(九)Spark学习笔记之Spark on Yarn
文章目录
- Spark on yarn
- Spark on yarn 的配置
- 资源分配
- CPU资源
- 内存资源
- 分配资源
- 资源分配的限制
- 提交模式
- Client模式下的 AM,Driver 资源分配
- Cluster 模式下 AM,Driver 分配的资源
- executor 的资源分配
Spark on yarn
Spark 支持可插拔的集群管理器(standalone,yarn),集群管理器负责启动 executor 进程。Spark 支持四种集群管理器模式:standalone,mesos,yarn,kubernets。前三种集群模式是由两个组件组成:master 和 slave。Master 服务(YARN ResourceManager, Mesos master,spark standalone master)决定应用程序 application 的运行情况:是否可以运行、何时运行、和在哪运行等。而 slave(YARN NodeManager,Mesos slave 和Spark standalone worker)是运行 executor 进程的。
注:
standalone:独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
Spark on yarn:Spark 使用了 yarn 管理器。Spark 运行在 YARN 上时,不需要启动 Spark 集群,只需要启动 YARN 即可!! YARN 的 ResourceManager 相当于 Spark Standalone 模式下的 Master。
在 Yarn 上运行 Spark 作业时,每个 Spark executor 作为一个 YARN 容器(container)运行。Spark 应用程序的多个 task 在同一个容器(container)中运行。
standalone 和 spark on yarn 有两种提交方式:
client:Driver 运行在和 spark 同一个级进程中,如果关闭命令行窗口,相当于取消了程序的运行。可以从控制台看到程序输出的内容。
cluster:Driver 运行在 worker 节点(standalone)/ ApplicationMaster(yarn)进程中,如果提交后即退出,此时命令行窗口关闭,但不影响程序的运行,但是从控制台上看不到程序的输出内容。
Spark on yarn 的配置
spark on yarn 不需要启动 spark 集群,只需要启动 YARN 即可。但是需要配置
- 在 etc/profile 中配置 spark 的环境变量:SPARK_HOME。
- 在 spark-env.sh 文件中配置 HADOOP_CONF_DIR=/opt/hadoopXXX/etc/hadoop,关联 hadoop 的配置目录。
提交命令
./spark-submit
--class sparkcore.learnTextFile
--master yarn-cluster /opt/sparkapp/learnTextFile3.jar
查看输出:
yarn logs -applicationId application_1535409703247_0006
查看任务运行状态:
yarn application -status application_1469094096026_26612
资源分配
CPU资源
spark 计算的关键抽象是 RDD,RDD 包括多个 partition,一个 partition 对应一个 task,对应一个 CPU core。一个 spark Job 的并行度依赖于 RDD 的 partitions 和可用的 CPU cores。
内存资源
spark 内存主要用于执行 job 和存储数据。执行内存(shuffle)的数据可以驱逐存储内存(storage)的数据,而存储内存的数据不可以驱逐执行内存数据。
- 执行内存主要用于 shuffle,join,sort 等操作。
- 存储内存用于缓存数据和集群内传播数据。
分配资源
当 spark 应用运行在 yarn 上,对于 yarn 而言,Spark 应用仅是一个应用,就像 MapReduce 应用一样,只是一个运行在 yarn 上的应用。
- ResourceManager: 管理集群资源;
- ApplicationMaster:负责从 ResourceManager 请求资源,进而将资源分配给每个集群节点上的 NodeManager。这样集群就可以执行 task 任务了。
Application 是属于某个特定 Application 的,执行 MapReduce 应用时,yarn 使用了MapReduce 框架特定的 Applicationmaster,当执行 Spark job 时,yarn 使用了 Spark 框架特定的 ApplicationMaster(运行yarn就使用了MR的AM,运行spark,就是用了spark的AM)。
Yarn 通过逻辑抽象单元 Container 来分配资源,Container 代表一个资源集 ---- CPU 和内存。当 Spark ApplicationMaster 从 ResourceManager 请求资源时,通过评估 job 的资源需求,然后请求一定数量的 Container 来完成 Job。基于集群可用资源,ApplicationMaster 会要求 worker 节点上的 NodeManager 运行一定数量 Container。
当运行 Spark on yarn 应用时,spark 位于 yarn 之上,使用相同的过程请求资源,yarn 用相同的方式将 container 分配给 spark Job,spark 所有的 executor 和 driver 都运行在 container 中。ApplicationMaster 负责 container 间的通信。
ApplicationMaster 运行在一个单独的 container 中,executor 也运行在 yarn container 中,一个 executor 运行在一个 container 中。在 MapReduce 应用资源分配过程中,一个 map/reduce task 运行在单独的 container 中,但是 Spark executor 中,Executor container 包含一个更细粒度的实体 — task。每个 Executor 可以运行一个 task 集合,来完成实际任务。Spark 使用了 YARN 管理的两个关键资源:CPU 和内存。虽然磁盘 IO 和网络对应用程序性能有影响,但是 YARN 并不是真正关注磁盘 IO 和网络。
资源分配的限制
可以配置 YARN 属性参数来限制 YARN 可以使用的最大内存和 CPU core。Spark 的资源使用受限于这些配置属性。
yarn.nodemanager.resouce.memory-mb
该参数设置了分配集群中一个运行 NodeManager 节点上所有 container 的内存上限。此内存设置对 spark on yarn 同样有效。
yarn.nodemanager.resouce.cpu-vcores
该参数设置了集群中一个运行 NodeManager 节点上所有 containers 可以使用的最大 CPU 核心数。
- yarn 以块的形式分配内存,内存块大小依赖于参数 yarn.scheduler.minimum-allocation-mb :yarn 可以为每个 container 请求分配的最小内存块大小。
- yarn 以 core 的形式分配 CPU,core 的个数依赖参数 yarn.scheduler.minimum.allocation-vcores : yarn 可以为每个 container 请求分配的最小 CPU core 数。
提交模式
YARN-CLIENT
spark Driver 运行在客户端 Client 进程中,YARN ApplicationMaster 进程代表向 YARN 请求资源。
Client 向 yarn 的 RM 申请 container,用于运行 AM,RM 在 NodeManager 上启动 container运行 AM,SparkContext 在 Client 端实例化,通知 AM,申请资源,AM 向 RM 申请资源,AM 在 NodeManager上 启动 container(executor),sparkContext 分配 task 给 executor,executor 启动线程池执行,运行完成后,driver 通知 RM 回收资源。
YARN-CLUSTER
spark driver 运行在 yarn 管理的 ApplicationMaster 进程中: client 将定期轮询 AM 以获取状态更新,并在控制台显示它们。一旦应用程序运行完毕,client 退出。
client 向 yarn 的 RM 请求 container,用于运行 AM,RM 在 NodeManager 上启动 container 运行 AM,AM 会实例化 SparkContext(driver),AM 向 RM 申请资源,AM 在 NodeManager 上启动 container(executor),sparkContext 分配 task 给 executor, executor 启动线程池执行,运行完成后,driver 通知 RM 回收资源。
spark on yarn 应用程序的 driver 职责:
- 使用 spark 执行引擎,将应用程序分成 jobs,stages 和 tasks;
- 为 executor 进程提供包依赖服务;
- 与 yarn ResourceManager 交互,获取资源,分配给各个节点用于执行应用程序的 task。
一旦 driver 获取资源执行 spark Application, 其会创建一个执行计划:根据应用程序代码中的 action 和 transformation 生成一个有向无环图 DAG,并发送给 worker 节点。
driver 进程包括有两个组件。用来处理 task 分配:
- DAGSchedule 进程将 DAG 划分为 task。
- TaskSchedule 在集群各个节点间调度 task,一旦 TaskSchedule 完成了 task 分配, executor 开始执行 DAG 中的操作。如果 task 失败或者出现延迟,TaskSchedule 会重启失败的 task 或创建先 task 来替换延迟的 task。
Client模式下的 AM,Driver 资源分配
spark on yarn 模式,spark 应用程序对应的 AM 资源分配依赖于两个配置参数
| 参数配置 | 参数描述 | 默认值 | 案例 |
|---|---|---|---|
| spark.yarn.am.memory | AM 的 JVM 堆内存 | 512m | spark.yarn,am.memory 777m |
| spark.yarn,am.cores | AM 的可用 core 数量 | 1 | spark.yarn.cotes 4 |
由于 yarn 分配资源的单位是 container,那么 AM 运行所在的 container 的大小使用参数spark.yarn.am.memory 来设置。
在 Client 模式下,spark 为 AM 进程分配了一个一定量的堆外内存,配置参数为 spark.yarn.am.memoryOverhead 设置了堆外内存的大小。其默认值大小为 AM memory * 0.1 ,但是其最小值为 384m。
那么如果 AM 内存 spark.yarn.am.memory 设置为 777m,那么 777m * 0.1 = 77m <384m,所有堆外内存就是最小值 384m。AM container 的大小即为 777m + 384m = 1161m > 1024m,即为 AM 分配的内存大小应该是 2G,
Cluster 模式下 AM,Driver 分配的资源
在 cluster 模式下,spark driver 运行在 yarn ApplicationMaster 进程中。所以,分配给 Am 的资源决定了 driver 的可用资源。
| 配置参数 | 参数描述 | 默认值 | 案例 |
|---|---|---|---|
| spark.driver.cores | AM 可用的 core 数量 | 1 | spark.driver.cores 2 |
| spark.driver.memory | AM 的 JVM 堆内存 | 512m | spark.driver.memory 11665m |
| spark.driver.memoryOverhead | Driver 堆外内存 | driverMemory * 0.1 >= 384m |
spark.driver.memoryOverhead 用于指定 cluster 模式下的堆外存大小。该属性默认值为分配给 ApplicationMaster 内存的 10%, 最小值为 384M。
在 cluster 模式中,当你配置 spark driver 的资源时,间接配置了 yarn AM 服务的资源,因为 driver 运行在 AM 中。
因为 1665+Max(384,1665*0.10)=1665+384=2049 > 2048(2G), 并且yarn.scheduler.minimum-allocation-mb=1024,所以 container 大小为:3GB 内存
executor 的资源分配
spark 任务的真正执行的是在 worker 节点上,也就是说所有的 task 运行在 worker 节点。spark job 的大部分资源应该分配给 executor,相比而言,driver 的资源分配要小的多。
对于 spark executor 资源,yarn-client 和 yarn-cluster 模式使用相同的配置。
| 配置参数 | 参数描述 | 默认值 | 对应 |
|---|---|---|---|
| spark.executor.instances | 用于静态分配 executor 的数量 | 2 | –num-executors |
| spark.executor.cores | 单个 executor 的 core 数量 | 1 | –executor-cores |
| spark.executor.memory | 每个 executor 的堆内存大小 | 1G | –executor-memory |
| spark.executor.memoryOverhead | 每个 executor 的堆外存大小 | executorMemory * 0.1 > 384m |
如果设置 spark.executor.memory 大小为 2G,那么将启动 2 个 container,大小为 3G,1core,-Xmx2048M 。
在 Spark 资源分配表述中,Executor 是 container 的同义词—即一个Executor,一个container。因此,Spark 的 Executor 的分配转换成了 yarn 的 container 的分配。当 Spark 计算出所需要的 Executor 数量,其与 AM 交互,AM 进而与 YARN RM 交互,请求分配 container。
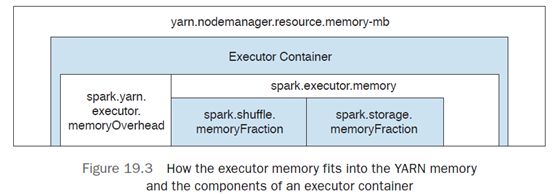
spark.executor.memory 参数设置会影响下面两个地方:
- Spark 可以缓存的数据量;
- shuffle 操作可以使用的内存最大值
图展示了 spark executor 内存与 yarn 总内存 yarn.nodemanager.resource.memory-mb 的关系:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
lib/spark-examples*.jar \
10