结对作业博客
Github 项目地址
https://github.com/AlbertShenC/LongestWordChain
PSP表格估计时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 45 |
| Development | 开发 | ||
| · Analysi | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 60 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 60 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| · Design | · 具体设计 | 120 | 60 |
| · Coding | · 具体编码 | 1200 | 1720 |
| · Code Review | · 代码复审 | 120 | 180 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 270 | 540 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 0 |
| 合计 | 2160 | 2860 |
看教科书和其它资料中关于Information Hiding, Interface Design, Loose Coupling的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的
我们的程序整体上来说分为了四个互相独立,由互相依靠的部分,分别是计算模块Core,图形界面GUI,命令行界面CLI,连接计算模块和GUI,CLI,文件读写的API模块。这几个模块之间的没有全局的数据,运行时也不会直接影响到其他模块,仅通过参数,返回值等方式互相传递数据。实现了高内聚低耦合的思想。
这使得我们可以将整个程序分为以上四个部分分别进行编程和测试,同时在debug时也能够很方便地直接定位到具体是哪一个模块出现了问题。
同时在模块内部,我们也尽力使得其各部分之间实现低耦合。例如API模块,我们将其分为了文件读写,连接功能两个部分。
在编写程序的过程中,逐个编写,逐个测试,使得我们在很早的时候就基本上解决了程序的bug。同时由于提前约定了接口定义,也使得各模块之间的组合基本没有遇到问题。
计算模块接口的设计与实现过程
计算模块最终的函数是get_chain_word()和get_chain_char(),在我的编写代码的过程中,发现这两种情况十分的相似,几乎就是可以当做一种情况来考虑。我们将26个字母视为节点,这样能够一定程度上加快效率。每个节点都要保存最长单词链的长度,一个包含着所有以它为头字母的字母链,以及这个字母的最长链。
整体共使用了一个类以及14个函数。封装时,我们将这些函数分装到了Core类中,并导出Dll。


其主要调用关系如下图。首先判断是否允许环路存在,如果允许不环路存在,就调用get_Chain()函数来处理。如果允许环路存在,就调用get_Chain_With_R()函数来处理。get_Chain()和get_Chain_With_R()都是靠传入的参数来判断是要求单词数还是字符数。进入这两个函数后,对整个图进行初始化,对每个单词,如果判断的是单词数目最多,就将其长度设置为1,否则就将其长度设置为字符数,这样就可以将两种情况统一判断了。初始化后判断单词中是否存在环路,如果不允许环路却出现了环路报异常。然后就开始生成起始节点,然后对每个起始节点开始判断其最长路,最终找出最长链,将其保存在result中。其计算过程就是对每个节点找出其对应的最长链,并将最长链挂在下面,最终就能找到起始节点的最长链。

最重要的函数就是find_Longest_Chain()函数和find_Longest_Chain_With_R()函数。对于find_Longest_Chain()函数,由于没有环路,因此每个字母实际上只需要计算一次,如果发现这个字母已经计算过了,就直接返回它的最长链的长度。如果没计算过,就判断它是不是到达了结尾。如果是结尾,根据可能规定的结尾字母来判断这个字母的最长链长度。

没有被计算过也不是结尾时,就对这个字母下的所有单词的结尾字母都判断一遍,找到里面最长的,最终计算出字母的最长链长度和最长链。
对于find_Longest_Chain_With_R()就稍稍有点区别,因为一个字母可以被多次用到,所以就不能通过判断这个字母是否被计算过来得到它的最长链。我们的做法是,针对每一次递归调用,找到以这个字母为开头,没有在这一层递归调用中判断过,也不在临时的判断路径,也没有被确定下来最终路径的最长单词,在进行递归判断这个单词的尾字母。通过这种方式,能够访问到整个图。同时也不会出现重复访问。
![]()

在每次调用的结束前,都要判断,这次找到的最长路径是否比现在的最长路径长,如果更加长的话,就将新的路径替换掉旧的路径。
![]()
算法的关键之处在于将两种不同的要求合二为一,同时只使用26个字母作为节点,将所有以某个字母为开头的单词全部保存在节点的链表之中,而不是针对大量的单词,以单词作为节点来考虑。
UML图

计算模块接口部分的性能改进
在性能这一块,我们最开始的想法就是单独保存每个单词,将单词视为图中的节点,但是后来发现这样做会导致图太大,临接矩阵的生成就要花费大量的时间,更别说去判断里面是否存在环路了。因此我们考虑26个字母,将字母作为图来看,将以这个字母开头的单词全部保存在链表之中,再来进行判断。由于改进前还没有写的太深,很多重要函数都还没有进行编写,改进的时间花费的不多,两个小时就完成了新的设计。
看Design by Contract, Code Contract的内容:http://en.wikipedia.org/wiki/Design_by_contract,http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx描述这些做法的优缺点, 说明你是如何把它们融入结对作业中的
优点
当许多人一起合作开发一个项目时,对于每一个接口都需要有明确的规定,Design by contract能够极大地降低多人开发时由于接口不统一造成的冲突,减少后续debug的时间。
缺点
当团队规模较小,项目较简单时,Design by contract的意义没有那么明显,反而可能因为花费了太多时间在规格统一上,而降低了总体的效率。如果后期有需求变动,需要对规格进行修改,工作量也较大。
如何融入作业
此次作业我们试图对我们的编程进行规范,例如我们约定了代码风格,同时也在编写API模块时对接口进行了细致的定义,例如输入的要求,返回值的性质,运行过程中可能修改的数据,甚至有哪些需要调用者进行释放的空间。同时,为了降低学习和使用成本,这些内容我们均采用了自然语言进行描述,可能会导致一定程度的不精确。
但在后续的多次修改过程中,尤其是在计算模块中,修改了多处bug,同时也有中途增加新的数据结构,抛弃以前的数据结构等,使得结构变化较为剧烈,所以后期删除了模块内部的接口规范,仅保留了与其他模块相关的接口的明确定义。
应该说我们最后也尝到了忽略规范的苦头,在进行了多次修改后,无论是代码风格还是接口定义都与最开始的约定有了很大区别,甚至也出现在不同的函数中,同一个变量的含义不同的情况,导致程序的可读性很差,所以还花了一部分时间对程序的接口进行优化,从而方便后期的调试和修改。
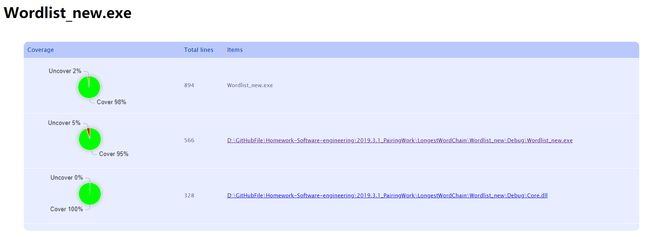
计算模块部分单元测试展示
单元测试覆盖率如下:
部分测试代码展示
TEST_METHOD(RightTest)
{
char * argv_temp[100];
int argc_temp = 7;
ofstream outputFile("temp.txt");
outputFile << "aaa abb bbb bcc ccc cdd";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-h");
argv_temp[3] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[3], "a");
argv_temp[4] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[4], "-t");
argv_temp[5] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[5], "c");
argv_temp[6] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[6], "temp.txt");
string error_message;
Assert::AreEqual((double)kErrorNone,
(double)executiveCommand(argc_temp, argv_temp, true, &error_message));
Assert::AreEqual(error_message.c_str(),
"");
}此样例测试测试最为简单的情况,只有一个方向,且没有分支的。
TEST_METHOD(RightTestWithR)
{
char * argv_temp[100];
int argc_temp = 8;
ofstream outputFile("temp.txt");
outputFile << "aaa abb acc baa bbb bcc caa cbb ccc";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-h");
argv_temp[3] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[3], "a");
argv_temp[4] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[4], "-t");
argv_temp[5] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[5], "c");
argv_temp[6] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[6], "-r");
argv_temp[7] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[7], "temp.txt");
string error_message;
Assert::AreEqual((double)kErrorNone,
(double)executiveCommand(argc_temp, argv_temp, true, &error_message));
Assert::AreEqual(error_message.c_str(),
"");
}此样例较上一样例略复杂一些,为全联通三角形,且为双向
TEST_METHOD(ErrorCirculation)
{
char * argv_temp[100];
int argc_temp = 7;
ofstream outputFile("temp.txt");
outputFile << "aaa abb acc baa bbb bcc caa cbb ccc";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-h");
argv_temp[3] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[3], "a");
argv_temp[4] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[4], "-t");
argv_temp[5] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[5], "c");
argv_temp[6] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[6], "temp.txt");
string error_message;
try {
executiveCommand(argc_temp, argv_temp, true, &error_message);
}
catch (exception &e) {
Assert::AreEqual(e.what(), "Error: Found circulation in words");
}
}此样例为较上述样例少了-r参数,故会抛出异常。
TEST_METHOD(RightTestWithR)
{
char * argv_temp[100];
int argc_temp = 8;
ofstream outputFile("temp.txt");
outputFile << "aaa abb acc bdd bee cff cgg dhh hii";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-h");
argv_temp[3] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[3], "a");
argv_temp[4] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[4], "-t");
argv_temp[5] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[5], "c");
argv_temp[6] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[6], "-r");
argv_temp[7] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[7], "temp.txt");
string error_message;
Assert::AreEqual((double)kErrorNone,
(double)executiveCommand(argc_temp, argv_temp, true, &error_message));
Assert::AreEqual(error_message.c_str(),
"");
}此样例为一个简单的树,只有一个根节点。
TEST_METHOD(RightTestWithR)
{
char * argv_temp[100];
int argc_temp = 8;
ofstream outputFile("temp.txt");
outputFile << "aaa abb acc bdd bee cff cgg dhh hii jkk khh";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-h");
argv_temp[3] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[3], "a");
argv_temp[4] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[4], "-t");
argv_temp[5] = (char*)malloc(sizeof(char) * 2);
strcpy(argv_temp[5], "c");
argv_temp[6] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[6], "-r");
argv_temp[7] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[7], "temp.txt");
string error_message;
Assert::AreEqual((double)kErrorNone,
(double)executiveCommand(argc_temp, argv_temp, true, &error_message));
Assert::AreEqual(error_message.c_str(),
"");
}此样例为稍复杂的树,有多个根节点,一起组成了森林。
计算模块部分异常处理说明
计算模块异常主要分为 部分,一是命令格式错误,例如-w和-c均不存在或均存在,命令参数重复,首尾字符长度不为1等,这些是在接收到命令时就能得出结论的。二是文件相关错误,包括读写错误,也包括读取string时的错误;三是文本错误,例如没有-r指令时却有环路。
对此我们解决办法是当遇到错误时抛出异常,基本格式如下:
std::logic_error ex("Error: Repeated parameter -c");
throw exception(ex);而在CLI或者GUI的模块中,对此异常进行处理,例如:
try{
executiveCommand(argc, argv, true, &result_string);
} catch (exception &e){
cout << e.what() << endl;
system("pause");
return 0;
}此时程序将会停止后续的运行,并显示错误提示信息。
例如-w -c参数同时出现:
// -w -c 参数均出现
TEST_METHOD(CommandParsing_CoexistenceOfWC) {
char * argv_temp[100];
int argc_temp = 4;
ofstream output_file("temp.txt");
output_file.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[2], "-c");
argv_temp[3] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[3], "temp.txt");
string error_message;
try {
executiveCommand(argc_temp, argv_temp, true, &error_message);
}
catch (exception &e) {
Assert::AreEqual(e.what(), "Error: Coexistence of -w and -c");
}
}例如需要读取的文件路径不存在
// 需要读取的文件路径不存在
TEST_METHOD(GetWords_getWordsFromFile_noFile)
{
remove("temp.txt");
GetWords get_words;
Assert::IsFalse(get_words.getWordsFromFile("temp.txt"));
}例如没有-r指令时却有环
// 没有-r指令却有环路
TEST_METHOD(Core_circle_without_r) {
char * argv_temp[100];
int argc_temp = 3;
ofstream outputFile("temp.txt");
outputFile << "abc cba";
outputFile.close();
argv_temp[0] = (char*)malloc(sizeof(char) * 14);
strcpy(argv_temp[0], "WordList.exe");
argv_temp[1] = (char*)malloc(sizeof(char) * 3);
strcpy(argv_temp[1], "-w");
argv_temp[2] = (char*)malloc(sizeof(char) * 10);
strcpy(argv_temp[2], "temp.txt");
string error_message;
try {
executiveCommand(argc_temp, argv_temp, true, &error_message);
}
catch (exception &e) {
Assert::AreEqual(e.what(), "Error: Found circulation in words");
}
}界面模块的详细设计过程
程序的GUI使用Qt进行设计。程序UI如下:
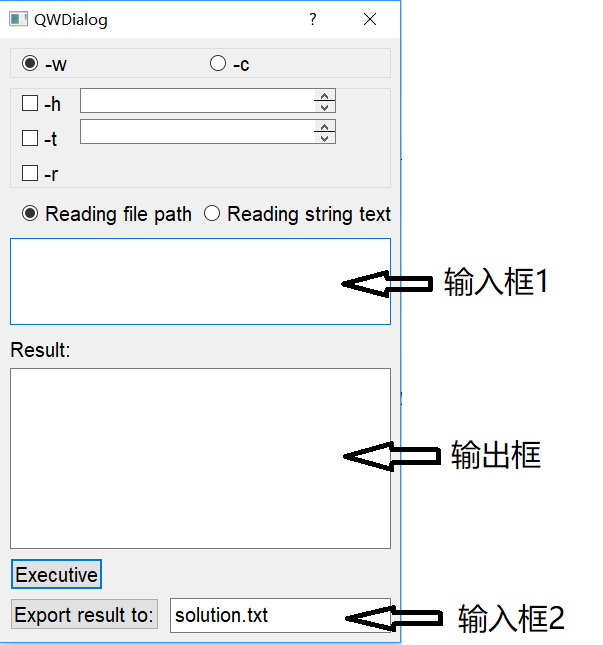
其中-w和-c是单选按钮,-h,-t,-r是复选按钮,若使用-h,-t则需要同时在其对应的输入框中输入相应首尾字母。Reading file path和Reading string text是单选按钮,分别表示从指定文件路径读取文本,或直接输入文本,路径或文本均在输入框1中输入。点击Executive 后将会解析命令,如果执行正确,结果将会显示在输出框中,否则将会弹出错误提示信息。输入框2指定导出文件路径,默认为当前路径下的solution.txt文件,点击Export result to按钮即可将输出框中的内容导出到指定文件。
GUI部分仅涉及界面及相关逻辑,命令解析后的执行均交给API部分执行。GUI的主体部分是QWDialog类,其包含如下变量:

包含如下函数:

界面模块与计算模块的对接
整个程序主要分为3个部分,分别为负责计算的Core模块,负责获取命令的界面模块(分别包括CLI和GUI),负责在两者之间传递数据,解析命令,文件读写的API模块,此部分主要介绍API模块。
API模块主要由两部分组成,第一部分是文件读写部分,第二部分是命令解析部分。
首先是文件读写部分,主要包含于GetWords.h和GetWords.cpp文件中,文件读写部分包含一个类GetWords,包含如下变量:

包含如下函数:

负责从文件中或string中读取并分割单词,返回获取到的单词列表,将指定单词列表输出到指定文件。
然后是命令解析和数据传递部分,主要包含于CommandParsing.h和CommandParsing.cpp文件中,首先其中定义了两个enum,分别用于表示命令和错误代码:


包含一个函数:

参数含义:命令参数列表,命令参数数量,文本来源(即从文件中读取还是直接输入),result_string用于返回字符串形式的错误信息,是否储存至文件(若不储存至文件,result_string将会在正确运行的情况下,储存运行结果),储存结果的文件路径。
executiveCommand函数运行逻辑如下:
首先进行初始化

统计命令参数,此时会对命令的合法性进行检测,例如是否存在重复参数,-w和-c是否均存在或均不存在

如果命令没有语法错误,将会调用GetWords类,计算模块逐步进行 文件读取,分解获得单词列表,计算结果,同时也会对文件是否存在等进行检测
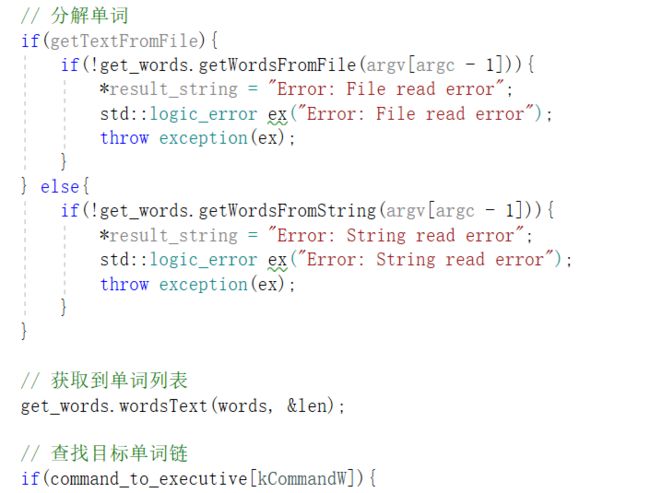
上述步骤均正确后,将结果写入指定文件或返回至调用者
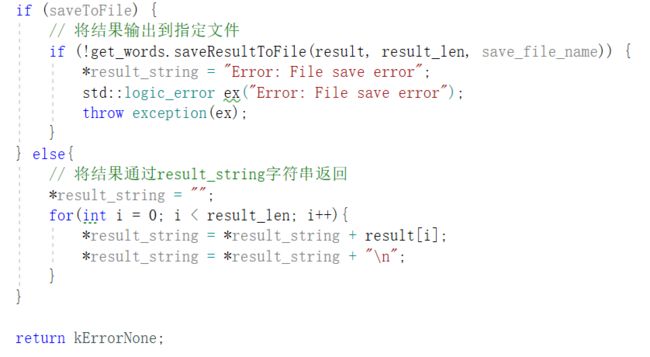
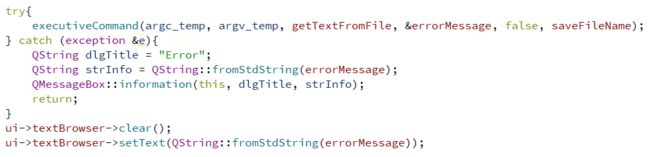
而GUI和CLI则会对调用executiveCommand函数,实现与计算模块的对接,例如:
CLI:

GUI:
结对过程
我们两人结对时间为第二周周五(即3月1日),当天即见面并进行讨论。在后续过程中保持着较高频率的结对编程(两次见面之间的间隔一般不超过2天)。
两人第一次见面时的讨论照片:
说明结对编程的优点和缺点。结对的每一个人的优点和缺点在哪里 (要列出至少三个优点和一个缺点)。
结对编程的优点
- 双方互相监督,会使得对方不敢偷懒。平时一个人编程时,可能会时不时的玩会儿手机,不能长时间的集中精神。
- 及时发现bug。由于双方是一人编程,一人引导,双方视角的不同,思路的不同,能够及早的发现bug并修正,从而减少后期debug的时间花费。
结对编程的缺点
- 如果结对双方不熟悉,可能会导致双方磨合需要花费大量时间,同时由于不熟悉对方的习惯,工作环境等,可能反而会使得工作效率降低
- 时间上难以协调。结对编程要求两人都需要在场,对于现在学生阶段而言,大家的课程生活习惯都不一样,难以找到双方同时有空的时候。
搭档的优点
- 稳扎稳打。在前期考虑如何编写核心的计算代码时,搭档没有急于下手,而是仔细地考虑有哪些优化方法,在编写程序的过程中,我们基本上没有大规模修改过程序的框架。
- 执着。在合作的过程中,搭档从未说过放弃的话,无论程序出现了什么问题,都会耐心的去解决他。
- 编程能力优秀。无论时整体上的算法,还是具体实现时一些小细节,搭档都能想出很多我没想到的点,对于程序整体效率的提高有很大的功劳。
搭档的缺点
- 代码风格不是很好。在合作的过程中,虽然我们开始时约定了代码风格,但在后期写程序的过程中,尤其是debug时,代码风格其实比较混乱,甚至也出现了一些类似于aaa命名的变量。
模块松耦合
交换同学及学号
| 姓名 | 学号 |
|---|---|
| 牛雅哲 | 16131059 |
| 王文珺 | 16061007 |
我们两组均将模块封装为了dll,对方采用的是cmake进行编译,可以使用vs直接打开,故测试时并没有遇到很多问题。
在测试的过程中,我们发现对方没有严格按照作业的要求对接口进行定义,例如输入和输出字符数组,他们采用的是string类,故在调用前,我们需要将界面模块和API模块得到的字符数组拼接成为一个string。而对于控制台输出可以直接采用cout进行输出,而对于文件的输出,由于我们是封装了一个函数进行文件输出,所以需要将string转化为字符数组作为参数进行传递,但本质上没有太大区别。
除此之外,对方的函数比规定多了一个参数,用于具体的返回错误信息,而我们对此采用的是使用throw抛出异常的方式。
在阅读对方的源代码的过程中,我们发现对方定义了大量的自定义结构,枚举,使得代码的可读性较高,哪怕在没有注释的情况下阅读也不会很困难,这一点值得我们学习。