安卓开发笔记(八)—— 王者荣耀英雄大全 数据库部分
中山大学数据科学与计算机学院本科生实验报告
(2018年秋季学期)
ps:如果需要该项目的王者荣耀数据库资源,在下面留言即可
数据库在下面这个GITHUB链接里面,觉得有用的,兄弟给个star谢谢!
数据库
实验代码:传送门:https://github.com/dick20/Android
一、实验题目
期中项目 王者荣耀英雄大全
二、项目实现内容
项目内容
- 一个包括王者荣耀英雄人物头像、称号、名字、位置、生存能力值、攻击伤害值、技能效果值、上手难度值等信息的APP
- 具体细节可以参考http://pvp.qq.com/web201605/herolist.shtml
项目要求
- 王者荣耀英雄人物的增删改查功能。属性包含头像、称号、名字、位置、生存能力值、攻击伤害值、技能效果值、上手难度值等,其中头像是图片
- App启动时初始化包含10个英雄信息(不要求数据库,可以代码定义或xml)
项目扩展(可选)
- 项目拓展部分,同学们可以通过使用相似的应用进行体验后总结优缺点,从而对自己的APP进行改进从而进一步的提升用户体验。
- 参考方向:数据库保存、UI界面美化、背景音乐、提供其他娱乐功能等
三.个人完成部分
1.英雄装备数据的抓取
2.数据导入数据库
3.数据库链接入Android应用
4.Hero,HeroEquip,HeroSkill三个基类的构建
5.数据库提供增删查改的接口API
四、实验结果
(1)实验截图
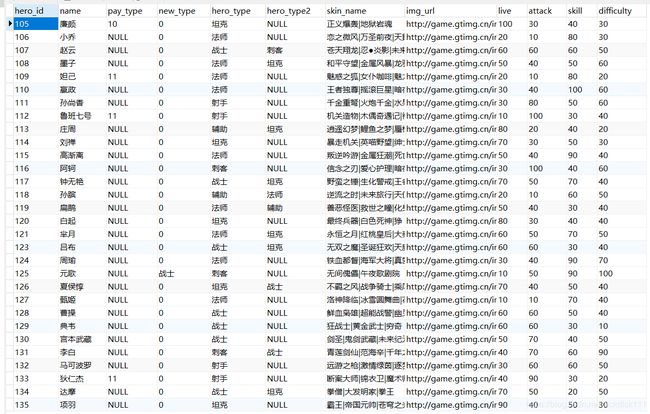
1.数据库的内容展示
英雄数据库
属性包括,英雄id,英雄名字,英雄类型,皮肤名字,头像的url,生存值,攻击值,技能值,难度值
英雄技能数据库
属性包括技能id,该技能所属的英雄id,技能名字,冷却时间,消耗,技能介绍,技能图标url

装备数据库
属性包括装备id,装备名字,装备属性,售价,买价,详情,被动效果,装备图标url

英雄推荐装备数据库
属性包括英雄的id,推荐装备的id号序列,推荐tips的详述

2.数据库目录位置
本次数据库放在assets中,第一次打开应用时导入到用户的手机的内置储存中。
(2)实验步骤以及关键代码
a.根据官网信息爬取英雄装备信息
由于之前并没有系统的学习过py爬虫,这次也没有用到其他开源的工具,只是利用简单的分析html树来用正则表达式来匹配,爬取所需要的信息。
首先要对网页的html构造理解,从下图可以看到我所需要的信息,再来编写正则表达式抓取。

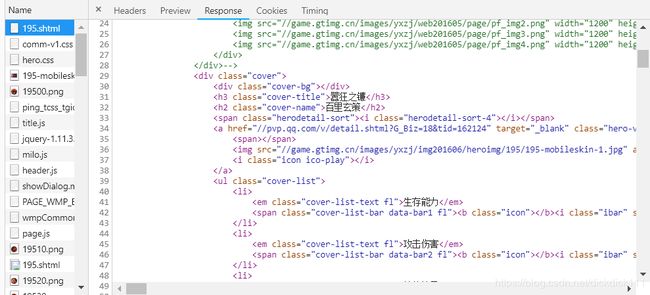
以下取出其中一个例子,获取技能的名字,以及技能的介绍详情。
这是访问英雄个人信息网页来抓取技能信息。
def detail_hero_info(cname,ename):
#访问每个英雄的HTML 注意设置字符编码
url = 'http://pvp.qq.com/web201605/herodetail/{}.shtml'.format(ename)
response = requests.get(url,headers=headers)
response.encoding ='GBK'
if response.status_code == 200:
html = response.text
#将得到的文本传入保存文件函数
save_to_info(html,cname)
else:
return None
正则表达式匹配,然后将它放入items中,最后分割用一个for循环来格式化。最后将获得的一个个技能写入一个txt文件,用于后面搭建数据库。
pattern = re.compile('([\s\S]*?)([\s\S]*?)([\s\S]*?)
\s+([\s\S]*?)
\s+([\s\S]*?)')
items = re.findall(pattern,html)
if not items[-1][0]:
items = items[:-1]
for item in items:
result = item[0] + " " + "技能介绍:" + item[3]
targ = json.dumps(result,ensure_ascii=False)
try:
with open('./images/技能.txt','a',encoding='utf-8') as f:
f.write(targ+' ')
except Exception:
raise
下面是根据英雄列表该网址来进行分析,获取英雄的皮肤,名字,id等信息,判断文件夹中是否已经存在,若没有存在则可以写入。
#获得所有英雄的基本信息的json串
def get_hero_list():
url = 'http://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url, headers=headers)
if response.status_code == 200:
result = json.loads(response.text)
return result
else:
print('爬取失败')
return None
#将每个英雄的代码,姓名等拆分出来
def get_hero_html(info):
ename = info['ename']
cname = info['cname']
skin_name_list = info['skin_name'].split('|')
#获得每个英雄的皮肤数量
skin_num = len(skin_name_list)
#将皮肤数字和英雄代码传入URL 获得图片二进制流
for i in range(1,skin_num+1):
url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg'.format(ename,ename,i)
response = requests.get(url, headers=headers)
if response.status_code ==200:
file = response.content
#判断以英雄命名的文件夹是否存在,并且写入
try:
if not os.path.exists('./images/{}'.format(cname)):
os.makedirs('./images/{}'.format(cname))
else:
with open('./images/{}/{}.jpg'.format(cname, skin_name_list[i - 1]), 'wb') as f:
f.write(file)
except Exception:
raise
else:
print(cname,skin_name_list[i - 1], '图片爬取失败')
detail_hero_info(cname,ename)
b.根据爬取的信息构建数据库
通过py爬虫获取的信息都存储在了txt文件中,这时候要通过txt来导入数据库。根据之前的数据库课程,我已经掌握如何将txt文件导入到MySQL,但是Android内置使用的数据库是SQLite,这里需要一个转化的过程。
这里我使用了Navicat Premium 12这个软件,可以方便将txt文件转化成SQLite数据库内容。
具体操作为,要对txt文件的头部加上相对应的属性,然后它会根据你的属性以及分隔符来构建一条条的英雄资料条目。

然后点击导入即可,按照教程来进行选择。虽然这一过程会出现一些不匹配的情况,大体是因为txt文件的编写格式没有一致,例如缺失某个空格,或者换行情况。所以在导入后要查看一下数据的正确性,然后再修改一下。

c.英雄基类的构建
根据需求,我构建了三个基类,来方便数据库层面的操作。下面分别对他们的属性进行叙述,以下类都是类属性加上构造函数以及get,set函数。
1.Hero类
public class HeroDetail {
private int hero_id; // 英雄的ID
private String name; // 名字
private String position; // 位置
private String skin_name; // 英雄皮肤名字
private String img_url; // 英雄头像图片的url
private String background_url; // 英雄背景url
private String survivability_value; // 生存能力值
private String damage_value; // 攻击伤害值
private String skill_value; // 技能效果值
private String difficulty_value; // 上手难度值
···
}
2.HeroEquip类
public class HeroEquip {
private int hero_id; // 英雄的ID
private int equip_ids1[]; // 建议出装1
private String tips1; // 提示1
private int equip_ids2[]; // 建议出装2
private String tips2; // 提示2
···
}
3.HeroSkill类
public class HeroSkill {
private int skill_id; // 技能的ID
private int hero_id; // 英雄的ID
private String name; // 技能名字
private int cd; // 冷却时间
private int cost; // 消耗
private String description; // 描述
private String tips; // 建议
private String img_url; // 技能图标的URL
···
}
d.Android应用,对于数据库接口的编写
首先,我的数据库包含最初的四个表之外,我新增了collect表,来存储用户收藏的英雄id,实现收藏夹的功能,持久化保存数据。
关于AssetsDatabaseManager,我在下一个模块再进行讨论,这是通过外部文件导入数据库的一个辅助类,这里只是调用其中的接口来获取数据库的位置,然后就可以创建新表collect了。
public class Mydb{
private static final String TABLE_NAME_EQUIP = "equip";
private static final String TABLE_NAME_HERO = "hero";
private static final String TABLE_NAME_HEQUIP = "hero_equip";
private static final String TABLE_NAME_SKILL = "skill";
private static final String TABLE_NAME_COLLECT = "collect"; //用于储存收藏夹的英雄ID
private static final int DB_VERSION = 1;
···
public Mydb(Context context) {
// 初始化,只需要调用一次
AssetsDatabaseManager.initManager(context);
mg = AssetsDatabaseManager.getManager();
db = mg.getDatabase("my_db.db");
String CREATE_TABLE = "CREATE TABLE if not exists "
+ TABLE_NAME_COLLECT
+ " (hero_id INTEGER PRIMARY KEY)";
db.execSQL(CREATE_TABLE);
}
}
对于英雄的查询接口,这里可以通过id,用于详情页面的获取英雄信息,通过id来跳转。
/* 通过搜索英雄ID,返回英雄详情对象,出错则返回空 */
public HeroDetail queryHeroById(int hero_id){
String selection = "hero_id = ?";
String[] selectionArgs = {hero_id+""};
Cursor c = db.query(TABLE_NAME_HERO,null,selection,selectionArgs,null,null,null);
if (c.getCount() == 0 || !c.moveToFirst()){
return null;
}
HeroDetail heroDetail = new HeroDetail(c.getInt(0), c.getString(1), c.getString(4), c.getString(6), c.getString(7),
c.getString(8), c.getString(9), c.getString(10), c.getString(11));
c.close();
return heroDetail;
}
除此之外,还可以根据英雄属性来返回英雄信息的ArrayList,用于分类
/* 通过搜索英雄的位置,返回英雄的ArrayList,用于分类 战士,法师,射手,坦克,刺客,辅助*/
public ArrayList<HeroDetail> queryHeroByPos(String pos){
ArrayList<HeroDetail> heroDetailArrayList = new ArrayList<>();
String selection = "hero_type = ?";
String[] selectionArgs = {pos};
Cursor c = db.query(TABLE_NAME_HERO,null,selection,selectionArgs,null,null,null);
if (c.getCount() == 0 || !c.moveToFirst()){
return null;
}
do{
HeroDetail heroDetail = new HeroDetail(c.getInt(0), c.getString(1), c.getString(4), c.getString(6), c.getString(7),
c.getString(8), c.getString(9), c.getString(10), c.getString(11));
heroDetailArrayList.add(heroDetail);
}
while (!c.moveToNext());
c.close();
return heroDetailArrayList;
}
返回所有英雄的信息,用于主页的列表显示
/* 返回所有英雄,用于主页英雄 */
public ArrayList<HeroDetail> getAllHeros(){
ArrayList<HeroDetail> heroDetailArrayList = new ArrayList<>();
Cursor c = db.query(TABLE_NAME_HERO,null,null,null,null,null,null);
if (c.getCount() == 0 || !c.moveToFirst()){
return null;
}
Log.i("hero_data",c.getCount()+"");
do{
HeroDetail heroDetail = new HeroDetail(c.getInt(0), c.getString(1), c.getString(4), c.getString(6), c.getString(7),
c.getString(8), c.getString(9), c.getString(10), c.getString(11));
heroDetailArrayList.add(heroDetail);
}
while (c.moveToNext());
c.close();
return heroDetailArrayList;
}
而关于英雄技能与英雄相应装备的获取,都是通过英雄的ID来获取的,这里只叙述一个。
/*通过搜索英雄ID,返回英雄技能数组详情,其中包括四个技能*/
public HeroSkill[] querySkillById(int hero_id){
HeroSkill[] heroSkills = new HeroSkill[4];
String selection = "hero_id = ?";
String[] selectionArgs = {hero_id+""};
Cursor c = db.query(TABLE_NAME_SKILL,null,selection,selectionArgs,null,null,null);
if (c.getCount() == 0 || !c.moveToFirst()){
return null;
}
for (int i = 0; i < 4; i++){
heroSkills[i] = new HeroSkill(c.getInt(0), c.getInt(1), c.getString(2), c.getInt(3),
c.getInt(4), c.getString(5), c.getString(6), c.getString(7));
c.moveToNext();
}
c.close();
return heroSkills;
}
下面是对收藏夹的插入,删除,查询的接口,比较简单,仅仅需要操作英雄的id属性即可,后面再根据这个id来解决信息获取的问题。
/* 通过英雄ID向收藏夹表插入英雄的数据 */
public long insertById(int hero_id){
ContentValues values = new ContentValues();
values.put("hero_id",hero_id);
long rid = db.insert(TABLE_NAME_COLLECT,null,values);
return rid;
}
/* 根据英雄ID向收藏夹表删除英雄的数据 */
public int deleteById(int hero_id) {
String whereClause = "hero_id = ?";
String[] whereArgs = {hero_id + ""};
int row = db.delete(TABLE_NAME_COLLECT, whereClause, whereArgs);
return row;
}
/* 通过英雄ID查询收藏夹是否已收藏该英雄 */
public Boolean checkIsCollect(int hero_id) {
String selection = "hero_id = ?";
String[] selectionArgs = {hero_id+""};
Cursor c = db.query(TABLE_NAME_COLLECT,null,selection,selectionArgs,null,null,null);
if (c.getCount() == 0 || !c.moveToFirst()){
return false;
}
c.close();
return true;
}
e.外部数据库导入到手机内部存储
由于这次没有直接在应用中导入数据,而是通过外部的db文件写入到手机中,故要写这样一个manager类来操作。主要功能包括第一次打开应用将数据库写入用户的手机,而后面的打开会先判断数据库是否存在,若已经存在了,则直接获取该路径即可,不需要重复写入。
public class AssetsDatabaseManager {
private static String tag = "AssetsDatabase";
// A mapping from assets database file to SQLiteDatabase object
private Map<String, SQLiteDatabase> databases = new HashMap<String, SQLiteDatabase>();
// Context of application
private Context context = null;
// Singleton Pattern
private static AssetsDatabaseManager mInstance = null;
public static void initManager(Context context){
if(mInstance == null){
mInstance = new AssetsDatabaseManager(context);
}
}
public static AssetsDatabaseManager getManager(){
return mInstance;
}
private AssetsDatabaseManager(Context context){
this.context = context;
}
这里就是获取数据库的函数,实际也是操作SQLiteDatabase,利用其接口来判断以及获取已经存在手机的数据库。
public SQLiteDatabase getDatabase(String dbfile) {
if(databases.get(dbfile) != null){
Log.i(tag, String.format("Return a database copy of %s", dbfile));
return (SQLiteDatabase) databases.get(dbfile);
}
if(context==null)
return null;
Log.i(tag, String.format("Create database %s", dbfile));
String spath = getDatabaseFilepath();
String sfile = getDatabaseFile(dbfile);
File file = new File(sfile);
SharedPreferences dbs = context.getSharedPreferences(AssetsDatabaseManager.class.toString(), 0);
boolean flag = dbs.getBoolean(dbfile, false); // Get Database file flag, if true means this database file was copied and valid
if(!flag || !file.exists()){
file = new File(spath);
if(!file.exists() && !file.mkdirs()){
Log.i(tag, "Create \""+spath+"\" fail!");
return null;
}
if(!copyAssetsToFilesystem(dbfile, sfile)){
Log.i(tag, String.format("Copy %s to %s fail!", dbfile, sfile));
return null;
}
dbs.edit().putBoolean(dbfile, true).commit();
}
SQLiteDatabase db = SQLiteDatabase.openDatabase(sfile, null, SQLiteDatabase.NO_LOCALIZED_COLLATORS);
if(db != null){
databases.put(dbfile, db);
}
return db;
}
下面就到第一次写入数据库的函数,将db文件写入,首先是对读取路径以及写入路径的判断。然后利用文件流来读取并写入,这里采用的是istream以及ostream。
private boolean copyAssetsToFilesystem(String assetsSrc, String des){
Log.i(tag, "Copy "+assetsSrc+" to "+des);
InputStream istream = null;
OutputStream ostream = null;
try{
AssetManager am = context.getAssets();
istream = am.open(assetsSrc);
ostream = new FileOutputStream(des);
byte[] buffer = new byte[1024];
int length;
while ((length = istream.read(buffer))>0){
ostream.write(buffer, 0, length);
}
istream.close();
ostream.close();
}
catch(Exception e){
e.printStackTrace();
try{
if(istream!=null)
istream.close();
if(ostream!=null)
ostream.close();
}
catch(Exception ee){
ee.printStackTrace();
}
return false;
}
return true;
}
(3)实验遇到的困难以及解决思路
a.py爬虫的信息错误
一开始学习爬虫是比较困难的,我也是通过一些简单的例子开始理解。掌握基础的html树的爬取,期间遇到了十分多的问题。对于爬取下来的json格式,我还要进行处理,这里我参考了不少的博客,吸取前人的经验。
我在爬取的时候,忘记判断该英雄是否重复,导致爬下来的内容繁琐,且英雄重复率很高。于是我在写入文件的时候先判断该文件是否已经存在,再进行写入,否则则直接丢弃该数据。
还有就是爬取内容的时候,字符的编码格式没有设置,导致爬下来的都是乱码无法识别具体内容。后来才知道需要在reponse上加上encoding.
response.encoding ='GBK'
b.数据库返回的信息错误
数据库由于表格的属性较多,读取的时候又是通过columnindex来读取,容易出现数字写重复的情况。我是我们小组首先开始工作的,我完成数据库的接口后,必须先自己测试过才上传给他们使用。在测试的过程我就发现有些返回的信息不准确,出现不匹配的情况,这需要回到数据库函数来查看。
HeroDetail heroDetail = new HeroDetail(c.getInt(0), c.getString(1), c.getString(4), c.getString(6), c.getString(7),
c.getString(8), c.getString(9), c.getString(10), c.getString(11));
除此之外,我还需要对数据库中的字符串进行处理,分割装备id的一系列字符串来返回一个int的数组,里面包含装备id。不然直接返回string,不利于详情页面通过id来访问我的装备信息获取接口。
//将string转化为长度为6的int装备id数组 1331,1334,1421,1333,1327,1337
int equip_ids1[] = new int [6];
int equip_ids2[] = new int [6];
String temp1 = c.getString(1);
String temp2 = c.getString(3);
String[] str1, str2;
str1 = temp1.split(",");
str2 = temp2.split(",");
for (int i = 0; i < 6; i++){
equip_ids1[i] = Integer.parseInt(str1[i]);
equip_ids2[i] = Integer.parseInt(str2[i]);
}
HeroEquip heroEquip = new HeroEquip(c.getInt(0), equip_ids1, c.getString(2), equip_ids2, c.getString(4));
c.基类属性不满足详情页面的需要
这个问题需要重新构造基类,由于考虑的疏忽,一开始只提供了英雄的头像,而没有提供英雄的原图导致详情页面的图像非常丑。这时我必须为Hero类提供多一个原图的url。
此时,我的数据库已经不想再改动,而我又发现腾讯主页上的英雄原图与icon的url只是后缀不一样,前面的完全一样。于是,我在Hero新增即可,通过字符串的变化来提高此url。
String temp = img_url.substring(0,img_url.length()-7);
temp += hero_id + "-mobileskin-1.jpg";
this.background_url = temp;
五、实验思考及感想
这次的期中项目是需要团队合作,使用了gitee的功能,我们在之前课程学到sourcetree的功能来进行代码合作。我负责的部分是数据的抓取,数据库的搭建,提供数据库的接口等后台的内容,这对于我来说也是一个挑战,因为在期中项目开始之前,老师还没有讲到有关于数据库的内容。而关于爬虫的抓取更是没有尝试过,我一边学习一边尝试的来一步步构造数据库,其中也是颇有挑战性,做出来后成就感当然也是满满。作为基类的书写,接口的提供必须要根据前端页面的需求,这次我就忽略了一个英雄的背景图url,后面才进行补救。下次一定要在前期就做好计划,不需要东拼西凑的写代码。