关于IO
IO包:所谓IO,也就是Input与Output的缩写
Java.io包提供了用于系统的输入和输出,通过数据流,序列化和文件系统。I就是input输入,O就是output输出,在一起基本就是输入输出设备。
file.exists() —— 判断该文件是否存在
file.createNewFile() —— 创建文件
file.mkdir(); ——创建文件夹
流是一组流动的数据的总称。类似于水流流是有方向性的。我们应该以当前程序为参照物。如果说是程序中要获得外面的数据,那么我们应该使用输入流,如果由程序向外面扔数据就应该是输出流。
FileInputStream:read方法是一次读一个字节,返回值是这个读到字节的ascii码值,read(byte[])是相当于给一个容器,没有都去填充这个容器,它的返回值是容器中有效字节的个数。
FileOutputStream:write(int)一次写一个字节的ascii码值,write(byte[],起始位置,长度)表示从字节数组的开始位置写多长。
序列化和反序列化ObjectOutputStream(implements Serializable):序列化是将对象状态转换为可保持或传输的格式的过程。反序列化是将流转换为对象,这两个过程结合起来,可以轻松地存储和传输数据。
FileReader:用来读取字符文件的便捷类
FileWriter:用来写入字符文件的便捷类
BufferedReader:缓冲字符输入流 读
BufferedWriter:缓冲字符输出流 写
根据流的类型:字节流,字符流(操作文本文件)
所有以Stream结尾的都是字节流
所有以Reader或者Writer结尾的都是字符流:将字节流转换成字符流。
了解了这么多理论知识,不妨我们来实践一下吧!

首先我们得需要一个文件路径,然后判断该文件是否已经存在,如果不存在 —— 就创建一个文件。并且写入内容

如果该文件已存在,就提示用户 —— 文件存在,并且将文件内容读出来。
那么我们怎么将IO结合递归使用呢???
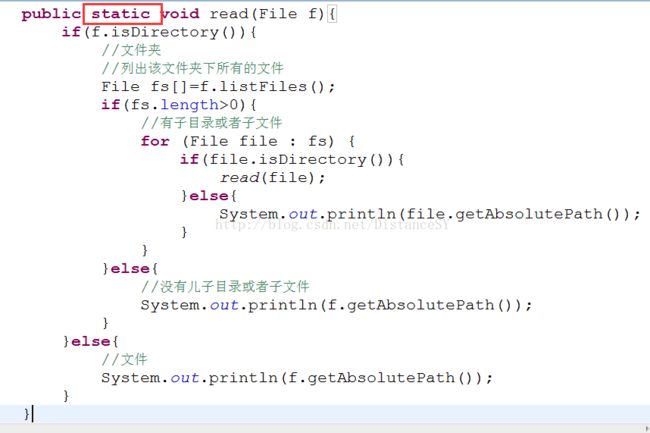
首先,我们要写个方法,注意 —— 这个方法必须是静态的方法
然后列出这个文件夹下所有的文件,再判断如果长度大于0代表有子文件夹,再循环遍历,再进行判断是否有子文件夹,没有就打印出来。如果该文件夹长度小于0,代表没有子文件夹,则可以直接打印。

直接写文件夹路径,调用方法就OK了。
最后再让我们看看多线程下载吧~~
可以理解为下载的通道,一个线程就是一个文件的下载通道,多线程也就是同时开启好几个下载通道。通俗一点说,如果一个人干活要干三天,那么多叫两个人,三个人干活也就只要一天,就是这个原理!
好了~~ 就这么多了,欢迎大家补充!