端到端文本识别CRNN论文解读
CRNN 论文: An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
CRNN不定长中文识别项目下载地址: https://download.csdn.net/download/dcrmg/10248818
CRNN是一种卷积循环神经网络结构,用于解决基于图像的序列识别问题,特别是场景文字识别问题。CRNN网络结构:

网络结构包含三部分,从下到上依次为:
1. 卷积层,作用是从输入图像中提取特征序列;2. 循环层,作用是预测从卷积层获取的特征序列的标签(真实值)分布;
3. 转录层,作用是把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果;
卷积层
CRNN卷积层由标准的CNN模型中的卷积层和最大池化层组成,自动提取出输入图像的特征序列。
与普通CNN网络不同的是,CRNN在训练之前,先把输入图像缩放到相同高度(图像宽度维持原样),论文中使用的高度值是32。
提取的特征序列中的向量是从特征图上从左到右按照顺序生成的,每个特征向量表示了图像上一定宽度上的特征,论文中使用的这个宽度是1,就是单个像素。

特别强调序列的顺序是因为在之后的循环层中,先后顺序是LSTM训练中的一个重要参考量。
循环层
循环层由一个双向LSTM循环神经网络构成,预测特征序列中的每一个特征向量的标签分布(真实结果的概率列表),循环层的误差被反向传播,最后会转换成特征序列,再把特征序列反馈到卷积层,这个转换操作由论文中定义的“Map-to-Sequence”自定义网络层完成,作为卷积层和循环层之间连接的桥梁。
转录层
转录是将LSTM网络预测的特征序列的所有可能的结果进行整合,转换为最终结果的过程。论文中实在双向LSTM网络的最后连接上一个CTC模型,做到端对端的识别。
CTC模型(Connectionist temporal classification) 联接时间分类,CTC可以执行端到端的训练,不要求训练数据对齐和一一标注,直接输出不定长的序列结果。
CTC一般连接在RNN网络的最后一层用于序列学习和训练。对于一段长度为T的序列来说,每个样本点t(t远大于T)在RNN网络的最后一层都会输出一个softmax向量,表示该样本点的预测概率,所有样本点的这些概率传输给CTC模型后,输出最可能的标签,再经过去除空格(blank)和去重操作,就可以得到最终的序列标签。网络结构简图:
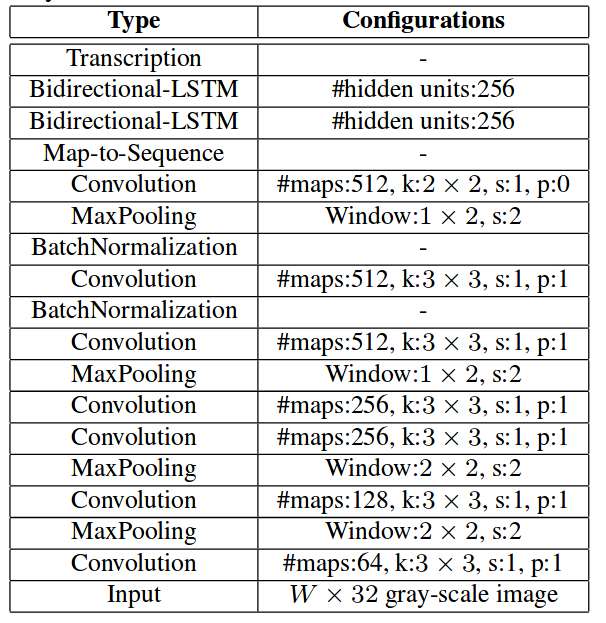
网络结构Keras定义:
def get_model(height,nclass):
input = Input(shape=(height,None,1),name='the_input')
m = Conv2D(64,kernel_size=(3,3),activation='relu',padding='same',name='conv1')(input)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool1')(m)
m = Conv2D(128,kernel_size=(3,3),activation='relu',padding='same',name='conv2')(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,2),name='pool2')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv3')(m)
m = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same',name='conv4')(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool3')(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv5')(m)
m = BatchNormalization(axis=1)(m)
m = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same',name='conv6')(m)
m = BatchNormalization(axis=1)(m)
m = ZeroPadding2D(padding=(0,1))(m)
m = MaxPooling2D(pool_size=(2,2),strides=(2,1),padding='valid',name='pool4')(m)
m = Conv2D(512,kernel_size=(2,2),activation='relu',padding='valid',name='conv7')(m)
m = Permute((2,1,3),name='permute')(m)
m = TimeDistributed(Flatten(),name='timedistrib')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm1')(m)
m = Dense(rnnunit,name='blstm1_out',activation='linear')(m)
m = Bidirectional(GRU(rnnunit,return_sequences=True),name='blstm2')(m)
y_pred = Dense(nclass,name='blstm2_out',activation='softmax')(m)
basemodel = Model(inputs=input,outputs=y_pred)
labels = Input(name='the_labels', shape=[None,], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model = Model(inputs=[input, labels, input_length, label_length], outputs=[loss_out])
# sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)
sgd = SGD(lr=0.0003, decay=1e-6, momentum=0.6, nesterov=True, clipnorm=5)
#model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer='adadelta')
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=sgd)
model.summary()
return model,basemodel