进程管理与系统调用
进程管理
进程是处于执行期的程序,包括挂机的信号、内核内部数据、处理器状态、代码段、数据段、一个或多个具有内存映射的内存地址空间及一个或多个执行程序。线程是在进程中活动的对象,内核调度的对象是线程而不是进程,但是在Linux系统中对线程和进程并不特别区分。
进程描述符task_struct包含的数据能完整的描述一个正在执行的程序。该结构体中的每个进程标识值PID唯一标识一个进程,它与进程一一对应。
struct task_struct {
unsigned long state;
int prio;
unsigned long policy;
struct task_struct *parent;
struct list_head tasks;
pid_t pid;
...
} 其中的state表示该进程当前的状态,包括TASK_RUNNING(运行)、TASK_INTERRUPTIBLE(可中断)、TASK_UNINTERRUPTTIBLE(不可中断)、_TASK_TRACED(被其他进程跟踪的进程)、_TASK_STOPPED(停止)。进程的状态会根据接收到的信号发生改变:
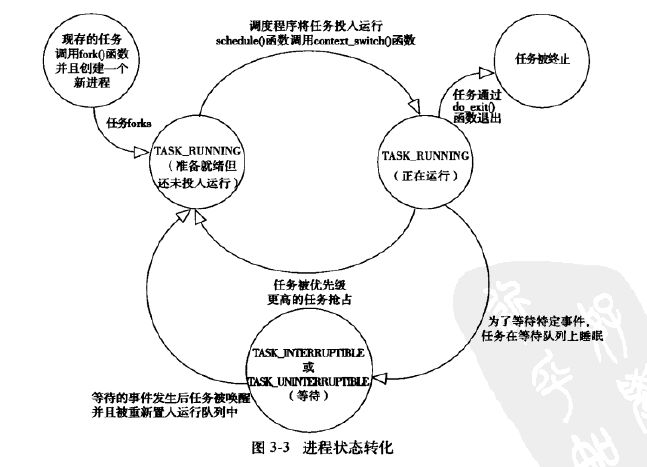
内核经常需要调整某个进程状态,方法如下:
set_task_state(task, state);
set_current_state(state); Linux中新进程的创建
Linux中所有进程都是PID为1的init进程的后代,init进程在系统启动的最后阶段启动,其进程描述符是作为init_task静态分配的。
与Unix类似,Linux采用了一种很特别的进程创建方式。Linux中进程创建通过执行两个单独的函数完成,即fork()和exec()。
Linux通过fork()函数产生子进程,fork()通过clone()系统调用实现。fork()会创建一个当前进程的子进程,该子进程与父进程的区别仅仅在于PID、PPID和某些资源和统计量。父进程与子进程共享代码空间。由于是两个代码一样的进程,所以父进程和子进程中的fork()函数都会返回,在父进程中fork返回新创建的子进程的PID,在子进程中fork返回0,如果出现错误fork返回一个负值。
执行完fork()之后,子进程大都要执行exec()函数,该函数会用新的进程上下文覆盖子进程中老的进程上下文,新进程代替原进程执行。出于效率考虑,Linux引入了写时拷贝技术。写时拷贝使得只有需要写入时候,子进程才会开辟新的物理空间来复制父进程的数据,使各个进程有格子的拷贝,也就是说执行完fork()之后,父进程和子进程的虚拟空间不同,但是物理空间相同。这就避免了fork产生的子进程开辟新空间并复制了父进程的数据之后马上执行exec()使得拷贝前功尽弃。所以现在的fork()开销只是复制父进程的页表以及给子进程创建唯一的进程描述符。
vfork()除了不拷贝父进程的页表项外,和fork()相同。vfork()会阻塞父进程,直到子进程退出或执行exec()。fork()尽管内核有意让子进程首先执行,但是并非总能如此。
线程的创建与普通进程类似,不过在调用clone()时候要传递一些参数标志来指明需要共享的资源:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0); 进程之行结束之后就要终结,子进程要等待父进程调用wait()函数,如果子进程结束了,父进程还没有调用wait()函数,子进程就会变成僵尸进程,直到父进程调用wait(),如果父进程到死都没有调用wait(),子进程被init进程接管;如果父进程先于子进程结束,子进程变成孤儿进程,过继给新父进程。
系统调用
系统调用是用户空间进程和硬件设备之间的中间层,其主要作用是:第一,为用户空间提供了一种硬件的抽象接口;第二,保证系统的稳定和安全;第三,用户空间和系统的其余部分提供一层公共接口,防止应用程序随意访问硬件。
系统调用在用户空间和内核空间有不同的返回值类型,在用户空间为int,在内核空间为long。
每个系统调用都有各自的系统调用号,进程执行系统调用时不会提及系统调用名称而是使用系统调用号。
用户空间程序无法直接执行内核代码,需要系统切换到内核态,使内核代表应用程序在内核空间执行系统调用。在x86上,用户空间把相应的系统调用对应的号放入eax寄存器传递给内核,系统调用所需的参数按顺序存放在ebx、ecx、edx、esi、edi寄存器上。
- 为了防止用户空间的程序访问它无权访问的地址,执行系统调用时候,内核要对其提供的参数进行验证,调用者可以使用capable()来检查是否有权对指定资源进行操作。在接收用户空间的指针之前,内需必须保证:
- 指针指向的内存区域属于用户空间;
- 指针指向的内存区域在进程的地址空间里;
- 对内存的读写和执行应当符合该内存的标记,进程不能绕过内存访问限制。
内核提供了从用户空间读取数据和向用户空间写入数据的方法:
copy_from_user();
copy_to_user();
网络云课堂学习
堆栈
计算机三大法宝:存储程序计算机、函数调用堆栈、中断。存储程序计算机工作模型是计算机系统最最基础性的逻辑结构;函数调用堆栈是高级语言得以运行的基础,只有机器语言和汇编语言的时候堆栈机制对于计算机来说并不那么重要,但有了高级语言及函数,堆栈成为了计算机的基础功能。
堆栈是C语言运行时必须的一个记录调用路径和参数的空间:1、函数调用框架;2、传递参数;3、保存返回地址;4、提供局部变量等等。函数传递参数使用变址寻址。
实验部分
在mykernel文件夹下,我们可以看到mymain.c和myinterrupt.c
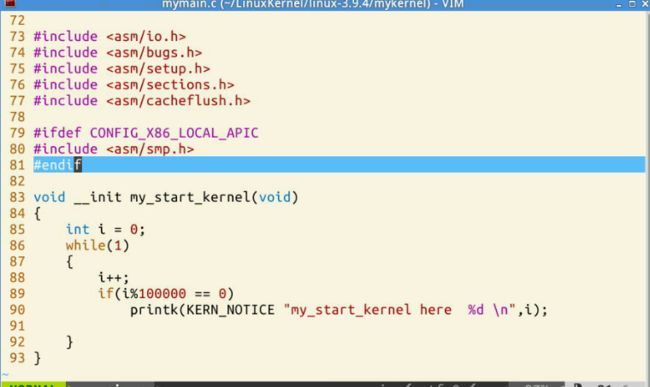
mymain.c
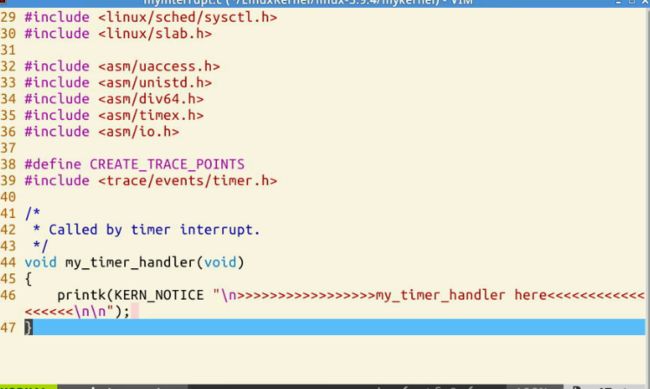
myinterrupt.c
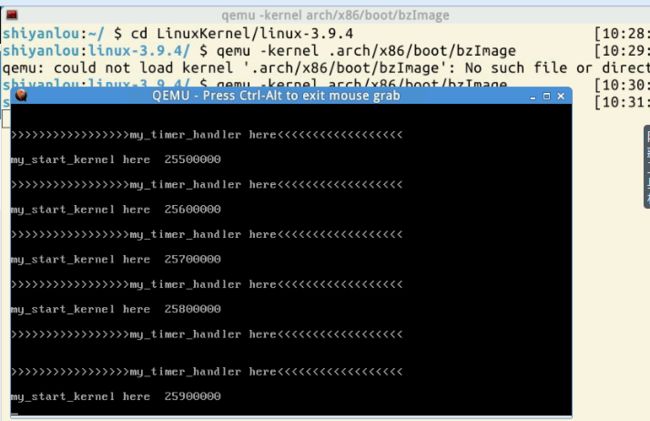
可以看到每隔10万个时钟周期发生一次。
下面我们来看个简单的时间片轮转多道程序代码。
首先是mypcb.h:

这段代码定义了一个名为Thread的结构体,用于保存ip和sp。然后定义了进程描述符PCB结构体,其中包括进程号pid,进程状态state、进程的堆栈、进程的Thread(ip和sp)、程序入口task_entry、下一个进程的进程描述符*next、优先权priority。最后还生命了一个调度器my_schedule(void)。
下面来看mymain.c,
void __init my_start_kernel(void)
{
int pid = 0;
/* Initialize process 0*/
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
// set task 0 execute entry address to my_process
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];
/*fork more process */
for(pid=1;pid>>process 0 running!!!<<<\n\n");
/* start process 0 by task[0] */
pid = 0;
my_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip */
"ret\n\t" /* pop task[pid].thread.ip to eip */
"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
); 该函数是初始化系统内核的,首先创建0号进程,初始化了一个只有一个PCB的循环链表。然后通过循环扩充链表,memcpy()函数将0号进程的所有数据拷贝到多个PCB中并对多个PCB数据进行修改。最后初始化堆栈ebp、esp、eip。
void my_process(void)
{
int i = 0;
while(1)
{
i++;
if(i%10000000 == 0)
{
if(my_need_sched == 1)
{
my_need_sched = 0;
sand_priority();
my_schedule();
}
}
}
}该函数定义了时间片。
void my_timer_handler(void)
{
#if 1
// make sure need schedule after system circle 2000 times.
if(time_count%2000 == 0 && my_need_sched != 1)
{
my_need_sched = 1;
//time_count=0;
}
time_count ++ ;
#endif
return;
}当发生中断时,把my_need_sched的值改成1.这时my_process中if部分开始,把my_need_sched复位为0,并调用my-schedul。
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{//save current scene
/* switch to next process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
"1:\t" /* next process start here */
"popl %%ebp\n\t"
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;//switch to the next task
printk(KERN_NOTICE " switch from %d process to %d process\n >>>process %d running!!!<<<\n\n",prev->pid,next->pid,next->pid);
}
else
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE " switch from %d process to %d process\n >>>process %d running!!!<<<\n\n\n",prev->pid,next->pid,next->pid);
/* switch to new process */
asm volatile(
"pushl %%ebp\n\t" /* save ebp */
"movl %%esp,%0\n\t" /* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
跳转到下一个进程。
问题和解决
在学习进程管理尤其是学习fork()时候有很多困惑,比如fork()之后的父子进程谁先运行,fork()之后子进程都有些什么东西,什么是和父进程共享的,fork()之后子进程究竟从哪里开始执行(因为此时父进程正在执行fork(),按道理子进程也应该是这样的,那么子进程如何返回),有了写时拷贝子进程的物理空间什么时候开辟等,不过这些问题在后来的学习中,通过网上资料都已经解决。
参考资料:
- fork之后子进程到底复制了父进程什么 :http://blog.csdn.net/xy010902100449/article/details/44851453
- fork出的子进程和父进程 :http://blog.csdn.net/theone10211024/article/details/13774669