机器学习——SVM预备知识 拉格朗日乘子法的推导
以下内容仅供参考,如有错误,欢迎指出
文章目录
- 什么是拉格朗日乘子法
- 预备知识——水平集
- 只具有一个等式约束的凸函数最优化问题
- 问题描述
- 问题的解决方案
- 拉格朗日乘子法为什么有效的简单推导
- 只具有一个不等式约束的凸函数最优化问题
- 问题描述
- 问题的解决方案
- 拉格朗日乘子法为什么有效的简单推导
- 多等式约束与多不等式约束的凸函数最优化问题
- 问题描述
- 问题的解决方案
什么是拉格朗日乘子法
以下内容摘自周志华老师的《机器学习》
拉格朗日乘子法是一种寻找多元函数在一组约束条件下的极值的方法,通过引入拉格朗日乘子,可将有d个变量与k个约束条件的最优化问题转换为具有d+k个变量的无约束优化问题求解
预备知识——水平集
以下内容摘自安全学求过
在数学领域中, 一个具有n变量的实值函数f的水平集是具有以下形式的集合
{ ( x 1 , . . . , x n ) ∣ f ( x 1 , . . . , x n ) = c } \{(x_1,...,x_n) | f(x_1,...,x_n) = c \} {(x1,...,xn)∣f(x1,...,xn)=c}
其中 c 是常数. 水平集即使得函数值具有给定常数的变量集合.
当具有两个自变量时, 称为水平曲线(等高线), 如果有三个自变量, 称为水平曲面, 更多自变量时, 水平集被叫做水平超曲面.
只具有一个等式约束的凸函数最优化问题
本节暂时只讨论求解满足等式约束条件下,凸函数最小的情况,但其求解方法同样适用于使目标函数最大的情况。
问题描述
假定x为d维向量,欲寻找x的某个取值 x ∗ x^* x∗,使凸函数 f ( x ) f(x) f(x)最小并满足 g ( x ∗ ) = c g(x^*)=c g(x∗)=c,c为常数,即:
min x f ( x ) s . t g ( x ) = c \min \limits_{x} f(x)\\ s.t \ g(x)=c xminf(x)s.t g(x)=c
问题的解决方案
使用拉格朗日乘子法,具体步骤如下
- 定义拉格朗日函数 L ( x , λ ) = f ( x ) + λ ( g ( x ) − c ) ( λ ! = 0 ) ( 式 1.0 ) L(x,\lambda)=f(x)+\lambda(g(x)-c) \ (\lambda!=0) \ (式1.0) L(x,λ)=f(x)+λ(g(x)−c) (λ!=0) (式1.0)
- 计算 { ∂ L ( x , λ ) ∂ x = 0 ∂ L ( x , λ ) ∂ λ = 0 \left\{ \begin{aligned} \frac{\partial L(x,\lambda)}{\partial x}=0\\ \frac{\partial L(x,\lambda)}{\partial \lambda}=0 \end{aligned} \right. ⎩⎪⎪⎨⎪⎪⎧∂x∂L(x,λ)=0∂λ∂L(x,λ)=0
d+1个变量(x是d维向量,有d个变量,加上一个 λ \lambda λ),d+1个方程,一定可以进行求解,求解出的 x x x代入 f ( x ) f(x) f(x)
拉格朗日乘子法为什么有效的简单推导
为便于理解,我们在三维函数上进行讨论,即利用拉格朗日乘子法解决以下凸优化问题:
min x , y f ( x , y ) s . t g ( x , y ) = c \min \limits_{x,y} f(x,y)\\ s.t \ g(x,y)=c x,yminf(x,y)s.t g(x,y)=c
我们在xOy平面上画出函数 f ( x , y ) f(x,y) f(x,y)的等高线和函数 g ( x , y ) g(x,y) g(x,y)的等高线(概念见预备知识一节中的水平集),接着,我们只保留函数 g ( x , y ) = c g(x,y)=c g(x,y)=c时的等高线,结果如下图:
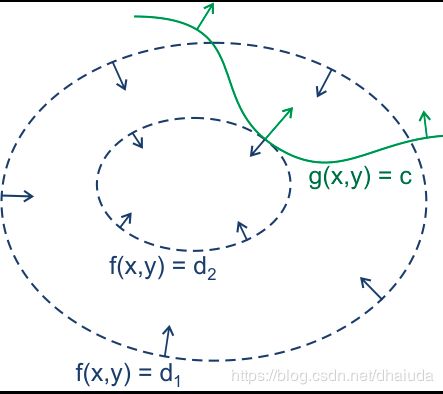
上图的蓝色箭头表示函数 f ( x , y ) f(x,y) f(x,y)梯度的反方向,绿线表示函数 g ( x , y ) g(x,y) g(x,y)的取值为c时的梯度方向,(x,y)只能位于绿线上,现在我们要求位于绿线上的点对应的 f ( x , y ) f(x,y) f(x,y)的最小值,我们来思考一下
-
这里先理解一下登高线形成的圈有什么含义,对于凸函数来说,等高线形成的圈越小,则离全局最小越接近,现在我们有一个想法, g ( x , y ) = c g(x,y)=c g(x,y)=c的等高线与函数 f ( x , y ) f(x,y) f(x,y)的若干等高线有若干交点,每个交点所处的等高线围成的圈大小不同,圈越小,对应的 f ( x , y ) f(x,y) f(x,y)取值越小,那么只需要找到圈最小处的交点,不就是函数 f ( x , y ) f(x,y) f(x,y)在 g ( x , y ) = c g(x,y)=c g(x,y)=c约束下的最小值了吗?
-
那么圈最小处的交点有什么特性呢?注意到圈最小,意味着该圈内部的圈不可能在与函数 g ( x , y ) = c g(x,y)=c g(x,y)=c的登高线具有交点,否则这个圈就不是最小了,因为外层的圈肯定比内层的圈要大,这意味圈最小处的交点位于的等高线与函数 g ( x , y ) = c g(x,y)=c g(x,y)=c相切
-
相切意味着什么?这里有一个定理——梯度与登高线的切线垂直,证明请查看为什么梯度的方向与等高线切线方向垂直
由此可知,相切意味着两个函数的梯度共线,即存在常数 λ \lambda λ满足 ∇ f ( x , y ) = λ ∇ g ( x , y ) \nabla f(x,y)=\lambda \nabla g(x,y) ∇f(x,y)=λ∇g(x,y),即 ∇ f ( x , y ) − λ ∇ ( g ( x , y ) − c ) = 0 \nabla f(x,y)-\lambda \nabla (g(x,y)-c)=0 ∇f(x,y)−λ∇(g(x,y)−c)=0(为什么要减c下面解释),将负号统一到 λ \lambda λ中即得到 ∇ f ( x , y ) + λ ∇ ( g ( x , y ) − c ) = 0 \nabla f(x,y)+\lambda \nabla (g(x,y)-c)=0 ∇f(x,y)+λ∇(g(x,y)−c)=0,即函数 L ( x , y , λ ) = f ( x , y ) + λ ( g ( x , y ) − c ) L(x,y,\lambda)=f(x,y)+\lambda (g(x,y)-c) L(x,y,λ)=f(x,y)+λ(g(x,y)−c)(式1.1)对x,y求偏导,故有
∂ f ( x , y ) ∂ x + λ ∂ ( g ( x , y ) − c ) ∂ x = 0 ∂ f ( x , y ) ∂ y + λ ∂ ( g ( x , y ) − c ) ∂ y = 0 \frac{\partial f(x,y)}{\partial x}+\lambda \frac{\partial (g(x,y)-c)}{\partial x}=0\\ \frac{\partial f(x,y)}{\partial y}+\lambda \frac{\partial (g(x,y)-c)}{\partial y}=0 ∂x∂f(x,y)+λ∂x∂(g(x,y)−c)=0∂y∂f(x,y)+λ∂y∂(g(x,y)−c)=0
式1.1具有三个变量,但是只有两个方程,我们还差一个方程,不怕不怕,式1.1对 λ \lambda λ求导,即得到约束条件,与上述两个方程联立,此时即可求解出x、y、 λ \lambda λ。 -
式1.1之所以多减去一个c,是为了让式1.1对 λ \lambda λ求导置0得到约束条件,将相切的点限制在 g ( x , y ) = c g(x,y)=c g(x,y)=c中( g ( x , y ) g(x,y) g(x,y)与 f ( x , y ) f(x,y) f(x,y)等高线相切的点有很多),此时将约束问题统一为对式1.0的无约束问题(只需将式1.0对 x 、 y 、 λ x、y、\lambda x、y、λ求导即可)
值得注意的是,相切处并不一定就是最小值,也有可能是最大值,即函数等高线形成的圈内部相切于约束等高线,因此我们需要将求得的多个相切值代入原式,从而取最小
只具有一个不等式约束的凸函数最优化问题
问题描述
假定x为d维向量,欲寻找x的某个取值 x ∗ x^* x∗,使凸函数 f ( x ) f(x) f(x)最小并满足 g ( x ∗ ) ≤ 0 g(x^*)\leq 0 g(x∗)≤0,即:
min x f ( x ) s . t h ( x ) ≤ 0 \min \limits_{x} f(x)\\ s.t \ h(x) \leq 0 xminf(x)s.t h(x)≤0
问题的解决方案
使用拉格朗日乘子法,具体步骤如下
- 定义拉格朗日函数 L ( x , λ ) = f ( x ) + λ h ( x ) ( λ ! = 0 ) ( 式 1.2 ) L(x,\lambda)=f(x)+\lambda h(x) \ (\lambda!=0) \ (式1.2) L(x,λ)=f(x)+λh(x) (λ!=0) (式1.2)
- 计算 { ∂ L ( x , λ ) ∂ x = 0 ∂ L ( x , λ ) ∂ λ = 0 \left\{ \begin{aligned} \frac{\partial L(x,\lambda)}{\partial x}=0\\ \frac{\partial L(x,\lambda)}{\partial \lambda}=0 \end{aligned} \right. ⎩⎪⎪⎨⎪⎪⎧∂x∂L(x,λ)=0∂λ∂L(x,λ)=0
- 求出的 x 、 y 、 λ x、y、\lambda x、y、λ需要满足KKT条件,否则不是原问题的解,KKT条件即为 { h ( x ) ≤ 0 λ ≥ 0 λ h ( x ) = 0 \left\{ \begin{aligned} & h(x) \leq 0 \\ & \lambda \geq 0 \\ &\lambda h(x)=0 \end{aligned} \right. ⎩⎪⎨⎪⎧h(x)≤0λ≥0λh(x)=0
上述过程在多维凸函数的多不等式约束求极值问题中依然能够成立
拉格朗日乘子法为什么有效的简单推导
考虑不等式约束 h ( x ) h(x) h(x),我们分两种情况讨论
- 凸函数的极值位于 h ( x ) < 0 h(x)< 0 h(x)<0处,此时不等式约束根本不起作用,即式1.2的 λ = 0 \lambda=0 λ=0,直接求解 ∇ f ( x ) = 0 \nabla f(x)=0 ∇f(x)=0即可
- 凸函数的极值不位于 h ( x ) < 0 h(x)<0 h(x)<0处,如下图(阴影部分表示 h ( x ) < 0 h(x)<0 h(x)<0,箭头表示梯度的逆方向):
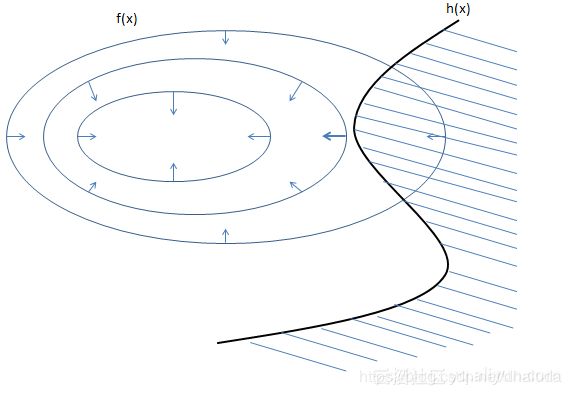 此时变为凸函数在 h ( x ) = 0 h(x)=0 h(x)=0下的极值问题,但此时有一个隐含条件 —— f ( x ) f(x) f(x)与 h ( x ) h(x) h(x)的梯度方向相反,意味着 λ > 0 \lambda>0 λ>0,理由如下:
此时变为凸函数在 h ( x ) = 0 h(x)=0 h(x)=0下的极值问题,但此时有一个隐含条件 —— f ( x ) f(x) f(x)与 h ( x ) h(x) h(x)的梯度方向相反,意味着 λ > 0 \lambda>0 λ>0,理由如下:
由于凸函数 f ( x ) f(x) f(x)的极值不在 h ( x ) < 0 h(x)<0 h(x)<0处, f ( x ) f(x) f(x)在切点的梯度方向将指向上图阴影部分(因为最小值不在阴影部分内,对切点来说,意味着凸函数 f ( x ) f(x) f(x)在阴影部分的点取值比不在阴影部分的点取值要大),而函数 h ( x ) h(x) h(x)在切点处的梯度方向指向阴影外部,因为阴影内部的点满足 h ( x ) < 0 h(x)<0 h(x)<0,切点满足 h ( x ) = 0 h(x)=0 h(x)=0,而梯度指向增长最快的方向,则 h ( x ) h(x) h(x)在切点的梯度方向指向外部
当 λ = 0 \lambda=0 λ=0时,为第一种情况,当 λ > 0 , g ( x ) = 0 \lambda>0,g(x)=0 λ>0,g(x)=0时,为第二种情况,以上两种情况综合起来,就是KKT条件,此时仍然有许多约束条件,我们可以使用拉格朗日对偶对其进行求解,请查看机器学习——SVM预备知识 拉格朗日对偶推导与证明
多等式约束与多不等式约束的凸函数最优化问题
问题描述
假定x为d维向量,欲寻找x的某个取值 x ∗ x^* x∗,使凸函数 f ( x ) f(x) f(x)最小并满足 g ( x ∗ ) ≤ 0 g(x^*)\leq 0 g(x∗)≤0,即:
min x f ( x ) s . t h i ( x ) ≤ 0 ( i = 1 , 2 , 3.... n ) g j ( x ) = 0 ( j = 1 , 2..... m ) \min \limits_{x} f(x)\\ s.t \ h_i(x) \leq 0 (i=1,2,3....n)\\ \ \ \ \ g_j(x)=0 (j=1,2.....m) xminf(x)s.t hi(x)≤0(i=1,2,3....n) gj(x)=0(j=1,2.....m)
问题的解决方案
将上两节的内容进行推广即可得到拉格朗日乘子法解决多等式约束与多不等式约束的凸函数最优化问题的形式
L ( x , λ , μ ) = f ( x ) + ∑ i = 1 m μ i g i ( x ) + ∑ i = 1 n β i h i ( x ) L(x,\lambda,\mu)=f(x)+\sum_{i=1}^m\mu_ig_i(x)+\sum_{i=1}^n\beta_ih_i(x) L(x,λ,μ)=f(x)+i=1∑mμigi(x)+i=1∑nβihi(x)
需满足
{ g i ( x ) ≤ 0 i = 1 , 2..... n μ i ≥ 0 i = 1 , 2..... n μ i g i ( x ) = 0 i = 1 , 2..... n h j ( x ) = 0 j = 1 , 2..... m ∂ L ( x k , μ , β ) ∂ x k = 0 k = 1 , 2.... d \left\{ \begin{aligned} &g_i(x) \leq0 & i=1,2.....n\\ &\mu_i \geq0 & i=1,2.....n\\ &\mu_ig_i(x)=0 & i=1,2.....n\\ &h_j(x)=0 &j=1,2.....m\\ &\frac{\partial L(x_k,\mu,\beta)}{\partial x_k}=0 &k=1,2....d \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧gi(x)≤0μi≥0μigi(x)=0hj(x)=0∂xk∂L(xk,μ,β)=0i=1,2.....ni=1,2.....ni=1,2.....nj=1,2.....mk=1,2....d
约束多的可怕,不怕不怕,通过拉格朗日对偶可以转换为非常简介的形式,请查看机器学习——SVM预备知识 拉格朗日对偶推导与证明