CTR预估 论文实践(六)--Wide & Deep Learning for Recommender Systems
Wide & Deep 模型实践
博客代码均以上传至GitHub,欢迎follow和start~~!
1. 数据集
数据集如下,其中,最后一行是label,预测收入是否超过5万美元,二分类问题。
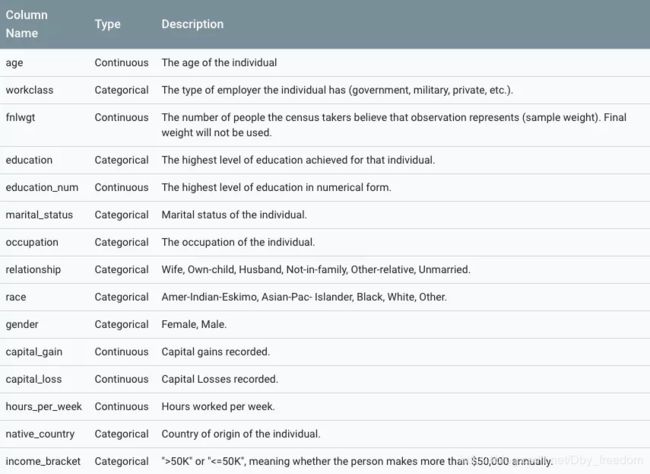
2. Wide Linear Model
离散特征处理分为两种情况:
- 知道所有的不同取值,而且取值不多。
tf.feature_column.categorical_column_with_vocabulary_list - 不知道所有不同取值,或者取值非常多。
tf.feature_column.categorical_column_with_hash_bucket
## 3.1 Base Categorical Feature Columns
# 如果我们知道所有的取值,并且取值不是很多
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried', 'Other-relative'
]
)
# 如果不知道有多少取值
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000
)
原始连续特征:tf.feature_column.numeric_column
# 3.2 Base Continuous Feature Columns
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
规范化到[0,1]的连续特征:tf.feature_column.bucketized_column
# 3.2.1 连续特征离散化
# 之所以这么做是因为:有些时候连续特征和label之间不是线性的关系。
# 可能刚开始是正的线性关系,后面又变成了负的线性关系,这样一个折线的关系整体来看就不再是线性关系。
# bucketization 装桶
# 10个边界,11个桶
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
组合特征/交叉特征:tf.feature_column.crossed_column
# 3.3 组合特征/交叉特征
education_x_occupation = tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000)
age_buckets_x_education_x_occupation = tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000
)
组装模型:这里主要用了离散特征 + 组合特征
# 4. 模型
"""
之前的特征:
1. CategoricalColumn
2. NumericalColumn
3. BucketizedColumn
4. CrossedColumn
这些特征都是FeatureColumn的子类,可以放到一起
"""
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_column = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000
),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000
)
]
model_dir = "./model/wide_component"
model = tf.estimator.LinearClassifier(
model_dir = model_dir, feature_columns = base_columns + crossed_column
)
训练 & 评估:
# 5. Train & Evaluate & Predict
model.train(input_fn=lambda: input_fn(data_file=train_file, num_epochs=1, shuffle=True, batch_size=512))
results = model.evaluate(input_fn=lambda: input_fn(val_file, 1, False, 512))
for key in sorted(results):
print("{0:20}: {1:.4f}".format(key, results[key]))
运行结果:
Parsing ./data/adult.data
2018-12-21 15:39:37.182512: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Parsing ./data/adult.data
accuracy : 0.8436
accuracy_baseline : 0.7592
auc : 0.8944
auc_precision_recall: 0.7239
average_loss : 0.3395
global_step : 256.0000
label/mean : 0.2408
loss : 172.7150
prediction/mean : 0.2416
Parsing ./data/adult.test
3. Wide & Deep Model
Deep部分用的特征: 未处理的连续特征 + Embedding(离散特征)
在Wide的基础上,增加Deep部分:
离散特征embedding之后,和连续特征串联。
# 3. The Deep Model: Neural Network with Embeddings
"""
1. Sparse Features -> Embedding vector -> 串联(Embedding vector, 连续特征) -> 输入到Hidden Layer
2. Embedding Values随机初始化
3. 另外一种处理离散特征的方法是:one-hot or multi-hot representation. 但是仅仅适用于维度较低的,embedding是更加通用的做法
4. embedding_column(embedding);indicator_column(multi-hot);
"""
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
# 对类别少的分类特征列做 one-hot 编码
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
# 事实上,这里只是为了作为演示用,embedding的长度一般会经验设置为 categories ** (0.25)
tf.feature_column.embedding_column(occupation, dimension=8)
]
组合Wide & Deep:DNNLinearCombinedClassifier
# 4. Combine Wide & Deep
model = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=base_columns + crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50]
)
训练 & 评估:
for n in range(train_epochs // epochs_per_eval):
model.train(input_fn=lambda: input_fn(train_file, epochs_per_eval, True, batch_size))
results = model.evaluate(input_fn=lambda: input_fn(
test_file, 1, False, batch_size
))
# Display Eval results
print("Results at epoch {0}".format((n+1) * epochs_per_eval))
print('-'*30)
for key in sorted(results):
print("{0:20}: {1:.4f}".format(key, results[key]))
运行结果:
Parsing ./data/adult.data
2018-12-21 15:35:49.183730: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
Parsing ./data/adult.test
Results at epoch 2
------------------------------
accuracy : 0.8439
accuracy_baseline : 0.7638
auc : 0.8916
auc_precision_recall: 0.7433
average_loss : 0.3431
global_step : 6516.0000
label/mean : 0.2362
loss : 13.6899
prediction/mean : 0.2274
Parsing ./data/adult.data
Parsing ./data/adult.test
Results at epoch 4
------------------------------
accuracy : 0.8529
accuracy_baseline : 0.7638
auc : 0.8970
auc_precision_recall: 0.7583
average_loss : 0.3335
global_step : 8145.0000
label/mean : 0.2362
loss : 13.3099
prediction/mean : 0.2345
Parsing ./data/adult.data
Parsing ./data/adult.test
Results at epoch 6
------------------------------
accuracy : 0.8540
accuracy_baseline : 0.7638
auc : 0.8994
auc_precision_recall: 0.7623
average_loss : 0.3297
global_step : 9774.0000
label/mean : 0.2362
loss : 13.1567
prediction/mean : 0.2398
Process finished with exit code 0
参考文献
- Wide & Deep Learning for Recommender Systems
- Google AI Blog Wide & Deep Learning: Better Together with TensorFlow https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html
- TensorFlow Linear Model Tutorialhttps://www.tensorflow.org/tutorials/wide
- TensorFlow Wide & Deep Learning Tutorialhttps://www.tensorflow.org/tutorials/wide_and_deep
- TensorFlow 数据集和估算器介绍 http://developers.googleblog.cn/2017/09/tensorflow.html
- absl https://github.com/abseil/abseil-py/blob/master/smoke_tests/sample_app.py
- Wide & Deep 理论与实践
- Wide & Deep Learning for Recommender Systems 论文阅读总结