.2+0.15\times0.2\Big)\times0.6=0.09\\ \alpha_2(2)=\Big(\sum_{j=1}^3\alpha_1(j)a_{j2}\Big)b_2(y_2)=\Big(0.08\times0.4+0.4\times0.2+0.15\times0.5\Big)\times0.2=0.0374\\ \alpha_2(3)=\Big(\sum_{j=1}^3\alpha_1(j)a_{j3}\Big)b_3(y_2)=\Big(0.08\times0.1+0.4\times0.6+0.15\times0.3\Big)\times0.5=0.1465 α2(1)=(j=1∑3α1(j)aj1)b1(y2)=(0.08×0.5+0.4×0.2+0.15×0.2)×0.6=0.09α2(2)=(j=1∑3α1(j)aj2)b2(y2)=(0.08×0.4+0.4×0.2+0.15×0.5)×0.2=0.0374α2(3)=(j=1∑3α1(j)aj3)b3(y2)=(0.08×0.1+0.4×0.6+0.15×0.3)×0.5=0.1465
α 3 ( 1 ) = ( ∑ j = 1 3 α 2 ( j ) a j 1 ) b 1 ( y 3 ) = ( 0.09 × 0.5 + 0.0374 × 0.2 + 0.1465 × 0.2 ) × 0.4 = 0.032712 α 3 ( 2 ) = ( ∑ j = 1 3 α 2 ( j ) a j 2 ) b 2 ( y 3 ) = ( 0.09 × 0.4 + 0.0374 × 0.2 + 0.1465 × 0.5 ) × 0.8 = 0.093384 α 3 ( 3 ) = ( ∑ j = 1 3 α 2 ( j ) a j 3 ) b 3 ( y 3 ) = ( 0.09 × 0.1 + 0.0374 × 0.6 + 0.1465 × 0.3 ) × 0.5 = 0.037695 \alpha_3(1)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j1}\Big)b_1(y_3)=\Big(0.09\times0.5+0.0374\times0.2+0.1465\times0.2\Big)\times0.4=0.032712\\ \alpha_3(2)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j2}\Big)b_2(y_3)=\Big(0.09\times0.4+0.0374\times0.2+0.1465\times0.5\Big)\times0.8=0.093384\\ \alpha_3(3)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j3}\Big)b_3(y_3)=\Big(0.09\times0.1+0.0374\times0.6+0.1465\times0.3\Big)\times0.5=0.037695 α3(1)=(j=1∑3α2(j)aj1)b1(y3)=(0.09×0.5+0.0374×0.2+0.1465×0.2)×0.4=0.032712α3(2)=(j=1∑3α2(j)aj2)b2(y3)=(0.09×0.4+0.0374×0.2+0.1465×0.5)×0.8=0.093384α3(3)=(j=1∑3α2(j)aj3)b3(y3)=(0.09×0.1+0.0374×0.6+0.1465×0.3)×0.5=0.037695
α 4 ( 1 ) = ( ∑ j = 1 3 α 2 ( j ) a j 1 ) b 1 ( y 4 ) = ( 0.032712 × 0.5 + 0.093384 × 0.2 + 0.037695 × 0.2 ) × 0.4 = 0.01702872 α 4 ( 2 ) = ( ∑ j = 1 3 α 2 ( j ) a j 2 ) b 2 ( y 4 ) = ( 0.032712 × 0.4 + 0.093384 × 0.2 + 0.037695 × 0.5 ) × 0.8 = 0.04048728 α 4 ( 3 ) = ( ∑ j = 1 3 α 2 ( j ) a j 3 ) b 3 ( y 4 ) = ( 0.032712 × 0.1 + 0.093384 × 0.6 + 0.037695 × 0.3 ) × 0.5 = 0.03530505 \alpha_4(1)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j1}\Big)b_1(y_4)=\Big(0.032712\times0.5+0.093384\times0.2+0.037695\times0.2\Big)\times0.4=0.01702872\\ \alpha_4(2)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j2}\Big)b_2(y_4)=\Big(0.032712\times0.4+0.093384\times0.2+0.037695\times0.5\Big)\times0.8=0.04048728\\ \alpha_4(3)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j3}\Big)b_3(y_4)=\Big(0.032712\times0.1+0.093384\times0.6+0.037695\times0.3\Big)\times0.5=0.03530505 α4(1)=(j=1∑3α2(j)aj1)b1(y4)=(0.032712×0.5+0.093384×0.2+0.037695×0.2)×0.4=0.01702872α4(2)=(j=1∑3α2(j)aj2)b2(y4)=(0.032712×0.4+0.093384×0.2+0.037695×0.5)×0.8=0.04048728α4(3)=(j=1∑3α2(j)aj3)b3(y4)=(0.032712×0.1+0.093384×0.6+0.037695×0.3)×0.5=0.03530505
α 5 ( 1 ) = ( ∑ j = 1 3 α 2 ( j ) a j 1 ) b 1 ( y 5 ) = ( 0.01702872 × 0.5 + 0.04048728 × 0.2 + 0.03530505 × 0.2 ) × 0.6 = 0.0142036956 α 5 ( 2 ) = ( ∑ j = 1 3 α 2 ( j ) a j 2 ) b 2 ( y 5 ) = ( 0.01702872 × 0.4 + 0.04048728 × 0.2 + 0.03530505 × 0.5 ) × 0.2 = 0.0065122938 α 5 ( 3 ) = ( ∑ j = 1 3 α 2 ( j ) a j 3 ) b 3 ( y 5 ) = ( 0.01702872 × 0.1 + 0.04048728 × 0.6 + 0.03530505 × 0.3 ) × 0.5 = 0.0182933775 \alpha_5(1)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j1}\Big)b_1(y_5)=\Big(0.01702872\times0.5+0.04048728\times0.2+0.03530505\times0.2\Big)\times0.6=0.0142036956\\ \alpha_5(2)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j2}\Big)b_2(y_5)=\Big(0.01702872\times0.4+0.04048728\times0.2+0.03530505\times0.5\Big)\times0.2=0.0065122938\\ \alpha_5(3)=\Big(\sum_{j=1}^3\alpha_2(j)a_{j3}\Big)b_3(y_5)=\Big(0.01702872\times0.1+0.04048728\times0.6+0.03530505\times0.3\Big)\times0.5=0.0182933775 α5(1)=(j=1∑3α2(j)aj1)b1(y5)=(0.01702872×0.5+0.04048728×0.2+0.03530505×0.2)×0.6=0.0142036956α5(2)=(j=1∑3α2(j)aj2)b2(y5)=(0.01702872×0.4+0.04048728×0.2+0.03530505×0.5)×0.2=0.0065122938α5(3)=(j=1∑3α2(j)aj3)b3(y5)=(0.01702872×0.1+0.04048728×0.6+0.03530505×0.3)×0.5=0.0182933775
(3)终止
p ( Y ∣ λ ) = ∑ i = 1 3 α 5 ( i ) = 0.0142036956 + 0.0065122938 + 0.0182933775 = 0.0390093669 p(Y|\lambda) = \sum_{i=1}^3 \alpha_5(i) =0.0142036956+0.0065122938+0.0182933775=0.0390093669 p(Y∣λ)=i=1∑3α5(i)=0.0142036956+0.0065122938+0.0182933775=0.0390093669
程序运行结果:

上图中, α \alpha α 矩阵中每行表示 α T ( i ) \alpha_T(i) αT(i)
通过比较我们手算的和程序的运行结果,我们发现他们的结果是一样的(忽略精度问题)
程序中有注释,具体内容可查看源代码
代码可见:hmm01/forward_probability.py
2.2 后向算法
后向算法描述如下:
输入:隐马尔可夫模型 λ \lambda λ,观测序列 Y Y Y
输出:观测序列概率 P ( Y ∣ λ ) P(Y|\lambda) P(Y∣λ)
(1)初值
β T ( i ) = 1 , i = 1 , 2 , . . , N \beta_T(i) = 1,i = 1,2,..,N βT(i)=1,i=1,2,..,N
(2)递推 \quad 对 t = T − 1 , T − 2 , . . . , 1 t = T-1,T-2,...,1 t=T−1,T−2,...,1
β t ( i ) = ∑ j = 1 N a i j b j ( y t + 1 ) β t + 1 ( j ) , i = 1 , 2 , . . . , N \beta_t(i) = \sum_{j=1}^N a_{ij}b_j(y_{t+1})\beta_{t+1}(j),i = 1,2,...,N βt(i)=j=1∑Naijbj(yt+1)βt+1(j),i=1,2,...,N
(3)终止
p ( Y ∣ λ ) = ∑ i = 1 N π i b i ( y 1 ) β 1 ( i ) p(Y|\lambda) = \sum_{i=1}^N \pi_ib_i(y_1)\beta_1(i) p(Y∣λ)=i=1∑Nπibi(y1)β1(i)
手动计算:
(1)初值
β 5 ( 1 ) = 1 β 5 ( 2 ) = 1 β 5 ( 3 ) = 1 \beta_5(1)=1\\ \beta_5(2)=1\\ \beta_5(3)=1 β5(1)=1β5(2)=1β5(3)=1
(2)递推
β 4 ( 1 ) = ∑ j = 1 3 a 1 j b j ( y 5 ) β 5 ( j ) = 0.5 × 0.6 × 1 + 0.4 × 0.2 × 1 + 0.1 × 0.5 × 1 = 0.43 β 4 ( 2 ) = ∑ j = 1 3 a 2 j b j ( y 5 ) β 5 ( j ) = 0.2 × 0.6 × 1 + 0.2 × 0.2 × 1 + 0.6 × 0.5 × 1 = 0.46 β 4 ( 3 ) = ∑ j = 1 3 a 3 j b j ( y 5 ) β 5 ( j ) = 0.2 × 0.6 × 1 + 0.5 × 0.2 × 1 + 0.3 × 0.5 × 1 = 0.37 \beta_4(1)=\sum_{j=1}^3a_{1j}b_j(y_5)\beta_5(j)=0.5\times0.6\times 1+0.4\times0.2\times1 +0.1\times0.5\times1=0.43\\ \beta_4(2)=\sum_{j=1}^3a_{2j}b_j(y_5)\beta_5(j)=0.2\times0.6\times 1+0.2\times0.2\times1 +0.6\times0.5\times1=0.46\\ \beta_4(3)=\sum_{j=1}^3a_{3j}b_j(y_5)\beta_5(j)=0.2\times0.6\times 1+0.5\times0.2\times1 +0.3\times0.5\times1=0.37 β4(1)=j=1∑3a1jbj(y5)β5(j)=0.5×0.6×1+0.4×0.2×1+0.1×0.5×1=0.43β4(2)=j=1∑3a2jbj(y5)β5(j)=0.2×0.6×1+0.2×0.2×1+0.6×0.5×1=0.46β4(3)=j=1∑3a3jbj(y5)β5(j)=0.2×0.6×1+0.5×0.2×1+0.3×0.5×1=0.37
β 3 ( 1 ) = ∑ j = 1 3 a 1 j b j ( y 4 ) β 4 ( j ) = 0.5 × 0.4 × 0.43 + 0.4 × 0.8 × 0.46 + 0.1 × 0.5 × 0.37 = 0.2517 β 3 ( 2 ) = ∑ j = 1 3 a 2 j b j ( y 4 ) β 4 ( j ) = 0.2 × 0.4 × 0.43 + 0.2 × 0.8 × 0.46 + 0.6 × 0.5 × 0.37 = 0.219 β 3 ( 3 ) = ∑ j = 1 3 a 3 j b j ( y 4 ) β 4 ( j ) = 0.2 × 0.4 × 0.43 + 0.5 × 0.8 × 0.46 + 0.3 × 0.5 × 0.37 = 0.2739 \beta_3(1)=\sum_{j=1}^3a_{1j}b_j(y_4)\beta_4(j)=0.5\times0.4\times 0.43+0.4\times0.8\times0.46 +0.1\times0.5\times0.37=0.2517\\ \beta_3(2)=\sum_{j=1}^3a_{2j}b_j(y_4)\beta_4(j)=0.2\times0.4\times 0.43+0.2\times0.8\times0.46 +0.6\times0.5\times0.37=0.219\\ \beta_3(3)=\sum_{j=1}^3a_{3j}b_j(y_4)\beta_4(j)=0.2\times0.4\times 0.43+0.5\times0.8\times0.46 +0.3\times0.5\times0.37=0.2739 β3(1)=j=1∑3a1jbj(y4)β4(j)=0.5×0.4×0.43+0.4×0.8×0.46+0.1×0.5×0.37=0.2517β3(2)=j=1∑3a2jbj(y4)β4(j)=0.2×0.4×0.43+0.2×0.8×0.46+0.6×0.5×0.37=0.219β3(3)=j=1∑3a3jbj(y4)β4(j)=0.2×0.4×0.43+0.5×0.8×0.46+0.3×0.5×0.37=0.2739
β 2 ( 1 ) = ∑ j = 1 3 a 1 j b j ( y 3 ) β 3 ( j ) = 0.5 × 0.4 × 0.2517 + 0.4 × 0.8 × 0.219 + 0.1 × 0.5 × 0.2739 = 0.134115 β 2 ( 2 ) = ∑ j = 1 3 a 2 j b j ( y 3 ) β 3 ( j ) = 0.2 × 0.4 × 0.2517 + 0.2 × 0.8 × 0.219 + 0.6 × 0.5 × 0.2739 = 0.137346 β 2 ( 3 ) = ∑ j = 1 3 a 3 j b j ( y 3 ) β 3 ( j ) = 0.2 × 0.4 × 0.2517 + 0.5 × 0.8 × 0.219 + 0.3 × 0.5 × 0.2739 = 0.148821 \beta_2(1)=\sum_{j=1}^3a_{1j}b_j(y_3)\beta_3(j)=0.5\times0.4\times 0.2517+0.4\times0.8\times0.219+0.1\times0.5\times0.2739=0.134115\\ \beta_2(2)=\sum_{j=1}^3a_{2j}b_j(y_3)\beta_3(j)=0.2\times0.4\times 0.2517+0.2\times0.8\times0.219+0.6\times0.5\times0.2739=0.137346\\ \beta_2(3)=\sum_{j=1}^3a_{3j}b_j(y_3)\beta_3(j)=0.2\times0.4\times 0.2517+0.5\times0.8\times0.219+0.3\times0.5\times0.2739=0.148821 β2(1)=j=1∑3a1jbj(y3)β3(j)=0.5×0.4×0.2517+0.4×0.8×0.219+0.1×0.5×0.2739=0.134115β2(2)=j=1∑3a2jbj(y3)β3(j)=0.2×0.4×0.2517+0.2×0.8×0.219+0.6×0.5×0.2739=0.137346β2(3)=j=1∑3a3jbj(y3)β3(j)=0.2×0.4×0.2517+0.5×0.8×0.219+0.3×0.5×0.2739=0.148821
β 1 ( 1 ) = ∑ j = 1 3 a 1 j b j ( y 2 ) β 2 ( j ) = 0.5 × 0.6 × 0.134115 + 0.4 × 0.2 × 0.137346 + 0.1 × 0.5 × 0.148821 = 0.05866323 β 1 ( 2 ) = ∑ j = 1 3 a 2 j b j ( y 2 ) β 2 ( j ) = 0.2 × 0.6 × 0.134115 + 0.2 × 0.2 × 0.137346 + 0.6 × 0.5 × 0.148821 = 0.06623394 β 1 ( 3 ) = ∑ j = 1 3 a 3 j b j ( y 2 ) β 2 ( j ) = 0.2 × 0.6 × 0.134115 + 0.5 × 0.2 × 0.137346 + 0.3 × 0.5 × 0.148821 = 0.05215155 \beta_1(1)=\sum_{j=1}^3a_{1j}b_j(y_2)\beta_2(j)=0.5\times0.6\times 0.134115+0.4\times0.2\times0.137346+0.1\times0.5\times0.148821=0.05866323\\ \beta_1(2)=\sum_{j=1}^3a_{2j}b_j(y_2)\beta_2(j)=0.2\times0.6\times 0.134115+0.2\times0.2\times0.137346 +0.6\times0.5\times0.148821=0.06623394\\ \beta_1(3)=\sum_{j=1}^3a_{3j}b_j(y_2)\beta_2(j)=0.2\times0.6\times 0.134115+0.5\times0.2\times0.137346+0.3\times0.5\times0.148821=0.05215155 β1(1)=j=1∑3a1jbj(y2)β2(j)=0.5×0.6×0.134115+0.4×0.2×0.137346+0.1×0.5×0.148821=0.05866323β1(2)=j=1∑3a2jbj(y2)β2(j)=0.2×0.6×0.134115+0.2×0.2×0.137346+0.6×0.5×0.148821=0.06623394β1(3)=j=1∑3a3jbj(y2)β2(j)=0.2×0.6×0.134115+0.5×0.2×0.137346+0.3×0.5×0.148821=0.05215155
(3)终止
p ( Y ∣ λ ) = ∑ i = 1 3 π i b i ( y 1 ) β 1 ( i ) = 0.2 × 0.4 × 0.05866323 + 0.5 × 0.8 × 0.06623394 + 0.3 × 0.5 × 0.05215155 = 0.0390093669 p(Y|\lambda) = \sum_{i=1}^3 \pi_ib_i(y_1)\beta_1(i)=0.2\times0.4\times0.05866323+0.5\times0.8\times0.06623394+0.3\times0.5\times0.05215155=0.0390093669 p(Y∣λ)=i=1∑3πibi(y1)β1(i)=0.2×0.4×0.05866323+0.5×0.8×0.06623394+0.3×0.5×0.05215155=0.0390093669
程序运行结果:

得到的结果和前向算法一样,具体内容可参考源代码注释
代码可见:hmm01/backward_probability.py
三、学习问题
Baum-Welch算法描述如下:
输入:观测数据 Y = ( y 1 , y 2 , . . . , y T ) Y = (y_1,y_2,...,y_T) Y=(y1,y2,...,yT)
输出:隐马尔可夫模型参数
(1)初始化
对 n = 0 n=0 n=0,选取 a i j ( 0 ) , b j ( k ) ( 0 ) , π i ( 0 ) a_{ij}^{(0)},{b_j(k)}^{(0)},\pi_i^{(0)} aij(0),bj(k)(0),πi(0),得到模型 λ ( 0 ) = ( A ( 0 ) , B ( 0 ) , π ( 0 ) ) \lambda^{(0)} = (A^{(0)},B^{(0)},\pi^{(0)}) λ(0)=(A(0),B(0),π(0))
(2)递推,对 n = 1 , 2 , . . . , n = 1,2,..., n=1,2,...,
a i j ( n + 1 ) = ∑ t = 1 T − 1 P ( Y , i t = i , i t + 1 = j ∣ λ ‾ ) ∑ t = 1 T − 1 P ( Y , i t = i , ∣ λ ‾ ) a_{ij}^{(n+1)} = \frac{\sum_{t=1}^{T-1} P(Y,i_t=i,i_{t+1} = j|\overline{\lambda})}{\sum_{t=1}^{T-1}P(Y,i_t=i,|\overline{\lambda})} aij(n+1)=∑t=1T−1P(Y,it=i,∣λ)∑t=1T−1P(Y,it=i,it+1=j∣λ)
b j ( k ) ( n + 1 ) = ∑ t = 1 T P ( Y , i t = j ∣ λ ‾ ) I ( y t = v k ) ∑ t = 1 T P ( Y , i t = j ∣ λ ‾ ) b_j(k)^{(n+1)} = \frac{\sum_{t=1}^T P(Y,i_t = j|\overline{\lambda})I(y_t=v_k)}{\sum_{t=1}^T P(Y,i_t = j|\overline{\lambda})} bj(k)(n+1)=∑t=1TP(Y,it=j∣λ)∑t=1TP(Y,it=j∣λ)I(yt=vk)
π i ( n + 1 ) = P ( Y , i 1 = i ∣ λ ‾ ) ∑ i = 1 N P ( Y , i 1 = i ∣ λ ‾ ) \pi_i^{(n+1)}=\frac{P(Y,i_1 = i|\overline{\lambda})}{\sum_{i=1}^N P(Y,i_1 = i|\overline{\lambda})} πi(n+1)=∑i=1NP(Y,i1=i∣λ)P(Y,i1=i∣λ)
右端各值按模型 λ ( n ) = ( A ( n ) , B ( n ) , π ( n ) ) \lambda^{(n)} = (A^{(n)},B^{(n)},\pi^{(n)}) λ(n)=(A(n),B(n),π(n))计算
(3)终止。得到模型参数 λ ( n + 1 ) = ( A ( n + 1 ) , B ( n + 1 ) , π ( n + 1 ) ) \lambda^{(n+1)} = (A^{(n+1)},B^{(n+1)},\pi^{(n+1)}) λ(n+1)=(A(n+1),B(n+1),π(n+1))
利用前向和后向概率对Baum-Welch算法中的表达式进行修改:
- 给定模型 λ \lambda λ 和观测序列 Y Y Y,在时刻 t t t 处于状态 q i q_i qi 的概率,记为:
γ t ( i ) = P ( i t = q i ∣ Y , λ ) = P ( i t = q i , Y ∣ λ ) P ( Y ∣ λ ) = α t ( i ) β t ( i ) ∑ j = 1 N α t ( j ) β t ( j ) \gamma_t(i) = P(i_t=q_i|Y,\lambda)=\frac{P(i_t=q_i,Y|\lambda)}{P(Y|\lambda)}=\frac{\alpha_t(i)\beta_t(i)}{\sum_{j=1}^N\alpha_t(j)\beta_t(j)} γt(i)=P(it=qi∣Y,λ)=P(Y∣λ)P(it=qi,Y∣λ)=∑j=1Nαt(j)βt(j)αt(i)βt(i)
其中:
α t ( i ) β t ( i ) = P ( i t = q i , Y ∣ λ ) \alpha_t(i)\beta_t(i) = P(i_t=q_i,Y|\lambda) αt(i)βt(i)=P(it=qi,Y∣λ)
def calc_gamma(alpha, beta, gamma):
"""
根据alphe和beta的值计算gamma值
最终结果保存在gamma矩阵中
"""
T = len(alpha)
n_range = range(len(alpha[0]))
tmp = [0 for i in n_range]
for t in range(T):
# 累加t时刻对应的所有状态值的前向概率和后向概率,从而计算分母
for i in n_range:
tmp[i] = alpha[t][i] * beta[t][i]
sum_alpha_beta_of_t = np.sum(tmp)
# 更新gamma值
for i in n_range:
gamma[t][i] = tmp[i] / sum_alpha_beta_of_t
- 给定模型 λ \lambda λ 和观测序列 Y Y Y,在时刻 t t t 处于状态 q i q_i qi 且在时刻 t + 1 t+1 t+1 处于 q j q_j qj 的概率,记为:
ξ t ( i , j ) = P ( i t = q i , i t + 1 = q j ∣ Y , λ ) = P ( i t = q i , i t + 1 = q j , Y ∣ λ ) P ( Y ∣ λ ) \xi_t(i,j) = P(i_t=q_i,i_{t+1}=q_j|Y,\lambda)=\frac{P(i_t=q_i,i_{t+1}=q_j,Y|\lambda)}{P(Y|\lambda)} ξt(i,j)=P(it=qi,it+1=qj∣Y,λ)=P(Y∣λ)P(it=qi,it+1=qj,Y∣λ)
= P ( i t = q i , i t + 1 = q j , Y ∣ λ ) ∑ i = 1 N ∑ j = 1 N P ( i t = q i , i t + 1 = q j , Y ∣ λ ) =\frac{P(i_t=q_i,i_{t+1}=q_j,Y|\lambda)}{\sum_{i=1}^N\sum_{j=1}^NP(i_t=q_i,i_{t+1}=q_j,Y|\lambda)} =∑i=1N∑j=1NP(it=qi,it+1=qj,Y∣λ)P(it=qi,it+1=qj,Y∣λ)
= α t ( i ) a i j b j ( y t + 1 ) β t + 1 ( j ) ∑ i = 1 N ∑ j = 1 N α t ( i ) a i j b j ( y t + 1 ) β t + 1 ( j ) =\frac{\alpha_t(i)a_{ij}b_j(y_{t+1})\beta_{t+1}(j)}{\sum_{i=1}^N\sum_{j=1}^N\alpha_t(i)a_{ij}b_j(y_{t+1})\beta_{t+1}(j)} =∑i=1N∑j=1Nαt(i)aijbj(yt+1)βt+1(j)αt(i)aijbj(yt+1)βt+1(j)
其中:
P ( i t = q i , i t + 1 = q j , Y ∣ λ ) = α t ( i ) a i j b j ( y t + 1 ) β t + 1 ( j ) P(i_t=q_i,i_{t+1}=q_j,Y|\lambda)=\alpha_t(i)a_{ij}b_j(y_{t+1})\beta_{t+1}(j) P(it=qi,it+1=qj,Y∣λ)=αt(i)aijbj(yt+1)βt+1(j)
以上, α t ( i ) , β t ( i ) \alpha_t(i),\beta_t(i) αt(i),βt(i)分别表示前向和后向概率
def calc_ksi(alpha, beta, A, B, Q, ksi, fetch_index_by_obs_seq=None):
"""
计算时刻t的时候状态为i,时刻t+1的时候状态为j的联合概率ksi
alpha:对应的前向概率值
beta:对应的后向概率值
A:状态转移矩阵
B: 状态和观测值之间的转移矩阵
Q: 观测值列表
ksi:待求解的ksi矩阵
fetch_index_by_obs_seq: 根据序列获取对应索引值的函数,可以为空
NOTE:
1. ord函数的含义是将一个单个的字符转换为数字, eg: ord('a') = 97; ord('中')=20013;底层其实是将字符转换为ASCII码;
2. 最终会直接更新参数中的ksi矩阵
"""
# 0. 初始化
# 初始化序列转换为索引的方法
fetch_index_by_obs_seq_f = fetch_index_by_obs_seq
if fetch_index_by_obs_seq_f is None:
fetch_index_by_obs_seq_f = lambda obs, obs_index: ord(obs[obs_index])
# 初始化相关的参数值: n、T
T = len(alpha)
n = len(A)
# 1. 开始迭代更新
n_range = range(n)
tmp = np.zeros((n, n))
for t in range(T - 1):
# 1. 计算t时刻状态为i,t+1时刻状态为j的概率值
for i in n_range:
for j in n_range:
tmp[i][j] = alpha[t][i] * A[i][j] * B[j][fetch_index_by_obs_seq_f(Q, t + 1)] * beta[t + 1][j]
# 2. 计算t时候的联合概率和
sum_pro_of_t = np.sum(tmp)
# 2. 计算时刻t时候的联合概率ksi
for i in n_range:
for j in n_range:
ksi[t][i][j] = tmp[i][j] / sum_pro_of_t
修改算法中第二步:递推
a i j ( n + 1 ) = ∑ t = 1 T − 1 ξ t ( i , j ) ∑ t = 1 T − 1 γ t ( i ) a_{ij}^{(n+1)}=\frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{t=1}^{T-1}\gamma_t(i)} aij(n+1)=∑t=1T−1γt(i)∑t=1T−1ξt(i,j)
b j ( k ) ( n + 1 ) = ∑ t = 1 , y t = v k T γ t ( j ) ∑ t = 1 T γ t ( j ) {b_j(k)}^{(n+1)}=\frac{\sum_{t=1,y_t=v_k}^T\gamma_t(j)}{\sum_{t=1}^T\gamma_t(j)} bj(k)(n+1)=∑t=1Tγt(j)∑t=1,yt=vkTγt(j)
π t ( n + 1 ) = γ t ( i ) \pi_t^{(n+1)}=\gamma_t(i) πt(n+1)=γt(i)
代码中,我们首先计算了 γ , ξ \gamma,\xi γ,ξ的值,然后使用该值代入Baum-Welch算法中。
计算 γ \gamma γ 的运行结果:

可见代码:hmm01/single_state_probability_of_gamma.py
计算 ξ \xi ξ 的运行结果:

可见代码:hmm01/continuous_state_probability_of_ksi.py
Baum-Welch算法实现:

代码可见:hmm01/baum_welch.py
四、预测问题
维特比算法描述如下:
输入:模型 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π) 和观测 O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T) O=(o1,o2,...,oT);
输出:最优路径 I ∗ = ( i 1 ∗ , i 2 ∗ , . . . , i T ∗ ) I^* = (i_1^*,i_2^*,...,i_T^*) I∗=(i1∗,i2∗,...,iT∗);
(1)初始化
δ 1 ( i ) = π i b i ( o 1 ) , i = 1 , 2 , . . . , N \delta_1(i)=\pi_ib_i(o_1),i=1,2,...,N δ1(i)=πibi(o1),i=1,2,...,N
ψ 1 ( i ) = 0 , i = 1 , 2 , . . , N \psi_1(i) = 0, i=1,2,..,N ψ1(i)=0,i=1,2,..,N
(2)递推,对 t = 2 , 3 , . . . , T t=2,3,...,T t=2,3,...,T
δ t ( i ) = max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] b i ( o t ) , i = 1 , 2 , . . . , N \delta_t(i)=\max_{1 \leq j \leq N}[\delta_{t-1}(j)a_{ji}]b_i(o_t), i=1,2,...,N δt(i)=1≤j≤Nmax[δt−1(j)aji]bi(ot),i=1,2,...,N
ψ t ( i ) = a r g max 1 ≤ j ≤ N [ δ t − 1 ( j ) a j i ] , i = 1 , 2 , . . . , N \psi_t(i) = arg \max_{1 \leq j \leq N}[\delta_{t-1}(j)a_{ji}], i=1,2,...,N ψt(i)=arg1≤j≤Nmax[δt−1(j)aji],i=1,2,...,N
(3)终止
P ∗ = max 1 ≤ i ≤ N δ T ( i ) P^* = \max_{1\leq i \leq N}\delta_T(i) P∗=1≤i≤NmaxδT(i)
i T ∗ = a r g max 1 ≤ i ≤ N [ δ T ( i ) ] i_T^* = arg \max_{1 \leq i \leq N}[\delta_T(i)] iT∗=arg1≤i≤Nmax[δT(i)]
(4)最优路径回溯,对 t = T − 1 , T − 2 , . . . , 1 t=T-1,T-2,...,1 t=T−1,T−2,...,1
i t ∗ = ψ t + 1 ( i t + 1 ∗ ) i_t^*=\psi_{t+1}(i_{t+1}^*) it∗=ψt+1(it+1∗)
求得最优路径 I ∗ = ( i 1 ∗ , i 2 ∗ , . . . , i T ∗ ) I^*=(i_1^*,i_2^*,...,i_T^*) I∗=(i1∗,i2∗,...,iT∗)
实例计算可参考:隐马尔可夫模型详解中对应部分的实例。而程序中的 A , B , π A,B,\pi A,B,π 是我们设置的,实际应用中 A , B , π A,B,\pi A,B,π 是根据学习算法得到的最优模型进行预测
维特比算法运行结果:

代码可见:hmm01/viterbi.py
五、改进版本
在计算相关概率的时候,如果我们的观测序列比较长,程序前向概率结果如下(只截取了后面一部分):

图中我们可以看出,随着观测序列增加,前向概率在逐渐减少趋向于0,因此很有可能造成溢出,我们需要对此进行一定的改进。
我们只需要对之前的求得的值进行 log_sum_exp 操作即可
def log_sum_exp(a):
"""
可以参考numpy中的log sum exp的API
scipy.misc.logsumexp
:param a:
:return:
"""
a = np.asarray(a)
a_max = max(a)
tmp = 0
for k in a:
tmp += math.exp(k - a_max)
return a_max + math.log(tmp)
修改后运行结果:
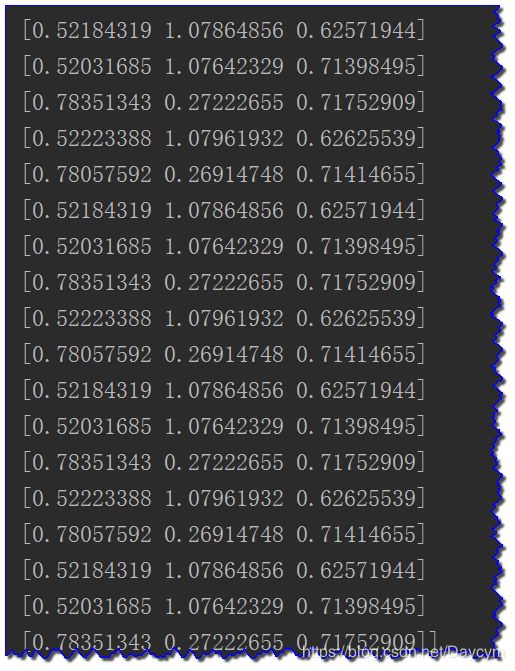
有上图可见,值都在0-1之间
改版后的代码可见:hmm02/common.py 和 hmm02/hmm_learn.py
六、应用(分词)
本节我们就使用上面的 hmm02/common.py 和 hmm02/hmm_learn.py 来训练分词用的HMM,大体可分为如下步骤:
- 训练数据的获取(这里使用的
pku_training.utf8) - 读取上面的训练数据到模型训练(加载数据、初始化 ( π , A , B ) (\pi,A,B) (π,A,B)、模型训练、返回结果)
- 模型的保存
- 模型加载
- 应用模型分词

看上去分词效果还有点样子,好像有那么些回事,当然要想分词效果好,自然需要更多的词库。
具体内容可见代码注释部分
代码可见:hmm02/split_word_with_hmm.py
七、总结
我相信通过代码的理解,我们更能对理论部分的一些公式进一步的理解,而且代码也是根据公式写出来的。具体的内容需各自查看代码及注释。
一开始,我们是直接根据公式来写的,后来发现在观测序列越长的情况下,概率会越趋向于0,然后我们做了log_sum_exp ,其实代码底层也加了这个。