【总结】推荐系统学习-LibMF
介绍
LibMF的作者是大名鼎鼎的台湾国立大学,他们在机器学习领域享有盛名,近年连续多届KDD Cup竞赛上均获得优异成绩,并曾连续多年获得冠军。业界常用的LibSVM, Liblinear等都是他们开发的,开源代码的效率和质量都非常高。
LibMF是在潜在空间使用两个矩阵,接近一个不完全矩阵。(原句是:LIBMF is an open source tool for approximating an incomplete matrix using the product of two matrices in a latent space.)
矩阵分解(MF)通常在推荐系统中使用。LibMF有如下特点:
1、providing solvers for real-valued matrix factorization, binary matrix factorization, and one-class matrix factorization(为实值矩阵分解,二元矩阵分解和一类矩阵分解提供解决办法)
2、parallel computation in a multi-core machine (多核机器中并行计算)
3、using CPU instructions (e.g., SSE) to accelerate vector operations(可使用CPU指令,比如SSE来加速向量运算)
taking less than 20 minutes to converge to a reasonable level on a data set of 1.7B ratings(在1.7B等级大小的数据上花不到20分钟来聚集到一个合理的级数)
4、cross validation for parameter selection(参数选择的交叉验证)
5、supporting disk-level training, which largely reduces the memory usage(支持磁盘级训练,大大减小内存使用)
编译
在Ubuntu14.04上进行。环境需要g++4.6及以上。
将下载的压缩文件上传至Ubuntu,解压。
进入目录,输入“make”进行编译。
编译后可看到这些文件

数据格式
在demo目录中,文件real_matrix.tr.txt' 和 `real_matrix.te.txt'是真值矩阵分解real-valued matrix factorization (RVMF)演示的训练和测试数据集。二元矩阵分解binary matrix factorization (BMF)中,`binary_matrix.tr.txt' 和`binary_matrix.te.txt.'中
模型格式
LibMF把一个训练矩阵R变为一个k-by-m的矩阵 `P'和一个k-by-n的矩阵 `Q',也就是R近似于 P'Q。训练过程结束后,这两个因子矩阵P和Q被存到一个模型文件中。这个文件以如下打头:
`f': the loss function of the solved MF problem
`m': the number of rows in the training matrix,
`n': the number of columns in the training matrix,
`k': the number of latent factors,
`b': the average of all elements in the training matrix.
从第五行开始,P和Q的列就被一行接一行的存储。每一行,都有两个领导标志跟在一列值后面。第一个标志是被存储列的名字,第二个标志表明值的类型。如果第二个标志是‘T’,列是真值。否则,列的所有值是NaN。举个例子:
[1 NaN 2] [-1 -2]
P = |3 NaN 4|, Q = |-3 -4|,
[5 NaN 6] [-5 -6]
并且b=0.5,则模型文件的内容是:
--------model file--------
m 3
n 2
k 3
b 0.5
p0 T 1 3 5
p1 F 0 0 0
p2 T 2 4 6
q0 T -1 -3 -5
q1 T -2 -4 -6
--------------------------
使用
'mf-train'
用法: mf-train [options] training_set_file [model_file]
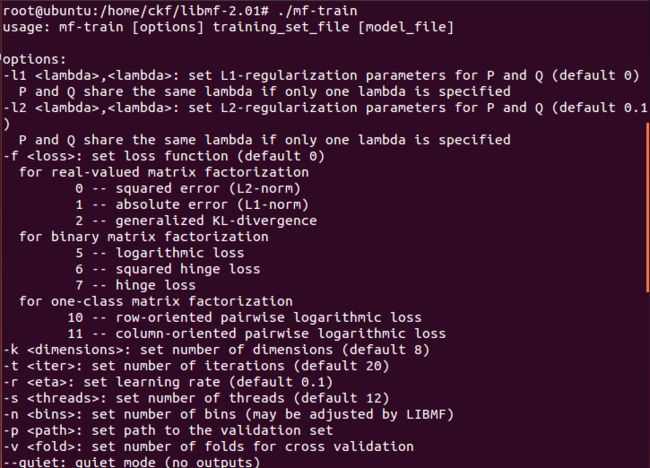
![]()
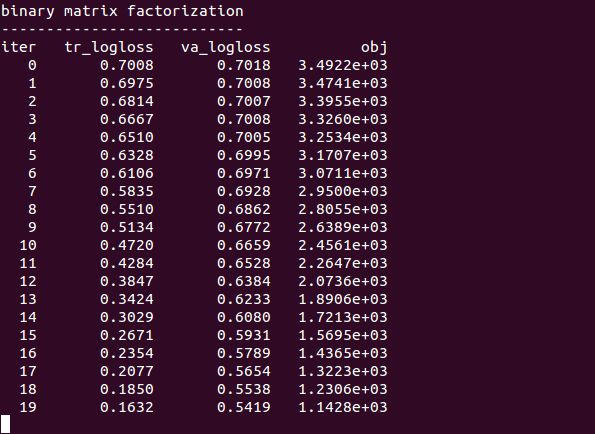
“mf-train”是LibMF最主要的训练命令。每次迭代,下列信息都被打印出来:
- iter: the index of iteration
- tr_xxxx: xxxx is the evaluation criterion on the training set
- va_xxxx: the same criterion on the validation set if `-p' is set
- obj: objective function value
这里的`tr_xxxx' 和 `obj' 都是估计的,因为计算真的值太耗时间了。
对于不同的损失,标准如下:
- 0: root mean square error (RMSE)
- 1: mean absolute error (MAE)
- 2: generalized KL-divergence (KL)
- 5: logarithmic loss
- 6 & 7: accuracy
- 10 & 11: pair-wise logarithmic loss (BprLoss)
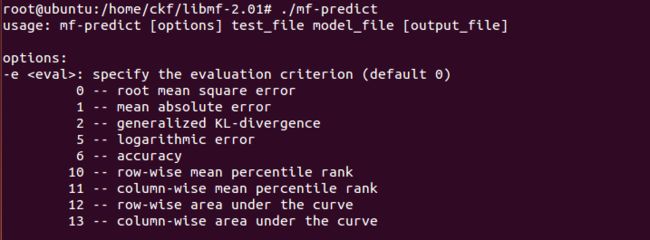
'mf-predict'
用法:mf-predict [options] test_file model_file output_file
示例
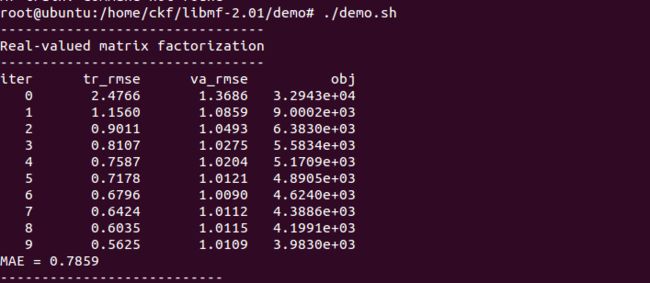
在demo目录中,有一个“demo.sh”shell脚本,运行它可以用来演示。
下面做一些操作:
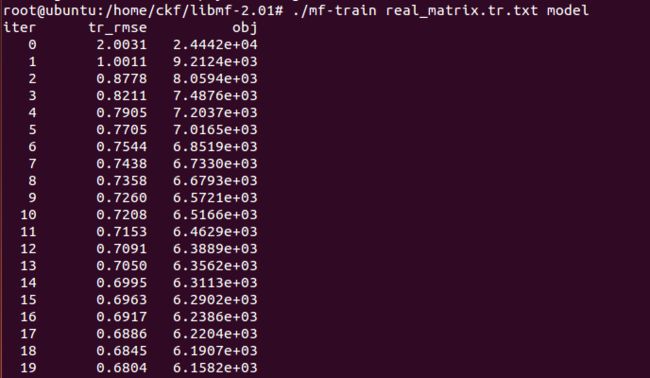
mf-train real_matrix.tr.txt model
train a model using the default parameters
mf-train -l1 0.05 -l2 0.01 real_matrix.tr.txt model
train a model with the following regularization coefficients:
coefficient of L1-norm regularization on P = 0.05
coefficient of L1-norm regularization on Q = 0.05
coefficient of L2-norm regularization on P = 0.01
coefficient of L2-norm regularization on Q = 0.01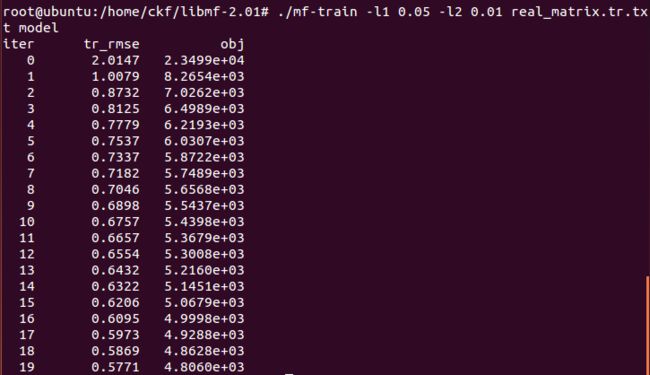
mf-train -l1 0.015,0 -l2 0.01,0.005 real_matrix.tr.txt model
train a model with the following regularization coefficients:
coefficient of L1-norm regularization on P = 0.05
coefficient of L1-norm regularization on Q = 0
coefficient of L2-norm regularization on P = 0.01
coefficient of L2-norm regularization on Q = 0.03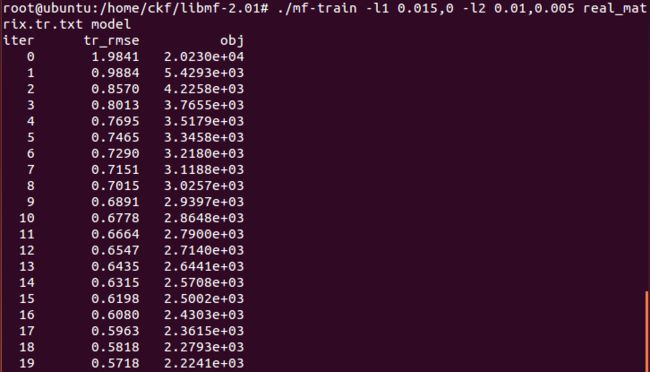
mf-train -f 5 -l1 0,0.02 -k 100 -t 30 -r 0.02 -s 4 binary_matrix.tr.txt model
train a BMF model using logarithmic loss and the following parameters:
coefficient of L1-norm regularization on P = 0
coefficient of L1-norm regularization on Q = 0.01
latent factors = 100
iterations = 30
learning rate = 0.02
threads = 4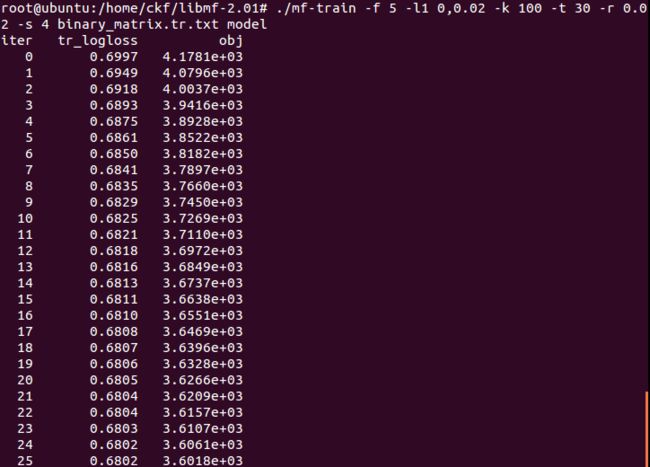
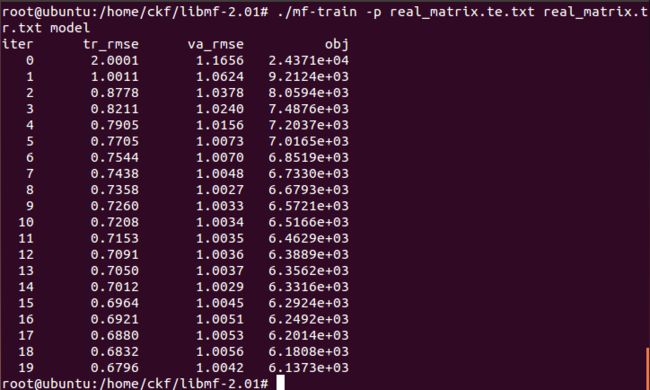
mf-train -p real_matrix.te.txt real_matrix.tr.txt model
use real_matrix.te.txt for hold-out validation
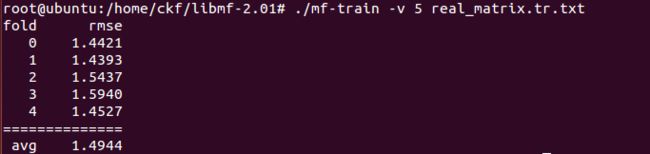
mf-train -v 5 real_matrix.tr.txt
do five fold cross validation
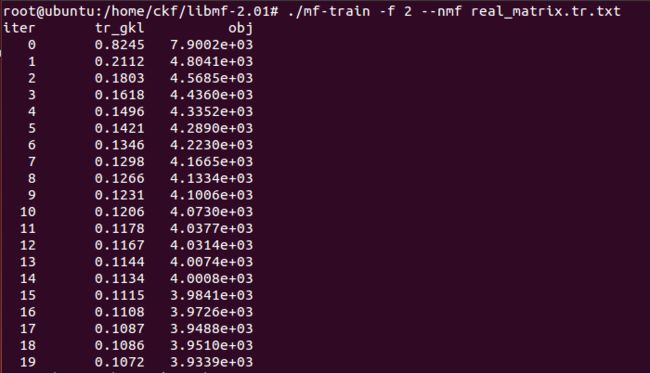
mf-train -f 2 --nmf real_matrix.tr.txt
do non-negative matrix factorization with generalized KL-divergence
mf-train --quiet real_matrix.tr.txt
do not print message to screen
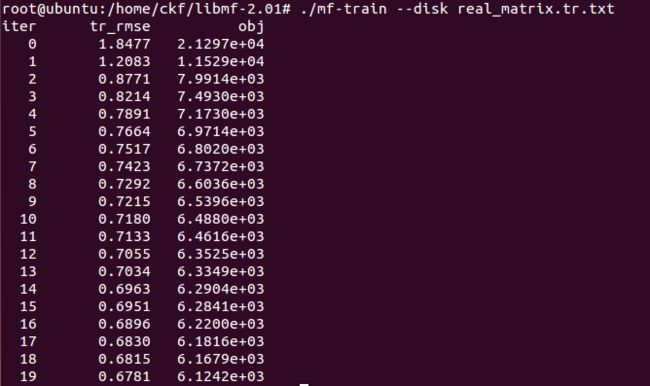
mf-train --disk real_matrix.tr.txt
do disk-level training
mf-predict real_matrix.te.txt model output
do prediction
mf-predict -e 1 real_matrix.te.txt model output
do prediction and output MAE
运行完以上操作后的文件夹
原文:http://blog.csdn.net/chenkfkevin/article/details/51064292