VOT, OTB——目标追踪的发展概况
先说两个目标追踪的评价标准: VOT 和 OTB 。
其中,OTB 的论文见下面链接:
Online object tracking: A benchmark
Object tracking benchmark [J]. TPAMI, 2015
上面两篇文章是做什么的呢?它是用一个标准来评价已经存在的目标追踪算法的性能。来看下图:
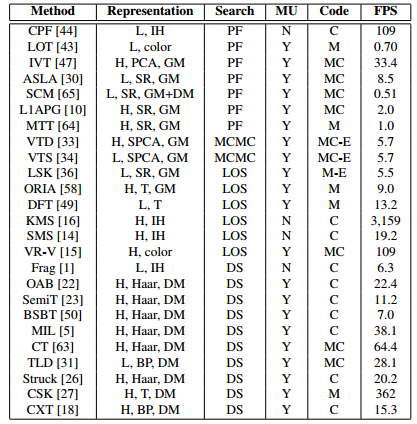

VOT 相关论文见下面链接,包含了 2013、2014、2015、2016年的
The visual object tracking vot2013 challenge results
The Visual Object Tracking VOT2014 Challenge
ResultsThe visual object tracking vot2015 challenge results
The Visual Object Tracking VOT2016 Challenge Results
如果想了解目标追踪算法的进展,请持续关注 VOT 挑战赛。这两个数据集的评价标准是不同的。首先,OTB 的数据集是完全公开的,因此,很多只跑 OTB 的追踪算法,很大程度上对着这个数据集调参,所以,迷惑性还是比较大的。而 VOT 数据集,每年都会变化,因此,对挑战者的算法的适应性要求更高。从这个角度上来说, VOT 挑战赛的排名,还是比较靠谱的。
从数据库的标准来看,有三个不同之处:
(1)VOT 都是彩色图像,OTB 有四分之一的灰度图,这也造成了一些以颜色作为特征的算法性能的差异;VOT 数据集的图像分辨率普遍更高
(2)VOT 初始化是从第一帧开始的,而OTB 是从随机帧开始,或者矩形框加上随机干扰去初始化,作者认为这样更符合检测算法给出的框架;
(3)VOT 是基于 shory-term 的,而 OTB 是 long-term 的。什么是 long-term 呢?其实就是说,在使用矩形框初始化目标的时候,如果跟丢了,可以使用目标检测等手段重新初始化该目标。而 OTB 提出的 short-term ,如果目标框漂移走了,就代表跟踪失败了,不能再重新检测了。
追踪算法的介绍,分两个时间点介绍 —— 2012年之前、2012年之后。
2012年之前:
主要有生成类的方法:卡尔曼滤波、camshift 等,现在回头看,这些算法在目标跟踪领域的表现是非常糟糕的。但是在当时,类似的方法好像还很厉害的样子。在此,不赘述了。而经典的判别类的方法,主要代表作有 Struck 和 TLD ,都能勉强达到实时,效果还说的过去。Struck 可以说是 2012 年之前,最好的跟踪算法,TLD 是 long-term 的典型代表,主要因为 TLD 包含了三个模块:检测模块、跟踪模块、学习模块。在此,也不多说了。
2012年以后:
1、相关滤波方向
相关滤波应用于目标跟踪,早就不是新鲜事了。但是,2010 年的一篇论文 MOSSE ,第一次彰显了相关滤波的强大之处。615 FPS。详细论文可以参考我的博客:
MOSSE 论文翻译,该算法取的是单通道灰度特征。
后来,牛津大学的大神 Joao F.Henriques 相继发表 CSK(362 fps) 和 KCF(172fps),核心部分是岭回归、循环位移的近似采样、还有岭回归加 kernel-trick 的封闭解。
和KCF 同一时期的,还有一个 CN 算法(Color Name),该算法基于颜色特征,在2014 CVPR 上 引起了巨大的反响。其实这种方法也是基于 CSK 的多通道颜色特征改进算法——Coloring Visual Tracking 。
总结一下:
(1)MOSSE是单通道灰度特征的相关滤波,CSK在MOSSE的基础上扩展了密集采样(加padding)和kernel-trick,KCF在CSK的基础上扩展了多通道梯度的HOG特征,CN在CSK的基础上扩展了多通道颜色的Color Names。HOG是梯度特征,而CN是颜色特征,两者可以互补,所以HOG+CN在近两年的跟踪算法中成为了hand-craft特征标配。
(2)MOSSE(615 fps)-->CSK(362 fps)-->KCF(172 fps)-->DCF(292 fps)-->CN(152 fps)->CN2(202 fps)效果越来越好了。
以下两个段落转载于:链接:https://www.zhihu.com/question/26493945/answer/156025576
根据KCF/DCF的实验结果,讨论两个问题:
1. 为什么只用单通道灰度特征的KCF和用了多通道HOG特征的KCF速度差异很小?
第一,作者用了HOG的快速算法fHOG,来自Piotr's Computer Vision Matlab Toolbox,C代码而且做了SSE优化。如对fHOG有疑问,请参考论文Object Detection with Discriminatively Trained Part Based Models第12页。第二,HOG特征常用cell size是4,这就意味着,100*100的图像,HOG特征图的维度只有25*25,而Raw pixels是灰度图归一化,维度依然是100*100,我们简单算一下:27通道HOG特征的复杂度是27*625*log(625)=47180,单通道灰度特征的复杂度是10000*log(10000)=40000,理论上也差不多,符合表格。看代码会发现,作者在扩展后目标区域面积较大时,会先对提取到的图像块做因子2的下采样到50*50,这样复杂度就变成了2500*log(2500)=8495,下降了非常多。那你可能会想,如果下采样再多一点,复杂度就更低了,但这是以牺牲跟踪精度为代价的,再举个例子,如果图像块面积为200*200,先下采样到100*100,再提取HOG特征,分辨率降到了25*25,这就意味着响应图的分辨率也是25*25,也就是说,响应图每位移1个像素,原始图像中跟踪框要移动8个像素,这样就降低了跟踪精度。在精度要求不高时,完全可以稍微牺牲下精度提高帧率(但看起来真的不能再下采样了)。
2. HOG特征的KCF和DCF哪个更好?
大部分人都会认为KCF效果超过DCF,而且各属性的准确度都在DCF之上,然而,如果换个角度来看,以DCF为基准,再来看加了kernel-trick的KCF,mean precision仅提高了0.4%,而FPS下降了41%,这么看是不是挺惊讶的呢?除了图像块像素总数,KCF的复杂度还主要和kernel-trick相关。所以,下文中的CF方法如果没有kernel-trick,就简称基于DCF,如果加了kernel-trick,就简称基于KCF(剧透基本各占一半)。当然这里的CN也有kernel-trick,但请注意,这是Martin Danelljan大神第一次使用kernel-trick,也是最后一次。。。这就会引发一个疑问,kernel-trick这么强大的东西,怎么才提高这么点?这里就不得不提到Winsty的另一篇大作:Wang N, Shi J, Yeung D Y, et al. Understanding and diagnosing visual tracking systems[C]// ICCV, 2015. 一句话总结,别看那些五花八门的机器学习方法,那都是虚的,目标跟踪算法中特征才是最重要的(就是因为这篇文章我粉了WIN叔哈哈),以上就是最经典的三个高速算法,CSK, KCF/DCF和CN,推荐。
那么,基于以上这些算法,其它人都有哪些改进呢?
1、尺度问题
尺度变化是目标跟踪中常见的问题。而刚刚提到的 CSK、KCF、CN 等都没有尺度更新,如果目标缩小了,滤波器就会学到大量的背景信息,如果目标扩大,滤波器就随着目标的局部纹理走了,而这,都会导致跟踪失败。针对尺度变化,有两篇文章的工作很出色:
(1)Li Y, Zhu J. A scale adaptive kernel correlation filter tracker with feature integration [C]// ECCV, 2014
SAMF 算法,基于 HOG + CN 的 KCF算法的改进,它采用平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及其所在的尺度。
(2) Danelljan M, Häger G, Khan F, et al. Accurate scale estimation for robust visual tracking [C]// BMVC, 2014.
DSST算法,只使用了 HOG 特征,DCF 专门用于平移位置检测,并且,又专门训练了类似 MOSSE 的相关滤波器检测尺度变化,创造性地使用了平移滤波+尺度滤波。后来又整了一个加速的版本 fDSST,非常好。
Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. IEEE TPAMI, 2017.
那么,以上哪种方法更好呢?
对于普通的尺度变化,两种算法都跟得上。但是 DSST 算法有 33 个精尺度,而 SAMF 只有 7 个粗尺度。但是呢,SAMF 算法是平移和尺度一起检测,是两者同时最优。而DSST算法先检测最佳平移再检测最佳尺度,是分布最优。往往,局部最优并不是全局最优。换句话说,DSST算法将平移
2、深度学习方向: