深入理解浏览器工作原理
前言
浏览器(browser application)是专门用来访问和浏览万维网页面的客户端软件,
也是现代计算机系统中应用最为广泛的软件之一,其重要性不言而喻。
前端工程师作为负责程序页面显示的工程师,需要直接与浏览器打交道。
本文将详细学习浏览器的工作原理
浏览器的工作原理
图解浏览器的基本工作原理
浏览器的组成
浏览器的组成如下图所示
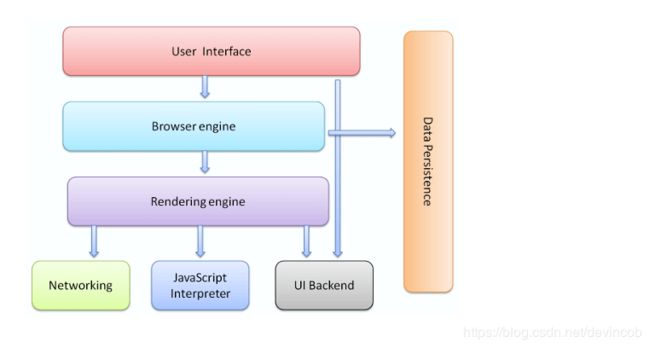
browser
主要组件包括:
1. 用户界面 - 包括地址栏、后退/前进按钮、书签目录等,也就是所看到的除了用来显示所请求页面的主窗口之外的其他部分
2. 浏览器引擎 - 用来查询及操作渲染引擎的接口
3. 渲染引擎 - 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
4. 网络 - 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
5. UI后端 - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
6. JS解释器 - 用来解释执行JS代码。
7. 数据存储 - 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
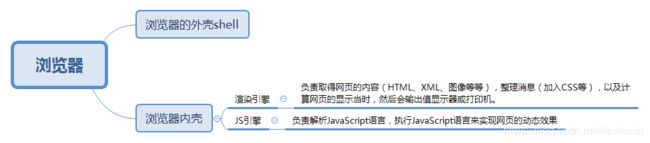
浏览器的核心
浏览器内核分成两部分:渲染引擎和js引擎。
由于js引擎越来越独立,内核就倾向于只指渲染引擎,负责请求网络页面资源加以解析排版并呈现给用户
默认情况下,渲染引擎可以显示html、xml文档及图片,它也可以借助插件显示其他类型数据,例如使用PDF阅读器插件,可以显示PDF格式
Js引擎负责解析JavaScript语言,执行,JavaScript·语言来实现网页动态效果
1、【渲染引擎】
主要作用:将网页代码渲染为用户视觉效果可以感知的平面文档
Firefox:Gecko引擎
chrome/safari webkit引擎/而后使用Blink引擎
OperaPresto引擎/而后使用Blink引擎
IE:Trident引擎
Edge:EdgeHTML引擎(2015年微软推出自己新的浏览器,原名叫斯巴达,后改名edge,使用edge引擎)
UC:U3引擎
QQ浏览器和微信内核使用X5引擎,16年开始使用Blink引擎
2、【js引擎】:
现代最常见的js引擎:
1、IE:IE使用Jscript引擎,IE9之后使用Chakra引擎,edge浏览器仍然使用Chakra引擎
2、Safari: Nitro、JavaScript Core(SquirrelFish系列引擎)
3、Opera:Carakan
4、Firefox:monkey
5、Chrome:V8(nodeJs其实就是封装了V8引擎)
主要作用:读取网页中的javascript代码,对其进行处理并运行。
javascript是一种解释型语言,也就是它不需要编译,有解释器实时运行。
- 好处是运行和修改都比较方便,刷新页面皆可以重新解释执行;
- 缺点是每次执行都需要重新调用解释器,系统开销较大,运行速度慢于编译型语言。
为了提高运行速度,目前浏览器都javascript进行一定程度的编译,
生成类似字节码(bytecode)的中间代码,以提高运行速度。
早期浏览器对javascript处理分为以下几个阶段:(即编译原理)
- 读取代码,进行词法分析(Lexical),将代码分解成词元(token)。
- 对词元进行语法分析(parsing),将代码整理成“语法树”(syntax tree)。
- 进行语义分析,使用“翻译器”将代码转为字节码(bytecode)。
- 使用“字节码解释器”(bytecode interpreter)将字节码转换成机器码。
但是,逐行解释将字节码转换成机器码,是很低的效率。为了提高运行速度,现代浏览器改为采用“即时编译”(Just In Time Compiler,缩写JIT),即字节码只在运行时编译,用到哪一行就编译哪一行,并且把编译结果缓存(inline cache)。
通常,一个程序被经常用到的,只是其中一小部分代码,有了缓存的编译结果,整个程序的运行速度就会提升。
字节码不能直接运行,而是运行在一个虚拟机之上(Virtual Machine)之上,一般也把虚拟机成为javscript引擎。
并非所有的js引擎都是将字节码编译成机器码运行的,有的引擎是基于源码编译成机器码运行,
即只要有可能,就直接通过JIT编译器将源码编译成机器码运行,省略字节码步骤。
这一点与其他采用虚拟机的语言不相同(java等)。这样做的目的,只为了尽可能的优化代码,提高性能。
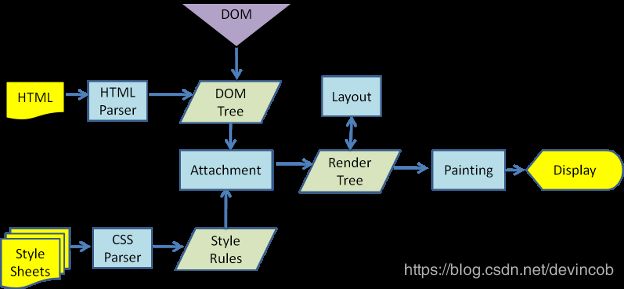
渲染流程
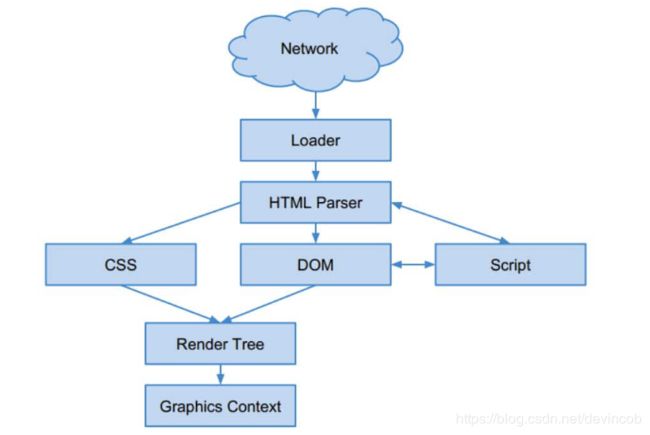
从资源的下载到最终的页面展现,渲染流程可简单地理解成一个线性串联的变换过程的组合,
原始输入为URL地址,最终输出为页面Bitmap,
中间依次经过了Loader(加载)、Parser(解析)、Layout(布局)和Paint(绘制)模块

渲染引擎处理网页,通常分为四个阶段:
- 解析代码:HTML代码解析为DOM,CSS代码解析为CSSOM;
- 对象合成:将DOM和CSSOM合成一颗渲染树(render tree);
- 布局:计算出渲染树的布局流(layout flow);
- 绘制:将渲染树根据布局流绘制到屏幕。

备注:
以上四个阶段并非严格按顺序执行的,往往第一步还未执行完,第二和第三步就已经开始了。
所以会看到HTML代码还未下载完,浏览器就已经显示部分内容了。
chrome渲染引擎的核心流程如下所示
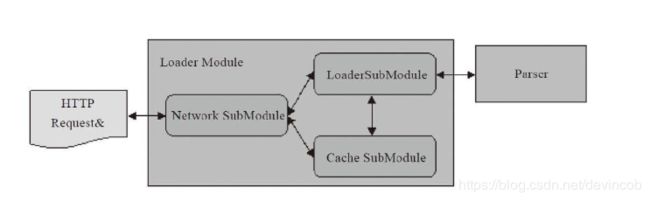
1、【Loader】
Loader模块负责处理所有的HTTP请求以及网络资源的缓存,相当于是从URL输入到Page Resource输出的变换过程。HTML页面中通常有外链的JS/CSS/Image资源,为了不阻塞后续解析过程,一般会有两个IO管道同时存在,一个负责主页面下载,一个负责各种外链资源的下载
chrome
注意:虽然大部分情况下不同资源可以并发下载异步解析(如图片资源可以在主页面解析显示完成后再被显示),但JS脚本可能会要求改变页面,因此有时保持执行顺序和下载管道后续处理的阻塞是不可避免的
2、【Parser】
1、解析HTML
Parser模块主要负责解析HTML页面,完成从HTML文本到HTML语法树再到文档对象树(Document Object Model Tree,DOM Tree)的映射过程
HTML语法树生成是一个典型的语法解析过程,可以分成两个子过程:词法解析和语法解析
词法解析按照词法规则(如正则表达式)将HTML文本分割成大量的标记(token),并去除其中无关的字符如空格。语法解析按照语法规则(如上下文无关文法)匹配Token序列生成语法树,通常有自上而下和自下而上两种匹配方式
浏览器内核中对HTML页面真正的内部表示并不是语法树,而是W3C组织规范的文档对象模型(Document Object Model,DOM)。DOM也是树形结构,以Document对象为根。DOM节点基本和HTML语法树节点一一对应,因此在语法解析过程中,通常直接生成最终的DOM树
2、解析CSS
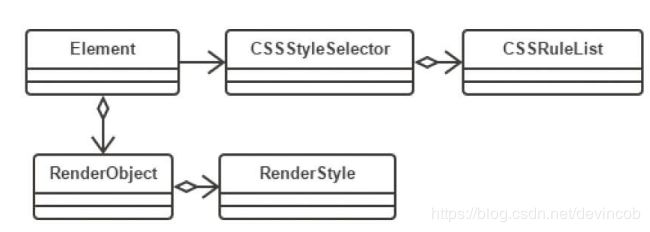
页面中所有的CSS由样式表CSSStyleSheet集合构成,而CSSStyleSheet是一系列CSSRule的集合,每一条CSSRule则由选择器CSSStyleSelector部分和声明CSSStyleDeclaration部分构成,而CSSStyleDeclaration是CSS属性和值的Key-Value集合
CSS解析完毕后会进行CSSRule的匹配过程,即寻找满足每条CSS规则Selector部分的HTML元素,然后将其Declaration部分应用于该元素。实际的规则匹配过程会考虑到默认和继承的CSS属性、匹配的效率及规则的优先级等因素
3、解析Javascript
JavaScript一般由单独的脚本引擎解析执行,它的作用通常是动态地改变DOM树(比如为DOM节点添加事件响应处理函数),即根据时间(timer)或事件(event)映射一棵DOM树到另一棵DOM树。
简单来说,经过了Parser模块的处理,内核把页面文本转换成了一棵节点带CSS Style、会响应自定义事件的Styled DOM树
3、【layout】
Layout过程就是排版,它包含两大过程
1、创建渲染树
布局树(或者叫做渲染树、Render Tree)和DOM树大体能一一对应,两者在内核中同时存在但作用不同。DOM树是HTML文档的对象表示,同时也作为JavaScript操纵HTML的对象接口。Render树是DOM树的排版表示,用以计算可视DOM节点的布局信息(如宽、高、坐标)和后续阶段的绘制显示
注意:并非所有DOM节点都可视,也就是并非所有DOM树节点都会对应生成一个Render树节点。例如head标签(HTMLHeadElement节点)不表示任何排版区域,因而没有对应的Render节点。同时,DOM树可视节点的CSS Style就是其对应Render树节点的Style
chrome
2、计算布局
布局就是安排和计算页面中每个元素大小位置等几何信息的过程。HTML采用流式布局模型,基本的原则是页面元素在顺序遍历过程中依次按从左至右、从上至下的排列方式确定各自的位置区域
一个HTML元素对应一个以CSS盒子模型描述的方块区域,HTML元素分成两个基本类型,Inline和Block。Inline元素不会换行,按从左到右来布局。Block元素的出现意味着需要从上至下换到下一行来布局。除了这种基本的顺序按照元素的Inline和Block来进行流式布局之外,还有特殊指定的一些布局方式,如Absolute/Fixed/Relative三种定位布局以及Float浮动布局
简单情况下,布局可以顺序遍历一次Render树完成,但也有需要迭代的情况。当祖先元素的大小位置依赖于后代元素或者互相依赖时,一次遍历就无法完成布局,如Table元素的宽高未明确指定而其下某一子元素Tr指定其高度为父Table高度的30%的情况
经过了Layout阶段的处理,把带Style的DOM树变换成包含布局信息和绘制信息的Render树,接下来的显示工作就交由Paint模块进行操作了
4、【Paint】
Paint模块负责将Render树映射成可视的图形,它会遍历Render树调用每个Render节点的绘制方法将其内容显示在一块画布或者位图上,并最终呈现在浏览器应用窗口中成为用户看到的实际页面。每个节点对应的大小位置等信息都已经由Layout阶段计算好了,节点的内容取决于对应的HTML元素,或是文本,或是图片,或是UI控件
通常情况下,布局和绘制是相当耗时的操作。如果DOM树每次略有改动都要重新布局和绘制一次,效率会相当低下。因此,一般浏览内核都会实现一种增量布局和增量绘制的方式。当一个DOM树节点(或者它的子节点)内容或者样式发生变化时,内核会确定其影响范围,在布局阶段会标记出受该节点布局影响的其他节点(比如可能是子节点),在绘制阶段则会标记出一个Dirty区域并通知系统重绘
按照HTML相关规范,页面元素的CSS属性也规定了其绘制顺序,如根据不同Layer必须按顺序绘制,否则覆盖叠加效果会出现错误,如元素的边框轮廓和内容背景的绘制次序也有规定
资源加载
使用浏览器上网时,首先会在地址栏输入一个网址,浏览器会依据网址向服务器发送资源请求,服务器解析请求,并将相关数据资源传送回给浏览器,这些数据资源包括Page的描述文档、图片、JavaScript脚本、CSS等。此后,浏览器引擎会对数据进行解码、解析、排版、绘制等操作,最终呈现出完整的页面。Loader是浏览器的排头兵,负责资源加载的工作
Loader在浏览器中承上启下,一方面它作为网络模块的客户,通过网络模块来加载资源;另一方面它为Parser模块加载页面的内容,控制着浏览器后续的解析以及绘制过程
chrome
Loader有两条资源加载路径:主资源加载路径和派生资源加载路径。这两类资源的加载过程颇有不同,比如对资源加载失败的处理,主资源下载失败会有报错提示,而派生资源如图片下载失败,往往只显示一个占位
在地址栏输入新地址或者在已经打开的页面中点击链接,都会触发主资源的加载流程,随着主资源在HTTP协议的传输下分段到达,浏览器的Parser模块解析主资源的内容,生成派生资源对应的DOM结构,然后根据需求触发派生资源的加载流程。主资源的加载是立刻发起的,而派生资源则可能会为了优化网络,在队列中等待
主资源和派生资源的加载还有一个区别,在Android 4.2版本中主资源是没有缓存的,而派生资源是有缓存机制的。这里的缓存指的是Memory Cache,用于保存原始数据(比如CSS、JS等),以及解码过的数据,通过Memory Cache可以节省网络请求和图片解码的时间
浏览器在加载主资源后,主资源会被解码,然后进行解析,生成DOM(文档对象模型)树。在解析过程中,如果遇到 缓存 【内存缓存】 Memory Cache,顾名思义内存缓存,其主要作用为缓存页面使用各种派生资源。在使用浏览器浏览网页时,尤其是浏览一个大型网站的不同页面时,经常会遇到网页中包含相同资源的情况,应用Memory Cache可以显著提高浏览器的用户体验,减少无谓的内存、时间以及网络带宽开销 【页面缓存】 Page Cache,即页面缓存。用来缓存用户访问过的网页DOM树、Render树等数据。设计页面缓存的意图在于提供流畅的页面前进、后退浏览体验。几乎所有的现代浏览器都支持页面缓存功能 如果浏览器没有页面缓存,用户点击链接访问新页面时,原页面的各种派生资源、JavaScript对象、DOM树节点等占据的内存统统被回收,此后当用户点击后退按钮以浏览原页面时,浏览器必须先要重新从网络下载相关资源,然后进行解码、解析、布局、渲染一系列操作,最后才能为用户呈现出页面,这无疑增加了用户的等待时间,影响了用户的使用体验 所有的派生资源加载时都会与Memory Cache关联,如果Memory Cache中有资源的备份且条件合适,则可以直接从Memory Cache中加载。而Page Cache只会在用户点击前进或后退按钮时才会被查询,如果页面符合缓存条件并被缓存了,则直接从Page Cache中加载。即使某个需要被加载的页面在Page Cache中有备份,但若触发加载的原因是用户在地址栏输入url或点击链接,则页面仍然是通过网络加载。也就是说Page Cache并不是主资源的通用缓存 【磁盘缓存】 Disk Cache,即磁盘缓存。现代的浏览器基本都有磁盘缓存机制,为了提升用户的使用体验,浏览器将下载的资源保存到本地磁盘,当浏览器下次请求相同的资源时,可以省去网络下载资源的时间,直接从本地磁盘中取出资源即可 磁盘缓存即我们常说的Web缓存,分为强缓存和协商缓存,它们的区别在于强缓存不发请求到服务器,协商缓存会发请求到服务器 网页解析 浏览器的解析过程就是将字节流形式的网页内容构建成DOM树、Render树及RenderLayer树的过程 浏览器的解析对象是网页内容,网页内容包括以下三个部分: 1、HTML文档:超文本标记语言,制作Web页面的标准语言 2、CSS样式表(Cascading Style Sheet):级联样式表,用来控制网页样式,并允许样式信息与网页内容相分离的一种标记性语言 3、JavaScript脚本:JavaScript是一种无类型的解释型脚本语言。常用于为网页添加动态功能 HTML文档决定了DOM树及Render树的结构。CSS样式表决定了Render树上节点的排版布局方式。JavaScript代码可以操作DOM树,改变DOM树的结构,也可以用来给页面添加更丰富的动态功能 HTML文档被解析生成DOM树,由DOM节点创建Render树节点时,会触发CSS匹配过程,CSS匹配的结果是RenderStyle实例,这个实例由Render节点持有,保存了Render节点的排版布局信息。CSS的解析过程即是CSS语法在浏览器的内部表示过程,解析的结果是得到一系列的CSS规则。CSS的匹配过程主要依据CSS选择器的不同优先级进行,高优先级选择器优先适用。根据网页上定义的JavaScript脚本的不同属性,JavaScript脚本的下载和执行时机会有所不同。JavaScript脚本的执行是由渲染引擎转交给JS引擎执行的。下面分别看一下HTML、CSS、JavaScript的具体解析和执行 【DOM树构建】 DOM(Document Object Model,文档对象模型),是中立于平台和语言的接口。它允许程序和脚本动态地访问和更新文档的内容结构和样式。DOM是页面上数据和结构的一个树形表示,使用DOM接口可以对DOM树结构进行操作。DOM规范只是定义了编程接口,没有对文档的表示方式做任何限制。以树状结构表示DOM文档是比较普遍的实现方式。这个树状结构就称为DOM树。DOM树是DOM文档中的节点按照层次组织构成的。以HTML文档为例,每一个标签都对应着DOM树上的一个节点。由于是树形结构表示,这些节点之间的关系也是通过父子或兄弟维系的 渲染引擎解析HTML文档的过程就是将字节流形式的网页内容解析成DOM Tree、Render Tree、Render Layer Tree三棵树的过程。这个过程可以分为解码、分词、解析、建树四个步骤 1、解码:将网络上接收到的经过编码的字节流,解码成Unicode字符 2、分词:按照一定的切词规则,将Unicode字符流切成一个个的词语(Tokens) 3、解析:根据词语的语义,创建相应的节点(Node) 4、建树:将节点关联到一起,创建DOM树、Render树和RenderLayer树 【Render树构建】 Render树用于表示文档的可视信息,记录了文档中每个可视元素的布局及渲染方式。Render树与DOM树是同时创建的 HTML页面通过CSS控制页面布局,所以RenderObject需要知道自身的CSS属性,CSSStyleSelector负责为元素提供RenderStyle。RenderObject包含自身的RenderStyle的引用。CSSStyleSelector是在CSS解析过程中生成的。Render节点创建后,就会被attach到Render树上 当前Render节点的父节点负责将当前Render节点插入到合适的位置,当父Render节点设置好当前Redner节点的前后兄弟节点后,当前Render节点就attach到了Render树上 RenderObject是Render树所有节点的基类,作用类似于DOM树的Node类。这个类存储了绘制页面可视元素所需要的样式及布局信息,RenderObject对象及其子类都知道如何绘制自己。事实上绘制Render树的过程就是RenderObject按照一定顺序绘制自身的过程。DOM树上的节点与Render树上的节点并不是一一对应的。只有DOM树的根节点及可视节点才会创建对应的RenderObject节点 【Render Layer树构建】 RenderLayer树以层为节点组织文档的可视信息,网页上的每一层对应一个RenderLayer对象。RenderLayer树可以看作Render树的稀疏表示,每个RenderLayer树的节点都对应着一棵Render树的子树,这棵子树上所有Render节点都在网页的同一层显示 RenderLayer树是基于RenderObject树构建的,满足一定条件的RenderObject才会建立对应的RenderLayer节点。下面是RenderLayer节点的创建条件: 1、网页的root节点 2、有显式的CSS position属性(relative,absolute,fixed) 3、元素设置了transform 4、元素是透明的,即opacity不等于1 5、节点有溢出(overflow)、alpha mask或者反射(reflection)效果。 6、元素有CSS filter(滤镜)属性 7、2D Canvas或者WebGL 8、Video元素 当满足这些条件之一时,RenderLayer实例被创建。RenderObject节点与RenderLayer节点是多对一的关系,即一个或多个RenderObject节点对应一个RenderLayer节点。这一点可以理解为网页的一层中可包含一个或多个可视节点。RenderLayer树的根节点是RenderView实例 RenderLayer的一个重要用途是可以在绘制时实现合成加速,即每一个RenderLayer对应系统的一块后端存储,这样在网页内容发生更新时,可以只更新有变化的RenderLayer,从而提高渲染效率 【CSS解析】 CSS解析过程即是将原始的CSS文件中包含的一系列CSS规则表示成渲染引擎中相应规则类的实例的过程 CSS文件解析完成后,CSS规则都保存在了CSSRuleList实例中,这些规则会在创建Render节点的过程中使用到。Node节点通过调用CSSStyleSelector实例的StyleForElement()函数为Render节点创建RenderStyle实例。有了RenderStyle实例才可以创建RenderObject实例。RenderStyle描述了RenderObject的排版布局信息,也就是匹配后的样式信息 CSS规则匹配是按照选择器类型的优先级进行的,不同类型的选择器具有不同的优先级。常用选择器类型的优先级如下: ID选择器 > 类型选择器 > 标签选择器 > 相邻选择器 > 子选择器 > 后代选择器 【JS执行】 JavaScript是一种解释型的动态脚本语言,需要由专门的JavaScript引擎执行。Android 4.2版本的WebKit采用的JavaScript执行引擎为V8,V8是由Google支持的开源项目。它的设计目的就是追求更高的性能,最大限度地提高JavaScript的执行效率。与JavaScriptCore等传统引擎不同,V8把JavaScript代码直接编译成机器码运行,比起传统“中间代码+解释器”的引擎,性能优势非常明显。JS代码通常保存在独立的JS文件中,通过script标签引用到HTML文档中 DOM树创建过程中遇到script标签时会创建HTMLScriptElement实例。HTMLScript-Element的父类ScriptElement中包含了对JS脚本的所有处理,包括下载、缓存、执行等。根据script标签的不同属性,JS脚本加载后的执行时机会有所不同。如果script标签中使用了async属性,JS脚本加载过程不会阻塞文档解析,脚本加载完成后会立即执行。如果sript标签中使用了defer属性,JS脚本加载过程不会阻塞文档解析,当脚本的执行要等得到文档解析完成之后。对于外部引用的脚本文件,从脚本下载到脚本执行完,文档解析过程会一直被阻塞 硬件加速 得到网页绘制信息的过程需要遍历RenderLayer树,将RenderLayer树包含的网页绘制信息先记录下来,等到渲染时使用。记录网页绘制信息这一步对渲染引擎而言,就是绘制的过程,渲染引擎本身并不知道绘制命令是否有被真正执行 【软件渲染】 软件渲染的流程可概括为以下三步: 1、从SurfaceFlinger获得一块图形缓冲区 2、在封装这块图形缓冲区的SkCanvas上执行网页绘制命令 3、将绘制好的图形缓冲区归还SurfaceFlinger 软件渲染实现简单,网页内容直接绘制到一块图形缓冲区上,内存占用更少。不足之处在于,由于网页内容绘制在同一块图形缓冲区上,更新网页内容时需要全部更新,无法局部更新 【硬件渲染】 相较于软件渲染,硬件渲染实现比较复杂,网页内容需要先绘制到一块SkBitmap上,再通过图形缓冲区上传给GPU,需要更多内存 硬件渲染是指网页各层的合成是通过GPU完成的,它采用分块渲染的策略,分块渲染是指:网页内容被一组Tile覆盖,每块Tile对应一个独立的后端存储,当网页内容更新时,只更新内容有变化的Tile。分块策略可以做到局部更新,渲染效率更高 硬件渲染的过程分为以下5步: 1、在一块封装了SkBitmap的SkCanvas上执行一个Tile覆盖的网页信息的绘制命令; 2、将每个Tile对应的SkBitmap copy到从SurfaceFlinger获得的一块图形缓冲区中; 3、将所有Tile对应的图形缓冲区上传GPU进行合成; 4、将合成好的网页内容blit到Tile对应的与OnScreen FrameBuffer相关联的Texture; 5、通过GPU对Tile对应的Texture进行硬件绘制 开启硬件渲染,即合成加速,会为需要单独绘制的每一层创建一个GraphicsLayer 合成加速情况下,每一层网页内容都对应一个后端存储,这块后端存储由平台实现,Android 4.2平台提供的后端存储是GraphicsLayerAndroid。开始记录网页绘制命令时,RenderLayerCompositor负责控制RenderLayer的遍历,RenderLayer包含的绘制信息最终记录在其后端存储上,即GraphicsLayerAndroid包含的PicturePile实例中 一个RenderLayer对象如果需要后端存储,它会创建一个RenderLayerBacking对象,该对象负责Renderlayer对象所需要的各种存储。理想情况下,每个RenderLayer都可以创建自己的后端存储,事实上不是所有RenderLayer都有自己的RenderLayerBacking对象。如果一个RenderLayer对象被像样的创建后端存储,那么将该RenderLayer称为合成层(Compositing Layer) 哪些RenderLayer可以是合成层呢?如果一个RenderLayer对象具有以下的特征之一,那么它就是合成层: 1、RenderLayer具有CSS 3D属性或者CSS透视效果。 2、RenderLayer包含的RenderObject节点表示的是使用硬件加速的视频解码技术的HTML5 ”video”元素。 3、 RenderLayer包含的RenderObject节点表示的是使用硬件加速的Canvas2D元素或者WebGL技术。 4、RenderLayer使用了CSS透明效果的动画或者CSS变换的动画。 5、RenderLayer使用了硬件加速的CSSfilters技术。 6、RenderLayer使用了剪裁(clip)或者反射(reflection)属性,并且它的后代中包括了一个合成层。 7、RenderLayer有一个Z坐标比自己小的兄弟节点,该节点是一个合成层 所以,进行硬件加速的渲染流程如下所示 browser 它们都具有阻塞效应。并且会耗费很多时间和计算资源。 重流和重绘并不一定会一起发生,重流必定导致重绘,重绘不一定需要发生重流。 大多数情况下,浏览器会智能判断,将重流和重绘只限制到相关的子树,最小化所耗费的代价,而不会全局重新生成网页。 作为开发者,应该尽量设法降低重绘的次数和成本。 关于减少重绘的优化技巧: 1、读取DOM或者写入DOM的操作,尽量写在一起,不要混杂。 2、缓存DOM信息。 3、不要一项一项地改变样式,而使用CSS class一次性的改变样式。 4、使用documentFragment操作DOM。 5、动画使用absolute定位或fixed定位,这样可以减少对其他元素的影响。 6、只在必要的时候显示隐藏元素。 7、使用window.requestAnimationFrame(),因为他可以把代码推迟到下一次重流执行,而不是立即要求页面重流。 8、使用虚拟DOM(virtual DOM)库。这样的方式还可以简化节点的操作和继承层次。现在很多框架都采用这种方式。 【回流】 回流reflow是firefox里的术语,在chrome中称为重排relayout 回流是指窗口尺寸被修改、发生滚动操作,或者元素位置相关属性被更新时会触发布局过程,在布局过程中要计算所有元素的位置信息。由于HTML使用的是流式布局,如果页面中的一个元素的尺寸发生了变化,则其后续的元素位置都要跟着发生变化,也就是重新进行流式布局的过程,所以被称之为回流 前面介绍过渲染引擎生成的3个树:DOM树、Render树、Render Layer树。回流发生在Render树上。常说的脱离文档流,就是指脱离渲染树Render Tree 触发回流包括如下操作: 1、DOM元素的几何属性变化 2、DOM树的结构变化 3、获取下列属性 4、改变元素的一些样式 5、调整浏览器窗口大小 触发回流一定会触发后续的重绘操作,而且对一个元素的回流,可能会影响到父级元素。比如子元素浮动后,父元素会出现高度塌陷的情况。所以,性能优化的重点在于尽量只触发小规模的重绘,尽量不触发回流 【重绘】 重绘是指当与视觉相关的样式属性值被更新时会触发绘制过程,在绘制过程中要重新计算元素的视觉信息,使元素呈现新的外观 由于元素的重绘repaint只发生在渲染层 render layer上。所以,如果要改变元素的视觉属性,最好让该元素成为一个独立的渲染层render layer 下面以元素显示为例,进行说明。实现元素显示隐藏的方式有很多 display: none/block,会引起回流,从而引起重绘,性能较差 visibility: visibile/hidden,只引起重绘,但由于没有成为一个独立的渲染层,会引起整个页面(或当前渲染层)的重绘,性能较好 opacity: 0/1,opacity小于1时,会产生render layer。所以opacity在0、1的变化中,引起了render layer的生成和销毁,因此,也会引起回流,从而引起重绘,性能较差。如果opacity: 0/0.9,则只会引起重绘 如果对一个元素使用硬件加速渲染,如具有CSS 3D属性,则不会进行重绘和回流。但如果使用硬件渲染的元素过多,会造成GPU的传输压力 【性能优化】 下面列举一些减少回流次数的方法 1、不要一条一条地修改DOM样式,而是修改className或者修改style.cssText 2、在内存中多次操作节点,完成后再添加到文档中去 3、对于一个元素进行复杂的操作时,可以先隐藏它,操作完成后再显示 4、在需要经常获取那些引起浏览器回流的属性值时,要缓存到变量中 5、不要使用table布局,因为一个小改动可能会造成整个table重新布局。而且table渲染通常要3倍于同等元素时间 此外,将需要多次重绘的元素独立为render layer渲染层,如设置absolute,可以减少重绘范围;对于一些进行动画的元素,可以进行硬件渲染,从而避免重绘和回流
缓存在浏览器中也得到了广泛的应用,对提高用户体验起到了重要作用。在浏览器中,主要存在三种类型的缓存:Page Cache、Memory Cache、Disk Cache。这三类Cache的容量都是可以配置的,比如限制Memory Cache最大不超过30MB,Page Cache缓存的页面数量不超过5个等Page Cache:是将浏览的页面状态临时保存在缓存中,以加速页面返回等操作
Memory Cache:浏览器内部的缓存机制,对于相同url的资源直接从缓存中获取,不需重新下载
Disk Cache:资源加载缓存和服务器进行交互,服务器端可以通过HTTP头信息设置网页要不要缓存。
可以将浏览器整体看作一个网页处理模块,这个模块的输入是网络上接收到的字节流形式的网页内容。输出是三棵树型逻辑结构:DOM树、Render树及RenderLayer树

chrome
解析选择器和解析属性值的过程都可能执行多次。渲染引擎为解析出来的选择器创建一个CSSSelector实例,由于可能存在多个选择器,渲染引擎使用CSSSelectorList类保存所有的选择器,并为解析出来的每个属性值对创建CSSProperty实例
chrome
CSS规则匹配过程就发生在CSSStyleSelector创建RenderStyle实例的过程中。CSSStyleSelector负责从CSSRuleList中找出所有匹配相应元素的样式属性的Property-Value对
所有匹配上元素的CSSStyleRule都会放入一个结果数组中。渲染引擎会对所有存入结果数组中的规则按照选择器的优先级进行排序,高优先级规则优先使用,最终使用的规则会用来创建RenderStyle实例。RenderStyle实例由RenderObject对象持有,RenderObject就是根据RenderStyle中包含的信息,进行自身排版绘制
WebKit渲染引擎的渲染方式分为软件渲染和硬件渲染,这两种渲染方式都可以分成两个大的过程:一是得到网页的绘制信息;二是将网页绘制信息转换成像素并上屏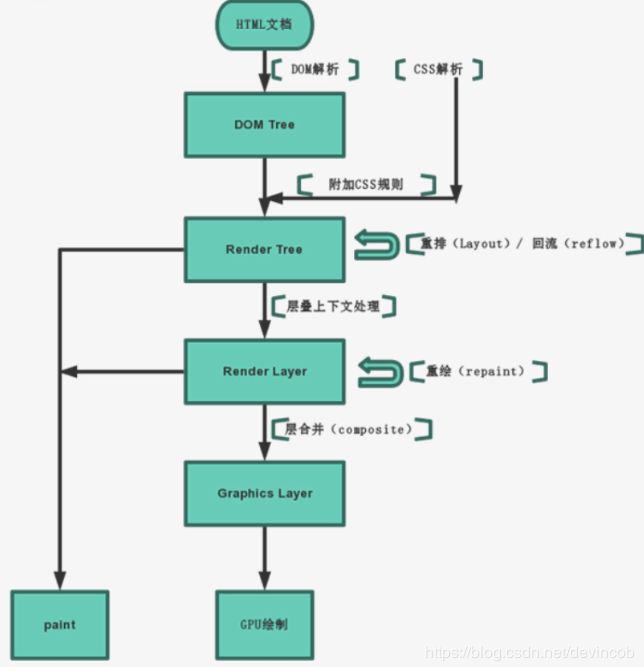
重流和重绘:
重绘和回流是在页面渲染过程中非常重要的两个概念。页面生成以后,脚本操作、样式表变更,以及用户操作都可能触发重绘和回流
渲染树转换为网页布局,称为“布局流”(flow)
布局显示到页面的这个过程,成为“绘制”(paint)。
页面生成以后,脚本操作和样式表操作,都会触发“重流”(reflow)和“重绘”(repaint)。
用户的互动也会触发重流和重绘,比如设置了鼠标悬停(a:hover)效果、滚动、在输入框中输入文本、改变窗口大小等等。
比如改变元素颜色,只会导致重绘,而不会导致重流;
简单的来说,改变元素的布局,则会发生重流,也就是对布局流做重新的计算。当然也会发生重绘。
比如,尽量不要变动高层的DOM元素,而以底层DOM元素的变动替代;
再比如,重绘table布局和flex布局,开销都会比较大。当然浏览器也会积累DOM变动,然后一次执行。
即不要读取一个节点,立即修改这个节点,接着再读取一个DOM节点。
渲染树转换为网页布局,称为“布局流”(flow)offsetTop\offsetLeft\offsetWidth\offsetHeight\scrollTop\scrollLeft\scrollWidth\scrollHeight\clientTop\clientLeft\clientWidth\clientHeight\getComputedStyle()\currentStyle()