1.fit_transform() 2.get_dummies 3.pd.columns 4.Python字符串格式化--format()方法
1.Python: sklearn库中数据预处理函数fit_transform()和transform()的区别
敲《Python机器学习及实践》上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下:
涉及到这两个函数的代码如下:
# 从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
# fit_transform()先拟合数据,再标准化
X_train = ss.fit_transform(X_train)
# transform()数据标准化
X_test = ss.transform(X_test)
我们先来看一下这两个函数的API以及参数含义:
1、fit_transform()函数

即fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式
2、transform()函数

即tranform()的作用是通过找中心和缩放等实现标准化
到了这里,我们似乎知道了两者的一些差别,就像名字上的不同,前者多了一个fit数据的步骤,那为什么在标准化数据的时候不使用fit_transform()函数呢?
原因如下:
为了数据归一化(使特征数据方差为1,均值为0),我们需要计算特征数据的均值μ和方差σ^2,再使用下面的公式进行归一化:
![]()
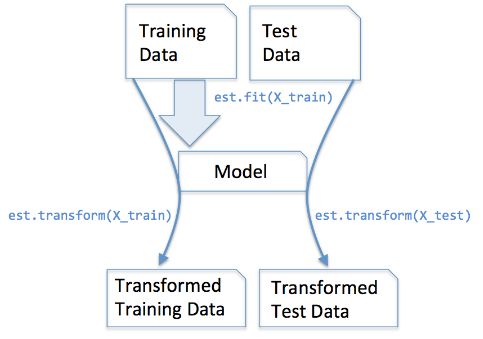
我们在训练集上调用fit_transform(),其实找到了均值μ和方差σ^2,即我们已经找到了转换规则,我们把这个规则利用在训练集上,同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据。用一幅图展示如下:
2.pandas使用get_dummies进行one-hot编码
官网:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
Convert categorical variable into dummy/indicator variables
| Parameters: | data : array-like, Series, or DataFrame prefix : string, list of strings, or dict of strings, default None
prefix_sep : string, default ‘_’
dummy_na : bool, default False
columns : list-like, default None
sparse : bool, default False
drop_first : bool, default False
Returns ——- dummies : DataFrame or SparseDataFrame |
|---|
See also
Series.str.get_dummies
Examples
>>> import pandas as pd
>>> s = pd.Series(list('abca'))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
>>> s1 = ['a', 'b', np.nan]
>>> pd.get_dummies(s1)
a b
0 1 0
1 0 1
2 0 0
>>> pd.get_dummies(s1, dummy_na=True)
a b NaN
0 1 0 0
1 0 1 0
2 0 0 1
>>> df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'],
... 'C': [1, 2, 3]})
>>> pd.get_dummies(df, prefix=['col1', 'col2'])
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
>>> pd.get_dummies(pd.Series(list('abcaa')))
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 1 0 0
>>> pd.get_dummies(pd.Series(list('abcaa')), drop_first=True)
b c
0 0 0
1 1 0
2 0 1
3 0 0
4 0 0离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的对离散型特征进行one-hot编码
[python] view plain copy
import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)
说明:对于有大小意义的离散特征,直接使用映射就可以了,{'XL':3,'L':2,'M':1}
Using the get_dummies will create a new column for every unique string in a certain column:使用get_dummies进行one-hot编码
[python] view plain copy
pd.get_dummies(df)
3.pd.columns和pd.columns.tolist
print(food_info.columns)
# 输出:输出全部的列名,而不是用省略号代替
Index(['NDB_No', 'Shrt_Desc', 'Water_(g)', 'Energ_Kcal', 'Protein_(g)', 'Lipid_Tot_(g)', 'Ash_(g)', 'Carbohydrt_(g)', 'Fiber_TD_(g)', 'Sugar_Tot_(g)', 'Calcium_(mg)', 'Iron_(mg)', 'Magnesium_(mg)', 'Phosphorus_(mg)', 'Potassium_(mg)', 'Sodium_(mg)', 'Zinc_(mg)', 'Copper_(mg)', 'Manganese_(mg)', 'Selenium_(mcg)', 'Vit_C_(mg)', 'Thiamin_(mg)', 'Riboflavin_(mg)', 'Niacin_(mg)', 'Vit_B6_(mg)', 'Vit_B12_(mcg)', 'Vit_A_IU', 'Vit_A_RAE', 'Vit_E_(mg)', 'Vit_D_mcg', 'Vit_D_IU', 'Vit_K_(mcg)', 'FA_Sat_(g)', 'FA_Mono_(g)', 'FA_Poly_(g)', 'Cholestrl_(mg)'], dtype='object')
复制代码
可以使用tolist()函数转化为list
food_info.columns.tolist()4.Python字符串格式化--format()方法
1.简单运用
字符串类型格式化采用format()方法,基本使用格式是:
<模板字符串>.format(<逗号分隔的参数>)
调用format()方法后会返回一个新的字符串,参数从0 开始编号。
"{}:计算机{}的CPU 占用率为{}%。".format("2016-12-31","PYTHON",10)
Out[10]: '2016-12-31:计算机PYTHON的CPU 占用率为10%。'
format()方法可以非常方便地连接不同类型的变量或内容,如果需要输出大括号,采用{{表示{,}}表示},例如:
"{}{}{}".format("圆周率是",3.1415926,"...")
Out[11]: '圆周率是3.1415926...'
"圆周率{{{1}{2}}}是{0}".format("无理数",3.1415926,"...")
Out[12]: '圆周率{3.1415926...}是无理数'
s="圆周率{{{1}{2}}}是{0}" #大括号本身是字符串的一部分
s
Out[14]: '圆周率{{{1}{2}}}是{0}'
s.format("无理数",3.1415926,"...") #当调用format()时解析大括号
Out[15]: '圆周率{3.1415926...}是无理数'