convolution卷积
卷积
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更恰当的解释是,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
-----------------------------------分割线--------------------------------------------
理解深度学习中的卷积
By 转载2017年3月28日 17:40
译者按:本文译自 Tim Dettmers 的 Understanding Convolution in Deep Learning。有太多的公开课、教程在反复传颂卷积神经网络的好,却都没有讲什么是「卷积」,似乎默认所有读者都有相关基础。这篇外文既友好又深入,所以翻译了过来。文章高级部分通过流体力学量子力学等解释卷积的做法在我看来有点激进,这些领域恐怕比卷积更深奥,所以只需简略看看即可。以下是正文:
卷积现在可能是深度学习中最重要的概念。正是靠着卷积和卷积神经网络,深度学习才超越了几乎其他所有的机器学习手段。但卷积为什么如此强大?它的原理是什么?在这篇博客中我将讲解卷积及相关概念,帮助你彻底地理解它。
网络上已经有不少博客讲解卷积和深度学习中的卷积,但我发现它们都一上来就加入了太多不必要的数学细节,艰深晦涩,不利于理解主旨。这篇博客虽然也有很多数学细节,但我会以可视化的方式一步步展示它们,确保每个人都可以理解。文章第一部分旨在帮助读者理解卷积的概念和深度学习中的卷积网络。第二部分引入了一些高级的概念,旨在帮助深度学习方向的研究者和高级玩家进一步加深对卷积的理解。
第一部分:什么是卷积
整篇博客都会探讨这个问题,但先把握行文脉络会很有帮助。那么粗略来讲,什么是卷积呢?
你可以把卷积想象成一种混合信息的手段。想象一下装满信息的两个桶,我们把它们倒入一个桶中并且通过某种规则搅拌搅拌。也就是说卷积是一种混合两种信息的流程。
卷积也可以形式化地描述,事实上,它就是一种数学运算,跟减加乘除没有本质的区别。虽然这种运算本身很复杂,但它非常有助于简化更复杂的表达式。在物理和工程上,卷积被广泛地用于化简等式——等会儿简单地形式化描述卷积之后——我们将把这些领域的思想和深度学习联系起来,以加深对卷积的理解。但现在我们先从实用的角度理解卷积。
我们如何对图像应用卷积
当我们在图像上应用卷积时,我们在两个维度上执行卷积——水平和竖直方向。我们混合两桶信息:第一桶是输入的图像,由三个矩阵构成——RGB 三通道,其中每个元素都是 0 到 255 之间的一个整数。第二个桶是卷积核(kernel),单个浮点数矩阵。可以将卷积核的大小和模式想象成一个搅拌图像的方法。卷积核的输出是一幅修改后的图像,在深度学习中经常被称作 feature map。对每个颜色通道都有一个 feature map。

边缘检测卷积核的效果
这是怎么做到的呢,我们现在演示一下如何通过卷积来混合这两种信息。一种方法是从输入图片中取出一个与卷积核大小相同的区块——这里假设图片为 100×100,卷积核大小为 3×3,那么我们取出的区块大小就是 3×3——然后对每对相同位置的元素执行乘法后求和(不同于矩阵乘法,却类似向量内积,这里是两个相同大小的矩阵的「点乘」)。乘积的和就生成了 feature map 中的一个像素。当一个像素计算完毕后,移动一个像素取下一个区块执行相同的运算。当无法再移动取得新区块的时候对 feature map 的计算就结束了。这个流程可以用如下的动画演示:
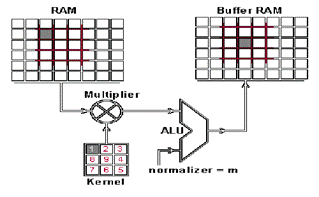
RAM 是输入图片,Buffer 是 feature map
你可能注意到这里有个正规化因子 m,这里 m 的值为 kernel 的大小 9;这是为了保证输入图像和 feature map 的亮度相同。
为什么机器学习中图像卷积有用
图像中可能含有很多我们不关心的噪音。一个好例子是我和 Jannek Thomas 在 Burda Bootcamp 做的项目。Burda Bootcamp 是一个让学生像黑客马拉松一样在非常短的时间内创造技术风暴的实验室。与 9 名同事一起,我们在 2 个月内做了 11 个产品出来。其中之一是针对时尚图像用深度编码器做的搜索引擎:你上传一幅时尚服饰的图片,编码器自动找出款式类似的服饰。
如果你想要区分衣服的式样,那么衣服的颜色就不那么重要了;另外像商标之类的细节也不那么重要。最重要的可能是衣服的外形。一般来讲,女装衬衫的形状与衬衣、夹克和裤子的外观非常不同。如果我们过滤掉这些多余的噪音,那我们的算法就不会因颜色、商标之类的细节分心了。我们可以通过卷积轻松地实现这项处理。
我的同事 Jannek Thomas 通过索贝尔边缘检测滤波器(与上上一幅图类似)去掉了图像中除了边缘之外的所有信息——这也是为什么卷积应用经常被称作滤波而卷积核经常被称作滤波器(更准确的定义在下面)的原因。由边缘检测滤波器生成的 feature map 对区分衣服类型非常有用,因为只有外形信息被保留下来。

彩图的左上角是搜索 query,其他是搜索结果,你会发现自动编码器真的只关注衣服的外形,而不是颜色。
再进一步:有许多不同的核可以产生多种 feature map,比如锐化图像(强调细节),或者模糊图像(减少细节),并且每个 feature map 都可能帮助算法做出决策(一些细节,比如衣服上有 3 个纽扣而不是两个,可能可以区分一些服饰)。
使用这种手段——读入输入、变换输入、然后把 feature map 喂给某个算法——被称为特征工程。特征工程非常难,很少有资料帮你上手。造成的结果是,很少有人能熟练地在多个领域应用特征工程。特征工程是——纯手工——也是 Kaggle 比赛中最重要的技能。特征工程这么难的原因是,对每种数据每种问题,有用的特征都是不同的:图像类任务的特征可能对时序类任务不起作用;即使两个任务都是图像类的,也很难找出相同的有效特征,因为视待识别的物体的不同,有用的特征也不同。这非常依赖经验。
所以特征工程对新手来讲特别困难。不过对图像而言,是否可以利用卷积核自动找出某个任务中最适合的特征?
进入卷积神经网络
卷积神经网络就是干这个的。不同于刚才使用固定数字的卷积核,我们赋予参数给这些核,参数将在数据上得到训练。随着卷积神经网络的训练,这些卷积核为了得到有用信息,在图像或 feature map 上的过滤工作会变得越来越好。这个过程是自动的,称作特征学习。特征学习自动适配新的任务:我们只需在新数据上训练一下自动找出新的过滤器就行了。这是卷积神经网络如此强大的原因——不需要繁重的特征工程了!
通常卷积神经网络并不学习单一的核,而是同时学习多层级的多个核。比如一个 32x16x16 的核用到 256×256 的图像上去会产生 32 个 241×241(latex.png)的 feature map。所以自动地得到了 32 个有用的新特征。这些特征可以作为下个核的输入。一旦学习到了多级特征,我们简单地将它们传给一个全连接的简单的神经网络,由它完成分类。这就是在概念上理解卷积神经网络所需的全部知识了(池化也是个重要的主题,但还是在另一篇博客中讲吧)。
第二部分:高级概念
我们现在对卷积有了一个良好的初步认识,也知道了卷积神经网络在干什么、为什么它如此强大。现在让我们深入了解一下卷积运算中到底发生了什么。我们将认识到刚才对卷积的讲解是粗浅的,并且这里有更优雅的解释。通过深入理解,我们可以理解卷积的本质并将其应用到许多不同的数据上去。万事开头难,第一步是理解卷积原理。
卷积定理
要理解卷积,不得不提 convolution theorem,它将时域和空域上的复杂卷积对应到了频域中的元素间简单的乘积。这个定理非常强大,在许多科学领域中得到了广泛应用。卷积定理也是快速傅里叶变换算法被称为 20 世纪最重要的算法之一的一个原因。
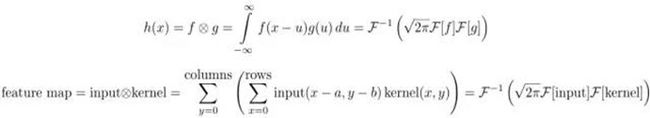
第一个等式是一维连续域上两个连续函数的卷积;第二个等式是二维离散域(图像)上的卷积。这里![]() 指的是卷积,
指的是卷积,![]() 指的是傅里叶变换,
指的是傅里叶变换,![]() 表示傅里叶逆变换,
表示傅里叶逆变换,![]() 是一个正规化常量。这里的「离散」指的是数据由有限个变量构成(像素);一维指的是数据是一维的(时间),图像则是二维的,视频则是三维的。
是一个正规化常量。这里的「离散」指的是数据由有限个变量构成(像素);一维指的是数据是一维的(时间),图像则是二维的,视频则是三维的。
为了更好地理解卷积定理,我们还需要理解数字图像处理中的傅里叶变换。
快速傅里叶变换
快速傅里叶变换是一种将时域和空域中的数据转换到频域上去的算法。傅里叶变换用一些正弦和余弦波的和来表示原函数。必须注意的是,傅里叶变换一般涉及到复数,也就是说一个实数被变换为一个具有实部和虚部的复数。通常虚部只在一部分领域有用,比如将频域变换回到时域和空域上;而在这篇博客里会被忽略掉。你可以在下面看到一个信号(一个以时间为参数的有周期的函数通常称为信号)是如何被傅里叶变换的:
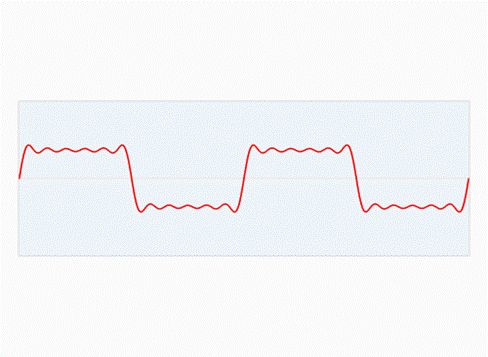
红色是时域,蓝色为频域
你也许会说从没见过这些东西,但我敢肯定你在生活中是见过的:如果红色是一首音乐的话,那么蓝色值就是你在你的 MP3 播放器屏幕上看到的频谱:

傅里叶域上的图像

我们如何想象图片的频率呢?想象一张只有两种模式的纸片,现在把纸片竖起来顺着线条的方向看过去,就会看到一个一个的亮点。这些以一定间隔分割黑白部分的波就代表着频率。在频域中,低频率更接近中央而高频率更接近边缘。频域中高强度(亮度、白色)的位置代表着原始图像亮度改变的方向。这一点在接下来这张图与其对数傅里叶变换(对傅里叶变换的实部取对数,这样可以减小像素亮度的差别,便于观察更广的亮度区域)中特别明显:

我们马上就可以发现傅里叶变换包含了关于物体朝向的信息。如果物体被旋转了一个角度,从图像像素上可能很难判断,但从频域上可以很明显地看出来。
这是个很重要的启发,基于傅里叶定理,我们知道卷积神经网络在频域上检测图像并且捕捉到了物体的方向信息。于是卷积神经网络就比传统算法更擅长处理旋转后的图像(虽然还是比不上人类)。
频率过滤与卷积
为什么卷积经常被描述为过滤,为什么卷积核经常被称为过滤器呢?通过下一个例子可以解释:

如果我们对图像执行傅里叶变换,并且乘以一个圆形(背景填充黑色,也就是 0),我们可以过滤掉所有的高频值(它们会成为 0,因为填充是 0)。注意过滤后的图像依然有条纹模式,但图像质量下降了很多——这就是 jpeg 压缩算法的工作原理(虽然有些不同但用了类似的变换),我们变换图形,然后只保留部分频率,最后将其逆变换为二维图片;压缩率就是黑色背景与圆圈的比率。
我们现在将圆圈想象为一个卷积核,然后就有了完整的卷积过程——就像在卷积神经网络中看到的那样。要稳定快速地执行傅里叶变换还需要许多技巧,但这就是基本理念了。
现在我们已经理解了卷积定理和傅里叶变换,我们可以将这些理念应用到其他科学领域,以加强我们对深度学习中的卷积的理解。
总结
这篇博客中我们知道了卷积是什么、为什么在深度学习中这么有用。图片区块的解释很容易理解和计算,但有其理论局限性。我们通过学习傅里叶变换知道傅里叶变换后的时域上有很多关于物体朝向的信息。通过强大的卷积定理我们理解了卷积是一种在像素间的信息流动。之后我们拓展了量子力学中传播子的概念,得到了一个确定过程中的随机解释。我们展示了互相关与卷积的相似性,并且卷积网络的性能可能是基于 feature map 间的互相关程度的,互相关程度是通过卷积校验的。最后我们将卷积与两种统计模型关联了起来。
个人来讲,我觉得写这篇博客很有趣。曾经很长一段时间我都觉得本科的数学和统计课是浪费时间,因为它们太不实用了(哪怕是应用数学)。但之后——就像突然中大奖一样——这些知识都相互串起来了并且带了新的理解。我觉得这是个绝妙的例子,启示我们应该耐心地学习所有的大学课程——哪怕它们一开始看起来没有用。
Reference
http://timdettmers.com/2015/03/26/convolution-deep-learning/
R. B. Fisher, K. Koryllos,「Interactive Textbooks; Embedding Image Processing Operator Demonstrations in Text」, Int. J. of Pattern Recognition and Artificial Intelligence, Vol 12, No 8, pp 1095-1123, 1998.
原英文链接:http://timdettmers.com/2015/03/26/convolution-deep-learning/
码农场该文章链接:http://www.hankcs.com/ml/understanding-the-convolution-in-deep-learning.html