(五)Spark学习笔记之广播&累加器
文章目录
- spark 共享变量实战
- 广播变量 Broadcast Variables
- 累加器(Accumulator)
spark 共享变量实战
通常,spark 程序计算的时候,传递的函数是在远程集群节点上执行的,在函数中使用的所有变量副本会传递到远程节点,计算任务使用变量副本进行计算。这些变量被复制到每台机器上,对远程机器上的变量的更新不会返回到 driver 程序。
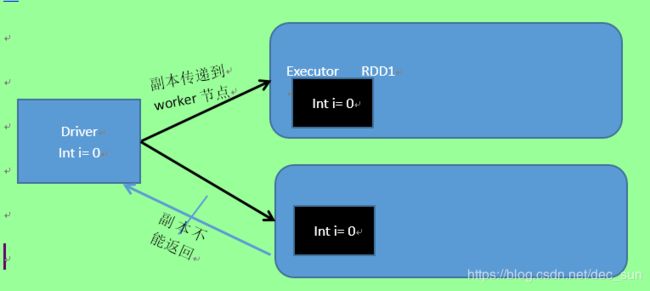
因此,跨任务支持通用的读写共享将是低效的。但是,spark 为两种常见的使用模式提供了两种有限功能的共享变量:广播变变量和累加器。
广播变量 Broadcast Variables
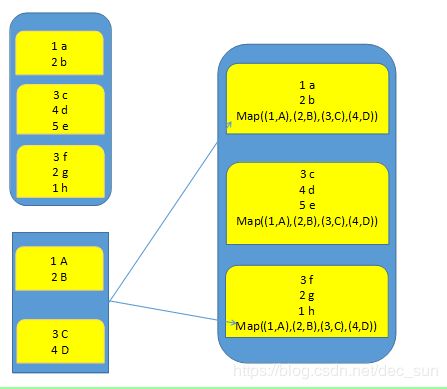
广播变量允许 spark 程序将只读变量缓存在每个节点上,而不是将它的副本与 task 一起发送出去。例如,可以使用广播变量以高效的方式为每个 worker 节点提供一个大型输入数据集的副本。广播变量是只读变量,对每个 worker 节点只需要传输一次。这样,就可以从每个 task 的变量副本变成 executor 的变量副本。executor 中的所有 task 共享这个副本。如果有多个 worker 节点,各个 worker 节点上的 executor 中的变量副本并不都是来自 driver,因为 spark 采用了高效的广播变量副本算法(TorrentBroadcast)来分配广播变量,以降低通信成本。
广播变量不可以广播 RDD,只能广播变量。并且广播变量副本只是一个可读变量,是不可以修改的。
val list1 = List(("zhangsan",20),("lisi",33),("wangwu",26))
val list2 = List(("zhangsan","spark"),("lisi","kafka"),("wangwu","hive"))
val rdd1 = sc.parallelize(list1)
val rdd2 = sc.parallelize(list2)
val rdd1Data = rdd1.collectAsMap()
val rdd1BC = sc.broadcast(rdd1Data)
val rdd3 = rdd2.mapPartitions(partition => {
val bc = rdd1BC.value //广播的变量
for (
(key, value) <- partition
if (bc.contains(key))
)yield (key, (bc.get(key).getOrElse(""), value))
})
rdd3.foreach(t => println("rdd3 = "+t._1+":"+t._2._1+":"+t._2._2))
rdd3.foreach(println)
累加器(Accumulator)
累加器是只能累加的变量。在 task 中只能对累加器进行添加数值,而不能获取累加器的值。累加器的值只能在 driver 端获取。
累加器支持加法交换律和结合律,因此可以有效地支持 spark task 的并行计算。
累加器可用于 spark 任务计数场景或者 spark 任务求和场景。spark 内置了几种累加器,并支持自定义累加器。作为 spark 开发工程师,可以创建命名的或者未命名的累加器。如图所示,一个命名累加器显示在修改该累加器的 stage web ui 中。这里有一个 Accumulators 的列。
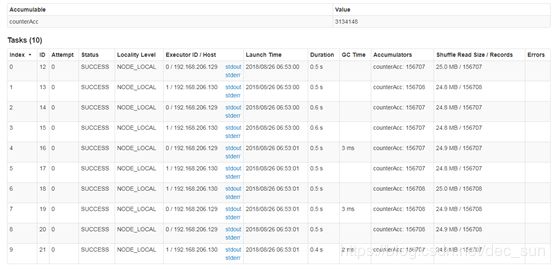
在使用累加器时,可以会遇到很多陷阱
- 由于执行一次 action,会执行一次累加器。所以如果程序中有多个 action 来执行,会多次累次运行累加器导致结果错误。
- task 缓存数据被清理后,到下次再运行时,会重新计算,此时累加器会重复累加计算。
- task 数据被缓存后,累加器的数值也一并会被缓存。如果再出现一个 action,将导致累加器在之前的基础上进一步累加。
从上述陷阱可以理解,每次出现 action 时,executor 都是从头开始计算。而不是根据代码的位置来根据之前的代码来处理。如果有缓存,那么就是从缓存处开始处理,那么就可以不再重新开始计算了,也就提高了系统计算的性能,减少了一定的计算时间。
在实际项目中,累加器主要用于程序调试。
val list1 = List(("zhangsan",20),("lisi",33),("wangwu",26))
val list2 = List(("zhangsan","spark"),("lisi","kafka"),("wangwu","hive"))
val rdd1 = sc.parallelize(list1)
val rdd2 = sc.parallelize(list2)
val textFile = sc.textFile("in/README.md")
val acc = sc.longAccumulator("counterAcc")
val mapRDD = textFile.map(line => {
acc.add(1)
(line, line.size)
})
mapRDD.cache() //缓存处理, 保证acc的数据再次执行时初始化为初始值,因为缓存也会保存acc的数值。
val count = mapRDD.count()
println("count= "+count)
println("acc.value=" +acc.value)
val count2 = mapRDD.count() //如果没有上面的缓存,那么累加器将在上一个count的基础上再次累加,那么其结果将是希望值的2倍。
println("count2= "+count2)
println("acc.value=" +acc.value)
综述:
广播变量一般用于 spark 程序的调优,如果不使用广播变量,不会导致计算结果出现错误,只会导致性能降低。同时广播变量是广播的变量而不是RDD。
累加器不同,如果应该使用累加器的场景而不使用,将导致程序计算结果报错。