理解yolo系列目标检测算法
文章目录
- 1. 目标检测算法发展史
- 2. yolo-v1
- 2.1 动机
- 2.2 优点
- 2.3 inference过程
- 3. yolo-v2
- 3.1 动机
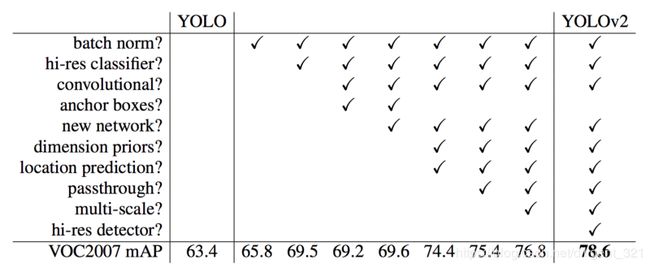
- 3.2 tricks
- 3.3 anchors个数对比
- 3.4 Darknet-19
- 3.5 inference过程
- 3.6 YOLO9000
- 4. yolo-v3
- 4.1 动机
- 4.2 tricks
- 4.3 实验结果
- 5. 结论
- 6. 参考资料
在计算机视觉任务中,如果说做的最成熟的是图像识别领域,那么紧随其后的应该就是目标检测了。笔者接触目标检测也有一段时间了,用mobilenet_ssd算法做过手机端的实时目标检测,也用faster-rcnn做过服务器端的二维码检测,尽管一直都知道yolo的效果也很不错,但没抽出时间细细研究,最近刚好闲出空来,就把yolo系列算法论文细读了一遍,在思考的过程中,也使我对之前的知识点有了新的体会,这里一并记录下来,也希望能对读者有所帮助。
1. 目标检测算法发展史
这几年目标检测方面的文章很多,如果只是单纯地研究其中的某几个算法的话,可能会“一叶障目,不见泰山”,庆幸有网友整理了下面这张非常棒的图,按时间顺序罗列了比较经典的检测算法(附录中有列原图链接)。

说说对已经看过的算法的体会吧,
1) R-CNN,它的全称是"region based CNN",显然,从名字可以看出,这种算法的CNN网络的输入是region。其实,最直接的想法应该是,从输入图像中选取所有尺度的regions,然后分别送到CNN网络中进行训练和测试,这种想法存在的问题是,不同尺度的regions,数量会达到指数级别,所以这种想法是行不通的。R-CNN则是在此基础上进行创新,使用了"selective search"的方法预筛选2k个最可能的regions,然后使用CNN网络提取特征,显然,一般来说,对于一幅图像,2k个目标是足够了的,从而使得CNN做目标检测成为了可能;
2) Fast R-CNN,从名字来看,它比R-CNN更快,快在哪里呢?并不是因为它把2k个regions减少了,而是因为它一次输入一整张图像,相对于R-CNN,它的计算量是原来的1/2k,所以名字上多了一个’Fast’;
3) Faster R-CNN,从名字来看,它比Fast R-CNN更快,那么它又是从什么角度做的优化呢?特征提取网络不变,只是把“ selective search”替换成了RPN。因为“ selective search”非常耗时,而RPN的小网络会比较快,虽然交替训练会直觉上比较困难,但是做inference的时候,整个网络的耗时,相对于改进前提升了10倍以上,所以作者称之“Faster”也当之无愧了,具体的对比数据参见下表,
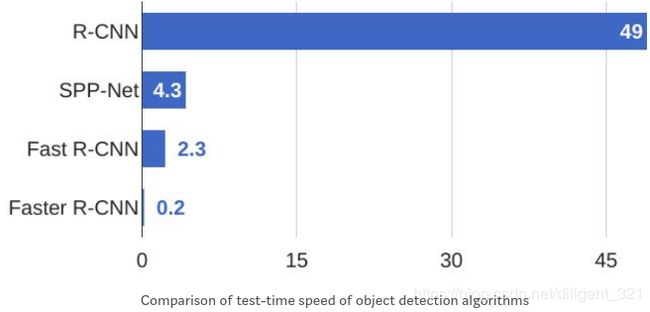
这里顺便提及一下,R-CNN系列算法都属于“two-stage”的目标检测算法,为什么呢?其实,这里指的stage分别是 region proposals 和 prediction,显然,上面的3个方法都是要先生成proposals,然后预测这些proposals对应的边界框和目标类别,所以称之为“two-stage”。而Yolo和ssd算法因为不需要预先生成" region proposals",所以我们称之为“one-stage”的目标检测算法。
2. yolo-v1
2.1 动机
尽管R-CNN系列算法每一版本的优化效果很明显,但是即便是Faster R-CNN也很难满足pc实时性的要求,为了提升算法inference速度,对Faster R-CNN继续改进已经很难了,必须开发一种全新的检测框架。
2.2 优点
a) “end-to-end”:输入一副原始图像,单一网络直接inference出目标位置;
b) Fast,可以满足pc上的实时性要求;
c) 效果鲁棒,从自然图像迁移到艺术等其他领域的图像时,效果也很好。
2.3 inference过程
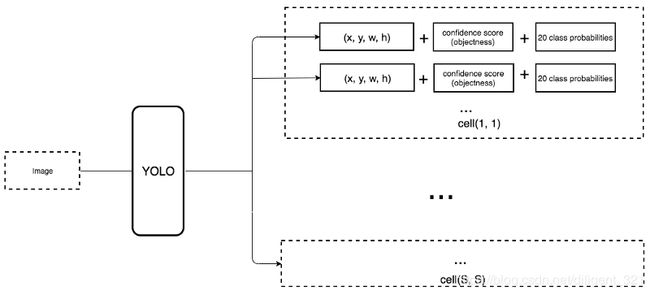
yolo-v1把输入图像划分成了SxS 的网格,显然,每个网格代表了一个图像块,它的作用有两个:(1) 预测一个目标类别标签,(2) 预测出以当前网格为中心的所有可能的bounding boxes和这些boxes对应的打分。显然,前者关注的是当前网格对应的物体的标签,后者关注的是当前网格对应的所有可能物体的位置。为了得到当前网格对应的物体的位置,每个网格的信息会预测出B个bounding boxes。以下图为例进行解释,狗的“center”点落在了第5行第2列的格子上,那么在inference过程中,该网格则负责预测出狗的边框位置,自行车和汽车同理。这里顺便提及一下,如果有一只猫依偎在狗的身旁(这里假设是这样,现实中不太可能哈 ),且猫的"center"点恰好也在这个网格中,那么yolo-v1只会预测出其中的一个目标,而忽略另外一者,这种情况被称为“dense object detection”。
理解了上面的例子,yolo-v1的整个inference过程就很好理解了,引用一下论文中给出的网络结构图,
给定任意一副输入图像,网络会先缩放到448x448的尺寸大小,然后经过中间的特征提取之后,最终得到7x7x30 的特征图,特征图的空间维度为7x7,每个像素对应着原图中的局部感受野,等价于将原图切分成了7x7的网格图,通道维度为什么是30呢?上文中提到,每个网格的信息会预测出B个bounding boxes,论文中取B=2,pascal voc检测数据集的类别数为20,所以通道维度为2*(4+1) + 20 = 30。
在inference阶段,每个网格会预测出B个bounding boxes,然后经过两步后处理得到最终的检测框,步骤一:设置阈值,只保留类概率高于阈值的bounding boxes,步骤二:nms去除重复的bounding boxes。
3. yolo-v2
3.1 动机
面对SSD的横空出世,上一代yolo处于劣势,为了在提升模型速度的同时,进一步提升效果,作者推出了第二代yolo结构,即yolo-v2。
3.2 tricks
在这一版中,Redmon使用了一些策略(包括自创和别人的),来提升模型效果,概括如下,
(1)在卷积层增加batch normalization,删除dropout层,mAP提升了2%;
(2)使用高分辨率的分类backbone。Yolo先用224x224的输入图像优化预训练模型参数,然后用448x448的输入图像finetune整个目标检测网络。而yolo-v2在预训练模型的基础上,先用448x448的输入图像finetune分类网络,再用448x448的输入图像finetune整个目标检测网络,mAP提升了4%;
(3)借鉴faster rcnn中的anchor boxes思想。yolo直接学习bounding box的四个点坐标,模型不好收敛。根据先验知识,通常目标检测任务中要学习的目标的尺寸都是确定的,不是随意的,所以引入anchor的概念有助于收敛。mAP从69.5降为69.2,recall从81%升为88%,也即“even the accuracy is slightly decreased but it increases the chances of detecting all the ground truth objects”。
(4)使用卷积层替换yolo中的全连接层;
(5)Fine-Grained Features,14x14的特征图已经丢失了细节的信息,所以基于该特征图识别小的目标,效果并不好,为了解决这个问题,作者采用了"passthrough"连接,即将不同尺度的特征在channel维度上进行concate,图结构如下,
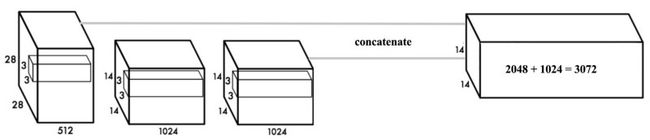
(6)Anchors尺寸聚类。根据经验可知,在常见的目标检测任务中,ground truth boxes的尺寸并不是任意的,而是有规律的,往往只有固定的几种长宽比尺寸。为了使先验Anchors能尽可能好地覆盖训练集图片中的ground truth boxes,需要使用如k-means之类的聚类算法,对ground truth boxes做聚类。因为具体任务中对大目标和小目标一视同仁,赋予相同的权重,所以不能使用点坐标的欧式距离来衡量,而是应该使用IoU,图形解释可以参见右下图,

(7)Multi-Scale Training,因为yolo-v2去除了全连接结构,所以可以输入不同尺寸的图像,训练过程中输入不同分辨率的图像batch,等价于数据增强,使模型效果更鲁棒。
原论文中给出了效果提升的总结图,非常形象,最终的效果,在VOC2007测试集上,速度和精度同时碾压SSD512和Faster R-CNN。
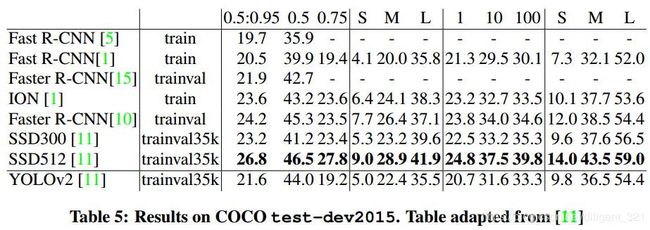
在COCO数据集上,yolo-v2的效果略显逊色,具体的对比指标如下,
3.3 anchors个数对比
(1)Yolo网络:每个像素预测2个bounding box,因此总共有7x7x2=98个boxes;
(2)yolo-v2网络:boxes个数大于1000。
3.4 Darknet-19
在yolo-v2之前,大多数检测算法使用VGG-16网络作为backbone,yolo的backbone为Googlenet网络,Googlenet虽然比VGG-16快,但是在imagenet上的精度低于VGG-16。在yolo-v2中,作者提出了新的backbone,命名为Darknet-19,它的速度和精度均超过VGG-16,使用新的backbone,yolo-v2的网络结构图如下,

3.5 inference过程
在yolo中,每一个预测的bounding box对应一组坐标(x, y, w, h)和二分类打分confidence score(objectness),每一个grid对应不同类别物体的打分,比如VOC数据集,则为20个class probabilities。在yolo-v2中有所不同,每一个预测的bounding box对应一组坐标(x, y, w, h)和二分类打分confidence score(objectness)和不同类别物体的打分,也即“move the class prediction from the cell level to the boundary box level”。读者可能会观察到,同SSD相比,yolo-v2的输出多了一个confidence score,说一点个人的理解,这里是借鉴了faster rcnn的思想,后者在RPN阶段输出一组坐标(x, y, w, h)和二分类打分confidence score,在第二阶段输出精修后的坐标(x, y, w, h)和不同类别物体的打分。yolo-v2作为单阶段的检测算法,把这3个结果同时输出。
3.6 YOLO9000
目标检测任务,由于标注的工作量较大,所以常见的公开数据集中目标类别数较少,比如VOC数据集有20类目标,coco数据集也只有80类目标。作者在本文中,创造性地结合了coco数据集和imagenet数据集训练模型的参数,从imagenet数据集中取了top-9000的类别,这里需要说明一下,Imagenet数据集有2.2w个类别,而图像分类公开赛ISLVRC使用的数据只是Imagenet的子集,为1000个类别。关于分类和检测数据集的组合具体细节,可以参看原论文。
4. yolo-v3
4.1 动机
近几年,目标检测的算法发展的非常快,新的目标检测算法RetinaNet已然超越了yolo-v2,为了进一步提升yolo系列算法的效果,作者推出了第三代yolo结构,即yolo-v3。
4.2 tricks
同Yolo-v2相比,在这一版中,Redmon做了如下改动,来提升模型效果,概括如下,
(1)class prediction。考虑到不同的标签之间可能会有交叠,比如行人和小孩两个标签,因此修改了softmax分类函数为多标签分类函数multi-sigmoid;
(2)引入其他作者提出的FPN结构。浅层feature map包含更多的细粒度信息,深层feature map包含更多的语义信息,通过组合细粒度信息和语义信息,模型对小目标也识别的更好;
(3)backbone。新的特征提取器,Darknet53;
4.3 实验结果
Pasval VOC数据集的评测指标是取阈值为0.5对应的mAP,数学符号为[email protected]。而对于COCO数据集的评测指标,数学符号为AP@[.5:.95],“AP is the average over 10 IoU levels on 80 categories (AP@[.50:.05:.95]: start from 0.5 to 0.95 with a step size of 0.05)”。
如果使用新的指标,也即AP@[.5:.95],yolo-v3超越SSD513,但不如Retinanet效果好,参见下图1。如果使用旧的目标检测指标,也即单单只看[email protected],yolo-v3在速度和精度上完胜SSD513和Retinanet,参见下图2。
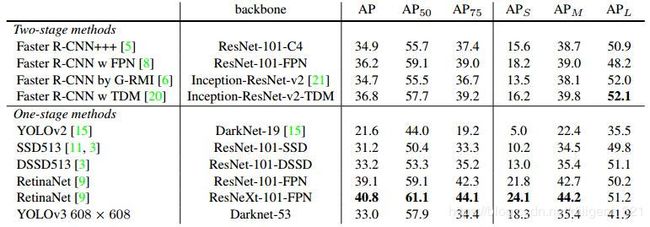
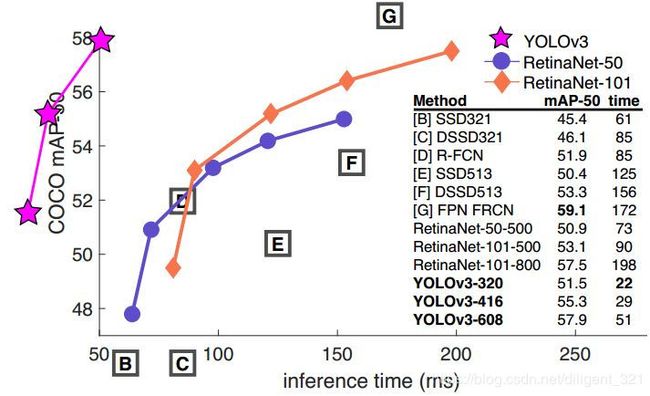
原因解释:正如论文中提到的那样,yolo-v3在IoU阈值增加时,性能指标AP会下降,其实之前的yolo-v2也有这个问题,这一点可以从上面的Table 5看出来,所以导致了[email protected]指标优于Retinanet,而AP@[.5:.95]低于Retinanet。
5. 结论
(1)精度:对于IoU要求不是很高的任务,比如王者荣耀中的目标检测,IoU>0.5就能满足后面的策略算法的要求,可以考虑使用yolo-v3,而不是SSD和Retinanet;
(2)速度:yolo-v3速度是SSD的3倍,是Retinanet的3.8倍;
(3)内存:yolo-v3模型的大小高于SSD,所以在移动端部署时,要考虑内存的限制;
6. 参考资料
https://medium.com/@jonathan_hui/real-time-object-detection-with-yolo-yolov2-28b1b93e2088(总结了yolo、yolo-v2和yolo-v3)
https://arxiv.org/abs/1506.02640(yolo)
https://arxiv.org/abs/1612.08242(yolo-v2)
https://arxiv.org/abs/1804.02767(yolo-v3)
https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
https://github.com/hoya012/deep_learning_object_detection
https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
https://github.com/rafaelpadilla/Object-Detection-Metrics#precision-x-recall-curve(解释了目标检测指标,超赞!!!)