RCNN:Rich feature hierarchies for accurate object detection and semantic segmentation 阅读笔记
Rich feature hierarchies for accurate object detection and semantic segmentation

0. 简介
本文是CVPR2014的论文,在这之前检测最好的方法结合了low-level 图像特征与high-level context信息作为图像特征;与此同时AlexNet在ImageNet图像分类任务中超越了人工特征的方法,体现了卷积神经网络的强大能力。那CNN在图像分类任务中的优势是否可以泛化到检测任务中呢?如果可以表现如何?为了回答这些问题,文中设计了一种简单的图像检测算法RCNN,在 VOC 2012 达到了53.3%的mAP值,超越了之前最好算法的30%。RCNN融合了两个关键的insight:
- 将高容量的CNN应用到image proposals 中来完成定位,分割任务是可行的;
- 如果有标注数据量不够,预训练之后在特定的问题中进行fine-tuning可以显著的提高performance。
利用CNN完成检测任务面临的两个问题:
如何利用CNN来定位物体:直接将定位建模为一个坐标回归问题,当时已有的结果显示这样做的效果不好(30.5%mAP);利用滑动窗口方法中,高层神经元的感受野与对应到输入图像的stride过大,作者指出利用滑动窗口做精确定位是个具有挑战性的问题。文中利用了“recognition using regions” paradigm,先将图像中生成2000个左右的category-independent region proposal,affine image warping后利用cnn提取propocal 固定维度的特征丢入线性svm进行分类。
现有的有标注数据稀少不足以训练高容量CNN 作者指出通过在一个较大的数据集中做有监督预训练(对比之前的无监督预训练),然后在特定问题的小数据集上做fine-tuning是一个非常有效的方法。文中指出在RCNN中fine-tuning可以提高8个百分点mAP(这里不应该说预训练带来多少提升吗????)。
mAP 首先对于每个类别计算P-R曲线,那么AP(Average Precision)就是P-R曲线的下面积,那么mAP(mean Average Precision)就是对所有类别的平均。
IoU表示了bounding box 与 ground truth 的重叠度,如下图(http://blog.csdn.net/zhang_shuai12/article/details/52716952)所示:
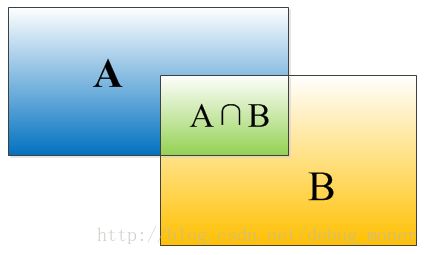
IOU=(A∩B)/(A∪B) I O U = ( A ∩ B ) / ( A ∪ B )
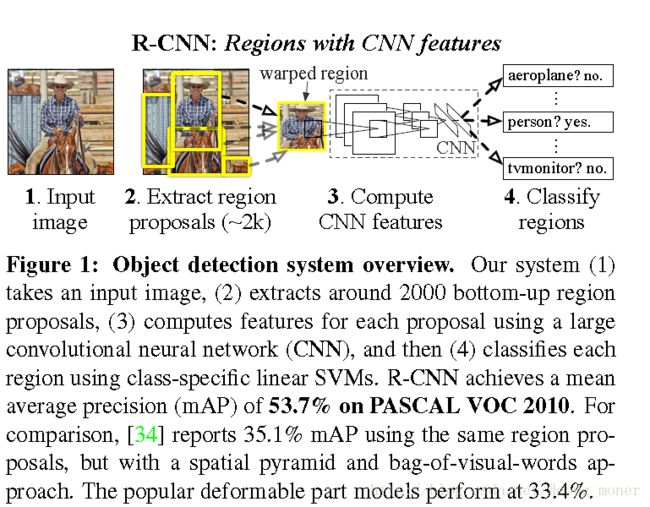
RCNN图例,接下来具体介绍其中的每一个步骤。
1.模型设计
Region proposals产生 region proposals的方法种类很多,为了方便与其他方法对比,作者选择了selective search[pdf][ss 参考链接] and [pythoncode]:
Selective Search is a region proposal algorithm used in object detection. It is designed to be fast with a very high recall. It is based on computing hierarchical grouping of similar regions based on color, texture, size and shape compatibility.
ss是一种速度快,召回率非常高的 region proposal 算法,主要通过计算regions间的颜色,文理,大小,形状的相似度来完成hierarchical grouping得到的。
Feature extraction: 文中采用 AlexNet结构(输入227*227,fc7维度4096),为了让region proposal的尺寸适应网络结构大小,作者试验了不同的方法:

各向异性缩放这种方法很简单,就是不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到CNN输入的大小227*227,如上图(D)所示;
各向同性缩放因为图片扭曲后,估计会对后续CNN的训练精度有影响,于是作者也测试了“各向同性缩放”方案。这个有两种办法:
- 直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如图(B)所示;
- 先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如下图(C)所示;
对于上面的异性、同性缩放,文献还有个padding处理,上面的示意图中第1、3行就是结合了padding=0,第2、4行结果图采用padding=16的结果。经过最后的试验,作者发现采用各向异性缩放、padding=16的精度最高。
上面处理完后,可以得到指定大小的patch,因为后面还要继续用这2000个候选框图片,训练CNN得到特定层的feature,对于每个class,训练线性SVM得到每个proposal的得分,最终在图像中利用非极大值抑制来去除一些框。这样的框架在特征维度数目,存储空间,预测时间相对于之前的方法都有很大的优势。
2. CNN训练
有监督预训练 作者首先在ILSVRC 2012中训练了AlexNet,结果基本与论文中的结果差不多。
Domain-specific fine-tuning首先 ILSVRC2012中有1000个类别,而VOC中是20个类别,首先将AlexNet中的最后一个1000units的层替换会只有21个的(多了背景一类),并且随机初始化这一层。对于数据标定,如果一个region proposal与某一个类别的ground true 标定框IoU>0.5,就标定这个proposal为这一类别的正样本,如果与任何一类的ground true IoU都<0。5,标记为背景。 利用0.001的SGD进行训练,batchsize为128(32positive &96background,正样本相对太少了)
训练分类器SVM训练过程中,正样本为ground true,也就是数据集中的标定,对于background,作者通过grid search 方法,发现把其定义为与ground true IoU<0.3结果最好。在实现中利用了hard negative mining方法来降低占用的存储空间。
这里fine-tuning 与训练svm正负样本定义不同:
for finetuning we map each object proposal to the ground-truth instance with which it has maximum IoU overlap (if any) and label it as a positive for the matched ground-truth class if the IoU is at least 0.5. All other proposals are labeled “background” (i.e., negative examples for all classes). For training SVMs, in contrast, we take only the ground-truth boxes as positive examples for their respective classes and label proposals with less than 0.3 IoU overlap with all instances of a class as a negative for that class. Proposals that fall into the grey zone (more than 0.3 IoU overlap, but are not ground truth) are ignored.
作者在补充材料里说明,现在这样的定义得到的结果最好,在fine tuning的时候可以扩充正样本数据量,对于训练整个网络并防止其过拟合是必要的。同时 fine tuning的目标并不是精确的定位,所以这样做是合理的。这也能解释作者为何要不直接把一个softmax 分类器接在网络的最后,这样做的结果不够精细(因为数据标定不精细)同时训练的也不是hard negatives。但是如果能够解决掉这个gap的话,会加速RCNN。
Bounding box regression:对于一组训练数据(pair):
P代表proposal,G代表ground truth,四个值分别是中心点坐标(x,y),宽w,高h,Bounding box 回归要学习四个函数,
利用这四个函数把一个proposal映射到一个Ground truth:
ϕ5(P) ϕ 5 ( P ) 对应proposal经过神经网络的pool5特征,最终的优化问题:
也就是通过Pooling5层特征的一个线性变换来学习proposal与gound true之间的误差,是一个标准的ridge 回归,其中正则项系数为1000,是作者在验证集合上选出来的,其实它与feature的量级有很大关系没做实验的话好奇也没用,最后一个问题是训练数据对怎么选,文中把足够靠近的P与G归为一个训练对是比较合适的,只有P与所有G的最大Iou>0.6,才会把对应的P与G当做训练对,把不满足的P都丢弃掉。实现的时候,每个类别都这样做一次,category-specific
3.实验

在VOC2010的结果显示RCNN大幅度提升了detection的效果。而且相对其他方法,速度也更快。
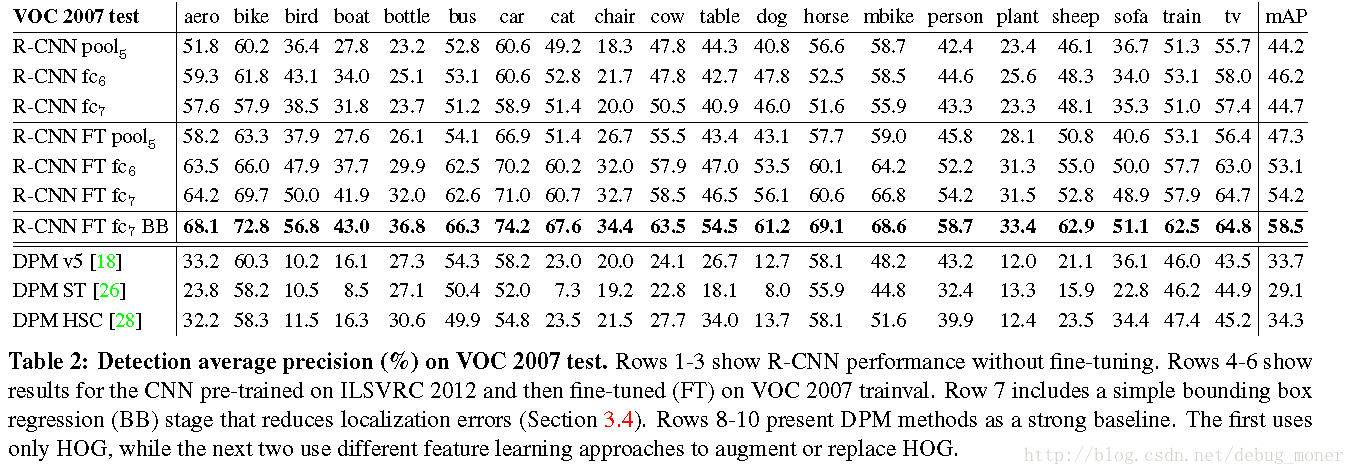
作者在VOC2007中做了一系列的实验,首先在不fine tuning的情况下,把CNN作为一个特征提取器,作者发现:
- fc7效果没有fc6特征得到的结果好,同时直接用pool5的特征结果也是非常不错的,也就是CNN只需要少量的参数就可以达到非常好的效果,作者总结网络的表达能力主要是卷积层部分提供的。
- 可以把利用CNN提取的特征结合滑动窗口框架进行detection。
图中的FT表示Fine Tuning,可以看出,经过FT之后深度增加效果会更好。相比于without FT的结果有大幅度提升,所以FT是很重要的一部。也可以看出Bounding box回归带来的增益也是很大的。
文中还做了分割任务的比较,超过当时已有算法不过并没有大幅度提升效果。
4.总结
RCNN主要贡献证明了CNN在目标检测与分割同样有强大的潜力,同时提出一种新的目标检测的框架。